一.简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka是一个高吞吐的分布式消息队列系统。特点是生产者消费者模式,先进先出(FIFO)保证顺序,本身不会丢失数据,默认清理7天之前的数据。消息队列常见常见场景:系统之间解耦合,峰值压力缓冲,异步通信等等。
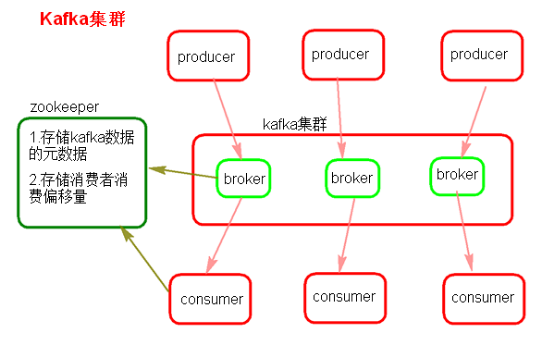
二..架构
producer:消息生产者
consumer:消息消费者
broker:Kafka集群的servevr,负责处理消息读、写请求,存储数据
topic:消息队列、分类
三.特点
1.一个topic分成多个partition【提高并行度】
2.每个partition内部消息强有序【FIFO】,其中的每个消息都有一个序号叫offset【偏移量】
3.一个partition只对应一个broker,一个broker可以管理多个partition
4.消息直接写入文件,并不是保存在内存中【NIO:不经过用户内存,直接写入磁盘】
5.默认【一周】根据时间策略删除数据,而不是消费完就删除
6.producer自己决定往哪个partition写消息,可以基于轮询【负载均衡】策略,或者基于hash策略
7.consumer自己维护消费到哪个offset
8.每个consumer都有对应的group,每个consumer消费不同的partition,一个消息在group内只消费一次
9.每个group各自独立,互不影响
10.高性能,单节点支持上千个客户端,百MB/s吞吐
11.分布式,数据副本冗余,流量负载均衡,可扩展
12.kafka和很多消息系统策略不同,很多消息系统是消费完就删除,而kafka是根据时间策略进行删除的,不是消费完就删除,在kafka里面没有消费完,只有过期。
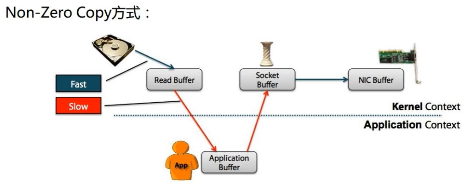
备注:零拷贝
四.Kafka与其它消息队列比较
1.RabbitMQ:分布式,支持多种MQ协议,重量级
2.ActiveMQ:与RabbitMQ类似
3.ZeroMQ:以库的形式提供,使用复杂,无持久化
4.Redis:纯内存性能好,持久化较差
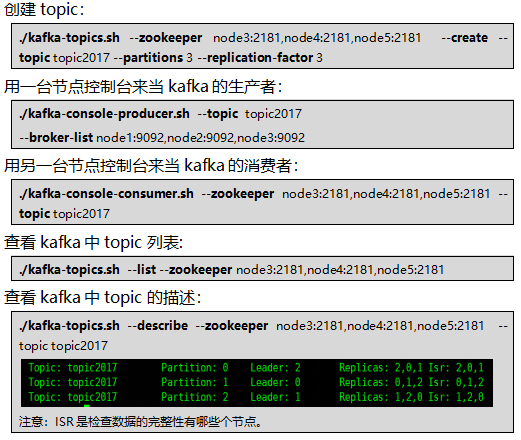
五.相关命令


六.优先副本策略
kafka中有一个优先副本(preferred replicas)的概念。如果一个分区有3个副本,且这3个副本的优先级分别为0,1,2,根据优先副本的策略,0优先级副本所在的broker会作为leader。当这个broker挂掉时,会自动启动1优先级副本所在的broker当做leader。当0优先级副本所在的borker重启后,会自动切换回该borker作为leader。这样就不会负载不均衡和资源浪费,这就是leader的均衡机制。
