---
title: 不懂SQL优化?那你就OUT了(十二)
MySQL如何优化-- 分区(三)-- 列分区
date: 2019-01-19
categories: 数据库优化
---

这一篇我们将讨论列分区, 列分区是范围分区和列表分区的变体。
列分区允许在分区键中使用多个列,使用多个列的目的是让mysql知道如何把行数据放到相应的分区中去,以确定在查询时只要检查哪些分区来匹配该分区的行数据。
此外,范围列分区和列表列分区都支持使用 非整数列 来定义值范围或列表成员。
允许的数据类型如下表所示:
1. 所有整数类型:TINYINT、SMALLINT、MEDIUMINT、INT (integer)和BIGINT。(这与按范围和列表进行分区是一样的。)。 分区列不支持其他数字数据类型(如小数或浮点数)。
2. DATE 和 DATETIME 类型.(不支持 使用与日期或时间相关的其他数据类型的列 作为分区列。)
3. 字符串类型: CHAR、VARCHAR、BINARY和VARBINARY。(TEXT and BLOB的列不支持作为分区列)
## 范围列分区
范围列分区类似于范围分区,但是允许您使用基于多个列值的范围来定义分区。此外,也可以使用整数类型以外的类型列定义范围。
范围列分区 与 范围分区 的区别主要体现在以下方面:
1.范围列不接受表达式,只接受列的名称。
2.范围列接受一个或多个列的列表(范围列分区是基于元组(列值列表)之间的比较,而不是标量值之间的比较。在范围列分区中放置的行数据也是基于列值列表之间的比较;这将在本篇后面进一步讨论。)
3.范围列分区的列不限于整数列, 也可以是string、DATE和DATETIME列也可以用作分区列。
创建范围列分区的的表的语法为:
CREATE TABLE table_name(
列名列表...
)
PARTITIONED BY RANGE COLUMNS(column_list) (
PARTITION partition_name VALUES LESS THAN (value_list)[,...],
PARTITION partition_name VALUES LESS THAN (value_list)][,...]
)
column_list:
column_name[, column_name][, ...]
value_list:
value[, value][, ...]
在上面的语法中,
column_list: 表示的是一个或多个列的列表(有时称为分区列列表)。
value_list:表示的是一个值列表(即分区定义的值列表)。分区时必须为每个定义的分区提供value_list,并且每个value_list 必须具有与 column_list <span style="color:coral">具有列相同数量</span>的值,一般来说,如果在columns子句中使用N列,那么必须为每个小于子句的值提供N个值的列表。
分区列列表中的元素和定义每个分区的值列表中的元素必须以相同的顺序出现,并且 值列表 中的每个元素必须与 列列表 中的相应元素具有相同的数据类型。但是,分区列列表中的列名和值列表的顺序可以与CREATE table语句中的定义表列的顺序不相同。与按范围分区的表一样,您也可以使用MAXVALUE来表示一个值,那些总是小于此值的任何合法值的行数据会被插入到给定列中。
示例如下:
CREATE TABLE t_one (
a INT,
b INT,
c CHAR(3),
d INT
)
PARTITION BY RANGE COLUMNS(a,d,c) (
PARTITION p0 VALUES LESS THAN (5,10,'one'),
