一.异常情况及解决方案
在使用Spark SQL的dataframe数据写入到相应的MySQL表中时,报错,错误信息如下:
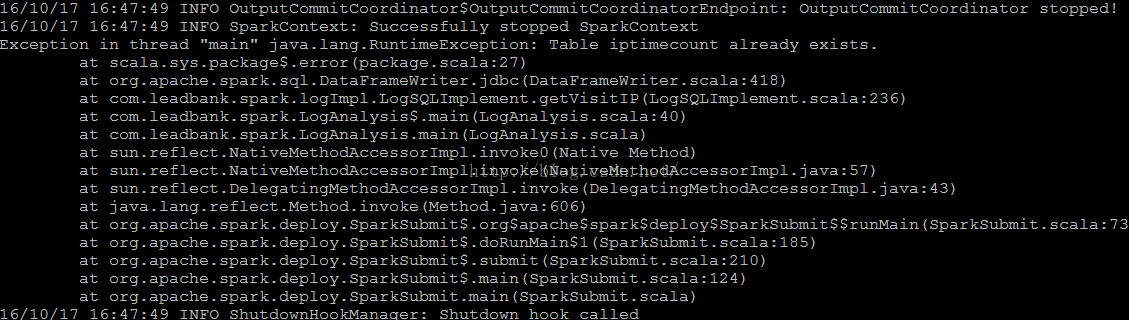
代码的基本形式为: df.write.jdbc(url, result_table, prop)
根据图片中的报错,搜索资料,得知是由于Spark SQL 中的Save Mode导致的,Spark SQL的官方文档中对Savemode进行了说明:
默认情况下,使用SaveMode.ErrorIfExists,也就是说,当从Spark中插入到MySQL表中的时候,如果表已经存在,则直接报错,想想真觉得这默认值有点坑。
于是修改Savemode,将代码改成:df.write.mode(SaveMode.Append).jdbc(url, result_table, prop)
再次执行,本以为应该会顺利存入到数据库中了,没想到还是报错:

使用desc查看表的结构,发现在Spark SQL中列类型为String类型的,在MySQL中对应为Text类型,于是我猜测应该是我之前创建的表格中,将列的类型定义为char和varchar导致的。于是,我删除表格,重新创建表格,将char和varcha;r类型改为Text,再次执行,顺利的将数据从Spark SQL中存入到了Mysql.
二.注意事项
A. 尽量先设置好存储模式
SaveMode.ErrorIfExists【默认】模式,该模式下,如果数据库中已经存在该表,则会直接报异常,导致数据不能存入数据库;
SaveMode.Append 如果表已经存在,则追加在该表中;若该表不存在,则会先创建表,再插入数据;
SaveMode.Overwrite 重写模式,其实质是先将已有的表及其数据全都删除,再重新创建该表,最后插入新的数据;
SaveMode.Ignore 若表不存在,则创建表,并存入数据;在表存在的情况下,直接跳过数据的存储,不会报错。
B. 设置存储模式的步骤为:
df.write.mode(SaveMode.Append)
C. 若提前在数据库中手动创建表,需要注意列名称和数据类型,
需要保证Spark SQL中schema中的field name与Mysql中的列名称一致!
若提前手动创建Mysql表,需要注意Spark SQL 中Schema中的数据类型与Mysql中的数据类型的对应关系,如下图所示:
