一.核心思想
把HQL当做MapReduce程序去优化。
注意,以下SQL不会转为MapReduce执行:
1.select仅查询本表字段。
2.where仅对本表字段做条件过滤。
二.启动Hive
备注:Hive依赖Zookeeper和HDFS,因此需要先开启!
三.Explain
Explain显示执行计划,Explain [EXTENDED] query
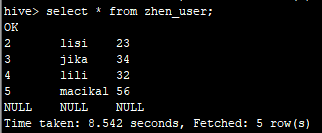
1.普通查询,不执行mapreduce任务
1.1.普通查询
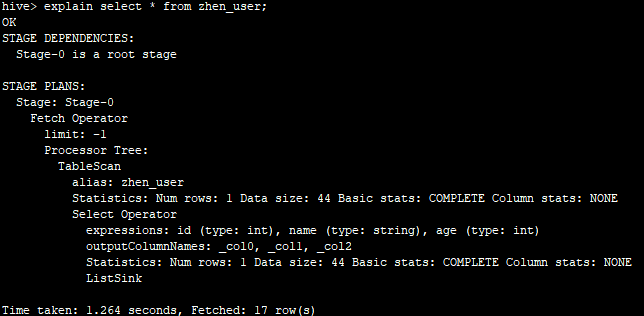
1.2.不带EXTENDED的Explain
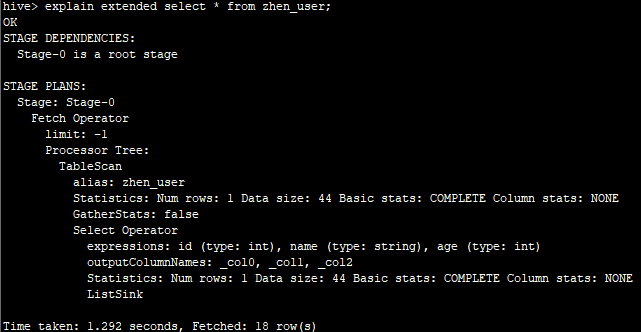