PARTITION p1 VALUES LESS THAN (10,20,'two'),
PARTITION p2 VALUES LESS THAN (15,30,'three'),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);
上面创建的t_one表中包含了四个列 a,b,c,d 四个列, 然后我们使用范围列分区进行分区,使用column_list子句的分区列列表 分区列列表使用表中的3列,分区列的顺序为 a,d,c(与建表的 a,c,d的顺序不同), 其中每个 值列表 的顺序必须和分区列列表的的顺序一致(也必须一是 a,d,c),并且值列表的值的数据类型也必须和分区列列表的数据类型一致(即: int, int, char(3))。
当存放数据时,将与COLUMNS子句中的列列表匹配,将需要插入的行数据与用于定义表分区的VALUES LESS THAN子句中使用的值列表的值逐一进行比较,从而确定该行数据会被放到哪个分区中。因为我们比较的是一个值集而不是标量值(一个值),所以与范围分区有所不同。
在范围分区中,行数据生成的表达式值的大于或则等于 VALUES LESS THAN后的值的时,行数据不会放在相应的分区中;但是,在 范围列分区 中,对于分区列列表的第一个元素的值小于或则等于 值列表的 第一个元素的值相等的行。有时可以将其放置在相应的分区中。
例如: 创建一个以 列a 的值分区的表(范围分区)。
CREATE TABLE t_two (
a INT,
b INT
)
PARTITION BY RANGE (a) (
PARTITION p0 VALUES LESS THAN (5),
PARTITION p1 VALUES LESS THAN (MAXVALUE)
);
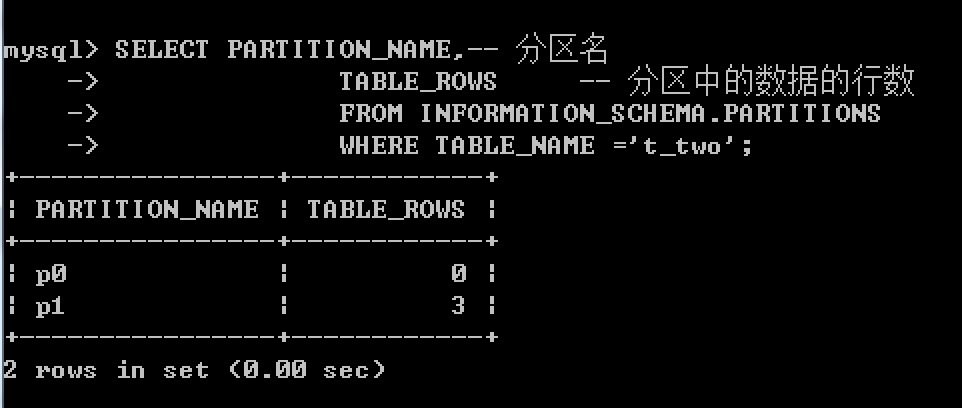
现在往t_two中加入3条数据,每条数据的 a列 的值都为5,那么这3条数据都会被分配至 p1分区,然后我们可以对INFORMATION_SCHEMA 通过查询数据在表中的分布情况。
INSERT INTO t_two VALUES (5,10), (5,11), (5,12);
查看数据的分布结果:
SELECT PARTITION_NAME,-- 分区名
TABLE_ROWS -- 分区中的数据的行数
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME ='t_two';
再创建一个跟上面表类似的表,使用列a和列b进行范围列分区:
CREATE TABLE t_two_columns (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a, b) (
PARTITION p0 VALUES LESS THAN (5, 12),
PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE)
);
然后再往表中添加3条数据:
INSERT INTO t_two_columns VALUES (5,10), (5,11), (5,12);
查看数据的分布结果:

这是因为在范围列分区中,我们比较的是值集而不是单个标量值,只有当第一个列的值相等时,再比较第二个列的值。 例如: 第一条 row(5,10)中的的第一个列的值等于5,但是第二列的值 10 是小于 12,所以 第一条数据会被分配到p0分区中,第二条数据同理,但是第三条数据5等于5 但是12不小于12, 所以第三条数据会被分配到p1分区中。
***对于仅使用单个分区列的 按范围列分区 的表,分区中存储的行与按范围分区存储相同.***
1. 单个列的 范围列分区
