一.简介
Spark的自定义udf和udaf是为了提供函数扩展,Spark本身提供了几十上百个算子,在数据分析的各个方面的常用计算方式都有提到,但计算场景千差万别,算子也不会面面俱到,如何在单机或集群上定义函数就是要重点关注的地方。特别是在集群模式中,函数需要使用spark注册才能在各个节点上使用,因此,udf和udaf就显得比较重要了。
二.设置日志级别
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别为WARN
三.创建spark入口
val spark = SparkSession.builder().appName("UdfUdaf").master("local[2]").getOrCreate()
val sc = spark.sparkContext
val sqlContext = spark.sqlContext
四.创建测试数据
val userData = Array( "2015,11,www.baidu.com", "2016,14,www.google.com", "2017,13,www.apache.com", "2015,21,www.spark.com", "2016,32,www.hadoop.com", "2017,18,www.solr.com", "2017,14,www.hive.com" ) val userDataRDD = sc.parallelize(userData) // 转化为RDD val userDataType = userDataRDD.map(line => { val Array(age, id, url) = line.split(",") Row(age, id.toInt, url) }) val structTypes = StructType(Array( StructField("age", StringType, true), StructField("id", IntegerType, true), StructField("url", StringType, true) )) // RDD转化为DataFrame val userDataFrame = sqlContext.createDataFrame(userDataType,structTypes)
// 注冊临时表
userDataFrame.createOrReplaceTempView("udf")
五.自定义udf并测试
def isAdult(age : Int) ={ if(age > 18){ true }else{ false } }
// 注册udf(方式一) spark.udf.register("isAdult_1", (id : Int) => if(id > 18) true else false) // 匿名函数 // 注册udf(方式二) spark.udf.register("isAdult_2", isAdult _) // 预先定义好的普通函数 // 验证udf方式一 val result_1 = sqlContext.sql("select * from udf where isAdult_1(udf.id)") result_1.show(false) // 验证udf方式二 val result_2 = sqlContext.sql("select * from udf where isAdult_2(udf.id)") result_2.show(false)
六.执行结果
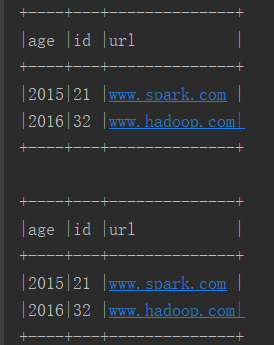
七.自定义udaf并测试
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction{ //聚合函数输入数据结构 override def inputSchema:StructType = StructType(StructField("input", LongType) :: Nil) //缓存区数据结构 override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil) //结果数据结构 override def dataType : DataType = DoubleType // 是否具有唯一性 override def deterministic : Boolean = true //初始化 override def initialize(buffer : MutableAggregationBuffer) : Unit = { buffer(0) = 0L buffer(1) = 0L } //数据处理 : 必写,其它方法可选,使用默认 override def update(buffer: MutableAggregationBuffer, input: Row): Unit = { if(input.isNullAt(0)) return buffer(0) = buffer.getLong(0) + input.getLong(0) //求和 buffer(1) = buffer.getLong(1) + 1 //计数 } //合并 override def merge(bufferLeft: MutableAggregationBuffer, bufferRight: Row): Unit ={ bufferLeft(0) = bufferLeft.getLong(0) + bufferRight.getLong(0) bufferLeft(1) = bufferLeft.getLong(1) + bufferRight.getLong(1) } //计算结果 override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1) }
/** * 测试udaf */ spark.udf.register("average", AverageUserDefinedAggregateFunction) spark.sql("select count(*) count,average(age) avg_age from udf").show(false)
八.执行结果