1.3.带EXTENDED的Explain
2.执行count(*),执行mapreduce
2.1 普通查询
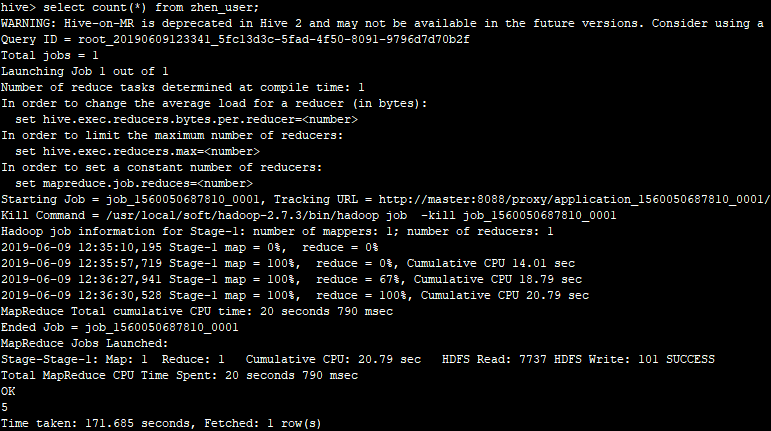
2.2不带EXTENDED的Explain
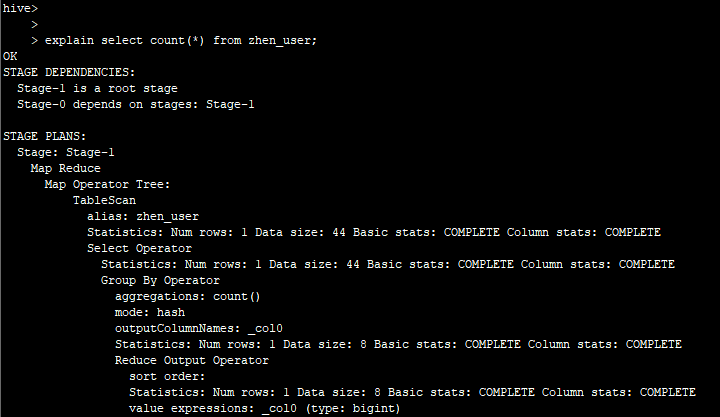

2.3带EXTENDED的Explain
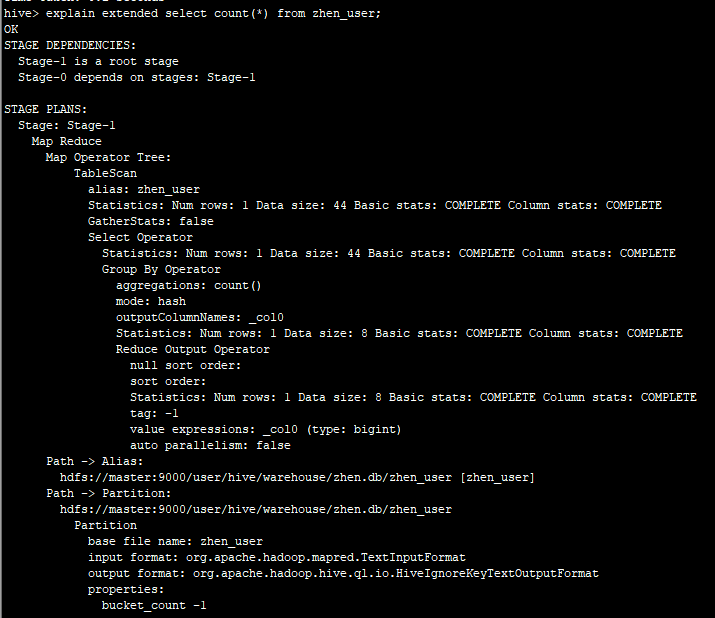
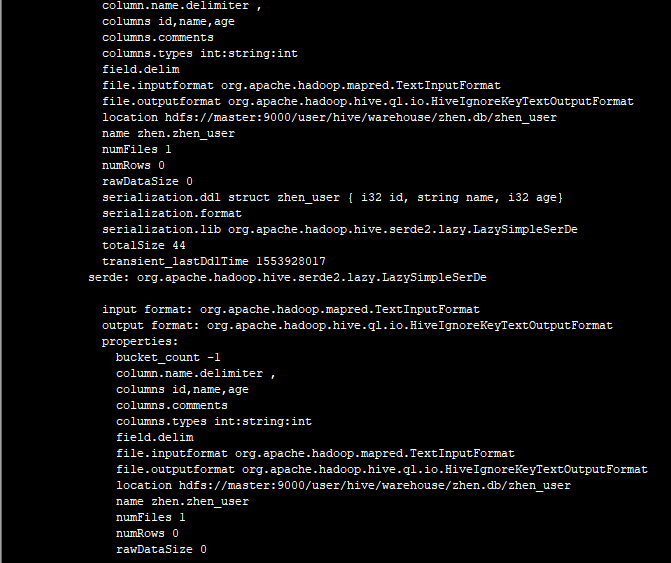
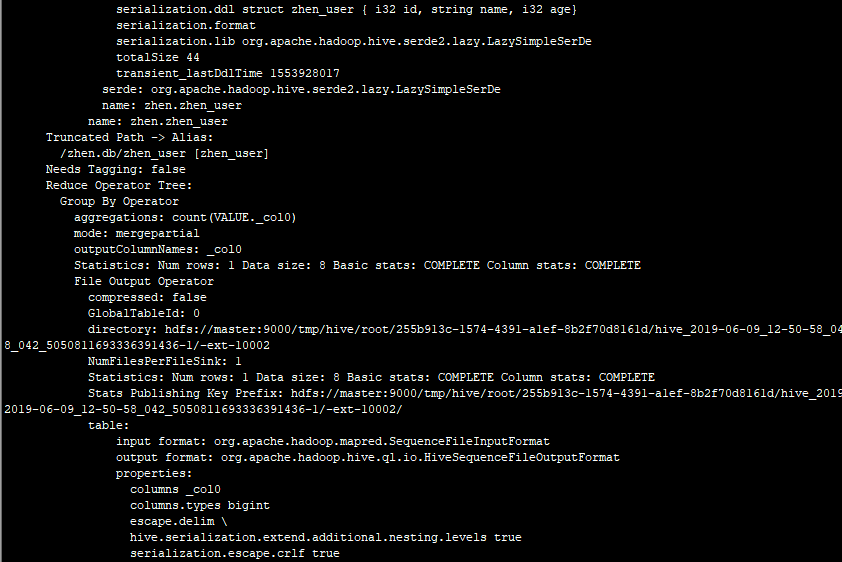
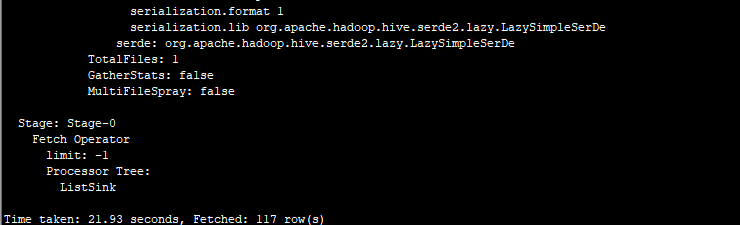
四.Hive运行模式
1.本地模式
1.查看默认配置

默认为集群模式。
2.设置本地模式

3.查看设置成本地模式后对查询性能的影响
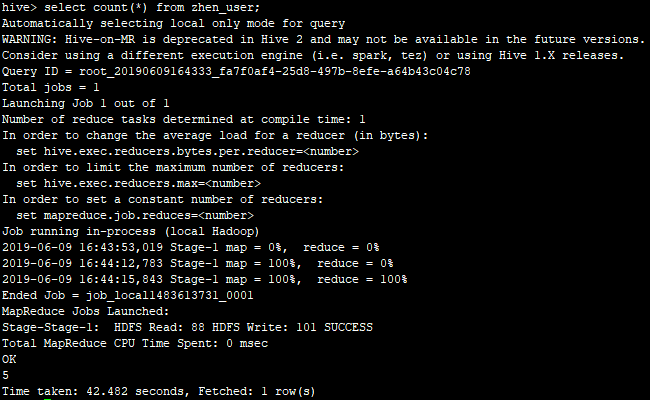
注意:
1.与2.1普通查询比较,速度提升4倍左右,一般仅适用于本地测试!
2.hive.exec.mode.local.auto.inputbytes.max默认值为128M,表示加载文件的最大值,若大于该配置仍会以集群模式运行。
2.集群模式
五.并行计算
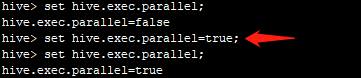
通过设置以下参数开启并行计算模式:set hive.exec.parallel=true;
注意:
1.hive.exec.parallel.thread.number【一次SQL计算中运行并行执行的job个数的最大值】
2.需要提前关闭本地模式。
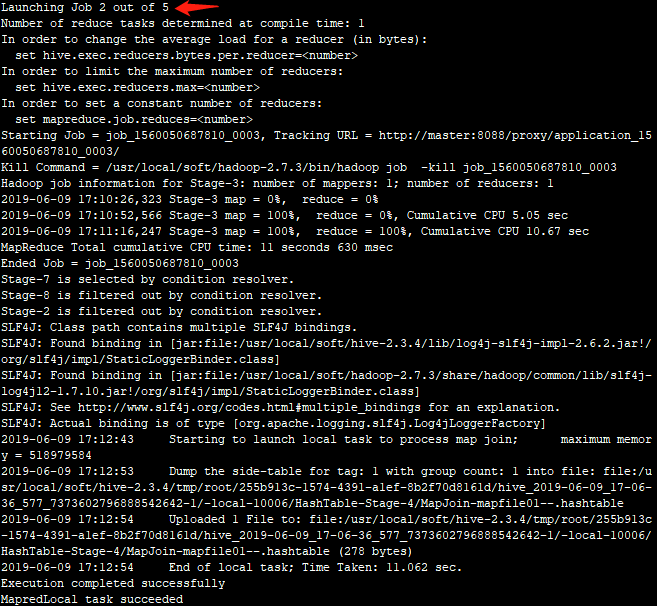
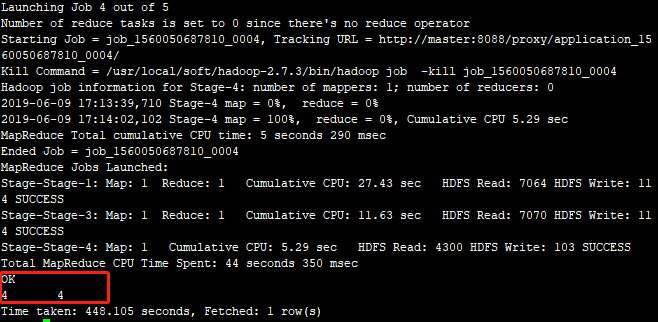
1.默认情况,关闭本地模式:

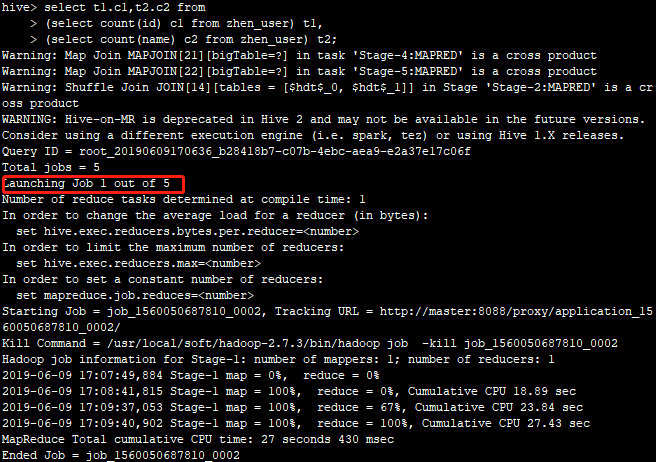
2.开启并行计算
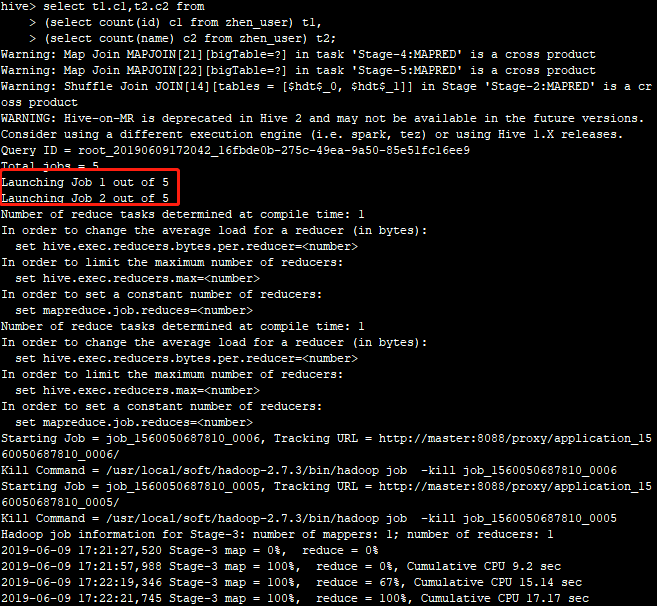
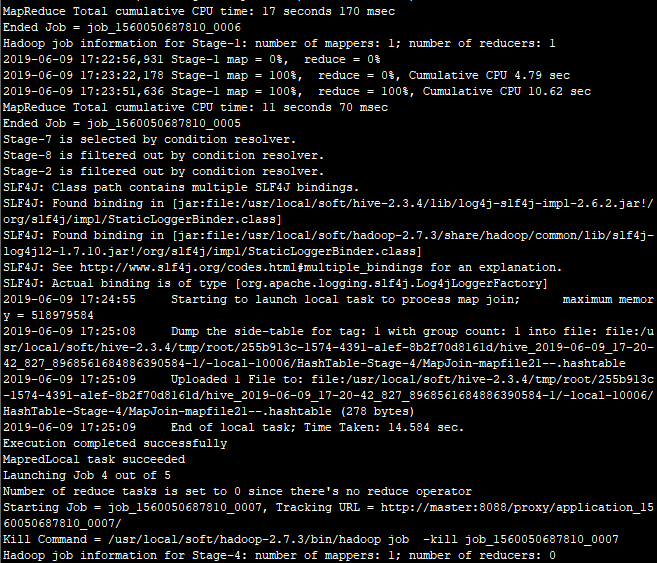
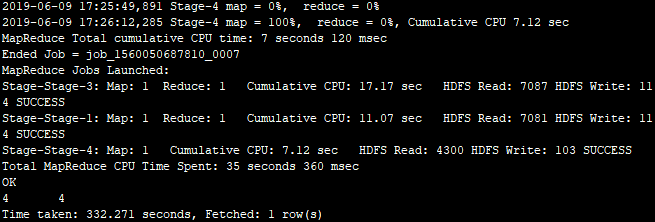
注意:性能大概提升25%,这主要和SQL是否可以并行执行有关!