CREATE TABLE t_one_column_range (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS (a) (
PARTITION p0 VALUES LESS THAN (5),
PARTITION p1 VALUES LESS THAN (MAXVALUE)
);
添加三条数据。
INSERT INTO t_one_column_range VALUES (5,10), (5,11), (5,12);
查看结果

2. 如果你想使用第一列的的值做范围列区的基点,然后再以第二列的的值再次分区的话,你可以像下面的的示例中来创建表(当然使用3个列或则更多的列依次类推)。
CREATE TABLE t_two__column_range (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS (a,b) (
PARTITION p0 VALUES LESS THAN (5,10),
PARTITION p1 VALUES LESS THAN (5,20),
PARTITION p2 VALUES LESS THAN (10,10),
PARTITION p3 VALUES LESS THAN (10,20),
PARTITION p4 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
说明: 当a的值小于5时,所有数据放到p0分区中,当a的值等于5时,此时在比较第二列的值,并且b的值小于10时,也放在p0分区中
插入10条数据
INSERT INTO t_two__column_range VALUES(1,5),(5,6),(5,10),(5,15),(6,5),(10,8),(10,10),(10,16),(12,1),(13,18);
1,2条数据在p0分区中, 3,4条在p1分区中, 5,6 条数据在p2, 7,8条数据在p3,9,10条在p4分区中
查看结果:

> 注意: 如果CREATE TABLE语句包含的分区,定义时不是严格按递增顺序排列的,则会出现错误。如下:
>

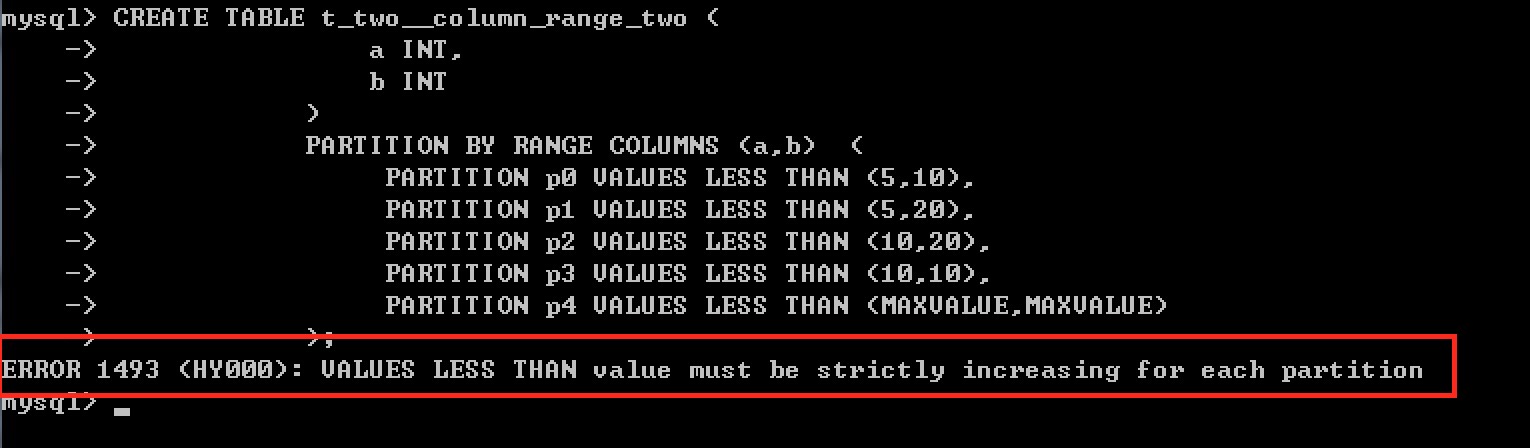
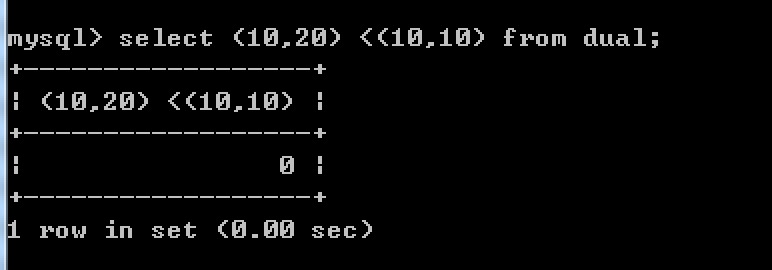
从错误中可以看出: 对于每个分区,小于的值必须严格递增。
当您得到这样的错误时,您可以通过在它们的列列表之间进行比较来推断哪个分区定义是无效的。
例如:上面在创建表时 因为 p2的的值 (10,20) 大于 p3的值(10,10)(分区定义时不是递增的),所以报错:如图。
3.如前所述,对于范围列分区,也可以使用非整数列作为分区列。
例如创建一个员工表,然后以员工的姓名列进行分区
CREATE TABLE t_employees_cloumn (
id INT ,
emp_name VARCHAR(30),
hired DATE DEFAULT '1970-01-01',
separated DATE DEFAULT '9999-12-31',
job_code INT ,
store_id INT
) PARTITION BY RANGE COLUMNS (emp_name) (
PARTITION p0 VALUES LESS THAN ('l'),
PARTITION p1 VALUES LESS THAN ('r'),
PARTITION p2 VALUES LESS THAN ('s'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
添加几条数据
