一.Client模式
提交命令:
./spark-submit --master yarn --class org.apache.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.7.3.jar 1000
./spark-submit --master yarn-client --class org.apache.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.7.3.jar 1000
./spark-submit --master yarn --deploy-mode client --class org.apache.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.7.3.jar 1000
架构:

二.Cluster模式
提交命令:
./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.7.3.jar 1000
./spark-submit --master yarn-cluster --class org.apache.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.7.3.jar 1000
架构:
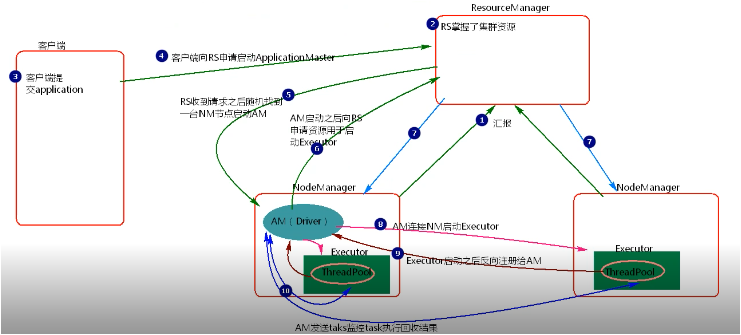
三.区别
client模式会在客户端创建Driver,当任务过多时会导致网络IO激增问题,而cluster会在集群的各个节点创建Driver,均摊了网络IO,不易发生网络瓶颈。