INSERT INTO t_employees_cloumn(emp_name) VALUES('alan'),('lisa'),('caroline'),('jane'),('zla');
查看结果

>
>请注意
因为不同的字符集和排序规则具有不同的排序顺序,所以在使用字符串列作为分区列时,所使用的字符集和排序规则可能会影响按范围列分区的表 存放 行数据到某个分区。此外,在创建了给定的数据库、表或列之后,更改它们的字符集或排序规则可能会导致行的分布方式发生变化。
当然你也可以使用ALTER table语句对表分区进行修改,例如:
ALTER TABLE t_employees_cloumn PARTITION BY RANGE COLUMNS (hired) (
PARTITION p0 VALUES LESS THAN ('1970-01-01'),
PARTITION p1 VALUES LESS THAN ('1980-01-01'),
PARTITION p2 VALUES LESS THAN ('1990-01-01'),
PARTITION p3 VALUES LESS THAN ('2000-01-01'),
PARTITION p4 VALUES LESS THAN ('2010-01-01'),
PARTITION p5 VALUES LESS THAN (MAXVALUE)
##列表列分区
MySQL 8.0提供了对 列表列分区 的支持。它是列表分区 的一种变体,它允许使用多个列作为分区键,并允许将非整数类型的数据类型列用作分区列;可以使用字符串类型、日期和日期时间列。
假设您的企业在3个省份市拥有客户,出于销售和市场营销的目的,您将每个省份分为多个城市区域进行划分,如下表所示:
| 省份 | 城市 |
| :-: | :-: |
| 四川省| 成都,绵阳,自贡 |
| 云南省| 昆明,大理,玉溪 |
| 贵州省| 遵义,六盘水|
使用列表列分区,我们创建一个客户数据表
CREATE TABLE t_customers_list_column(
cid INT, -- 客户编号
NAME VARCHAR(25), -- 客户姓名
city VARCHAR(15), -- 所在城市
street VARCHAR(30), -- 详细地址
joinTime DATE -- 加入时间
) PARTITION BY LIST COLUMNS(city)(
PARTITION Region_1 VALUES IN('成都', '绵阳', '德阳'),
PARTITION Region_2 VALUES IN('昆明', '大理', '玉溪'),
PARTITION Region_3 VALUES IN('遵义', '六盘水')
);
现在表中添加一些数据
INSERT INTO t_customers_list_column VALUES(1,'客户一','成都','街道地址一','2010-10-1');
INSERT INTO t_customers_list_column VALUES(2,'客户二','成都','街道地址二','2010-10-20');
INSERT INTO t_customers_list_column VALUES(3,'客户三','绵阳','街道地址三','2012-2-15');
INSERT INTO t_customers_list_column VALUES(4,'客户四','德阳','街道地址四','2012-3-11');
INSERT INTO t_customers_list_column VALUES(5,'客户五','大理','街道地址五','2013-05-10');
INSERT INTO t_customers_list_column VALUES(6,'客户六','昆明','街道地址六','2013-05-20');
INSERT INTO t_customers_list_column VALUES(7,'客户七','昆明','街道地址七','2013-12-12');
INSERT INTO t_customers_list_column VALUES(8,'客户八','玉溪','街道地址八','2013-12-26');
INSERT INTO t_customers_list_column VALUES(9,'客户九','遵义','街道地址九','2015-06-25');
INSERT INTO t_customers_list_column VALUES(10,'客户十','六盘水','街道地址十','2018-08-08');
查看分区数据
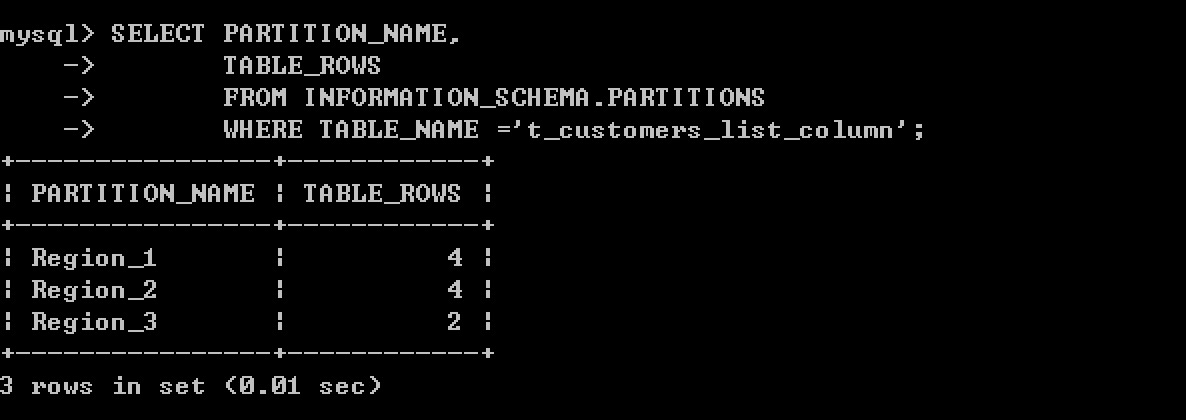
当然还可以使用DATE和DATETIME列做分区列,如下示例所示:
CREATE TABLE t_customers_list_column_2(
cid INT, -- 客户编号
NAME VARCHAR(25), -- 客户姓名
city VARCHAR(15), -- 所在城市
street VARCHAR(30), -- 详细地址
joinTime DATE -- 加入时间
) PARTITION BY LIST COLUMNS(joinTime)(
PARTITION Region_1 VALUES IN('2010-10-1','2010-10-20'),
PARTITION Region_2 VALUES IN('2012-2-15', '2012-3-11'),
PARTITION Region_3 VALUES IN('2013-05-10', '2013-05-20', '2013-12-12','2013-12-26'),
PARTITION Region_4 VALUES IN('2015-06-25'),
PARTITION Region_5 VALUES IN('2018-08-08')
);
如果涉及的日期数量比较多的话,那么定义和维护起来就变得非常麻烦,在这种情况下,通常更实际的做法是使用范围分区或则范围列分区。
此外(与范围列分区一样),列表列分区也可以在COLUMNS()子句中使用多个列。
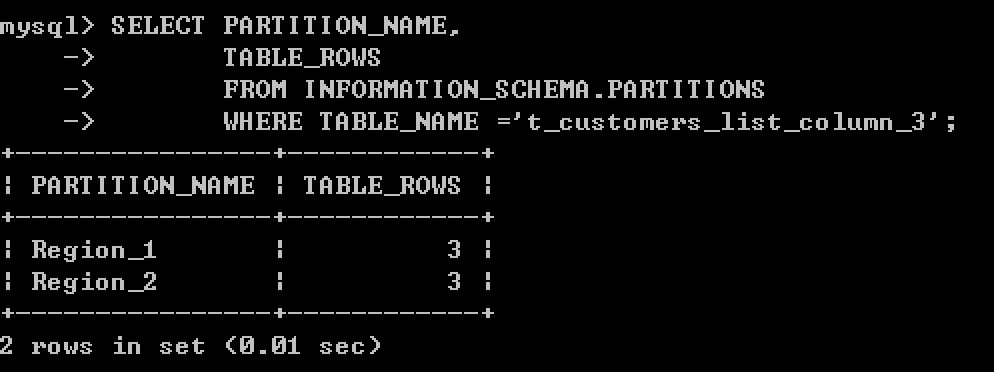
例如: 按城市和所在区分区
CREATE TABLE t_customers_list_column_3(
cid INT, -- 客户编号
NAME VARCHAR(25), -- 客户姓名
city VARCHAR(15), -- 所在城市
_area VARCHAR(30), -- 所处区域
street VARCHAR(30), -- 详细地址
joinTime DATE -- 加入时间
) PARTITION BY LIST COLUMNS(city,_area)(
PARTITION Region_1 VALUES IN(('成都','锦江区'),('成都','青羊区')),
PARTITION Region_2 VALUES IN(('昆明','官渡区'),('昆明','西山区'))
);
添加一些数据
INSERT INTO t_customers_list_column_3 VALUES(1,'客户一','成都','锦江区','街道地址一','2010-10-1');
INSERT INTO t_customers_list_column_3 VALUES(2,'客户二','成都','锦江区','街道地址二','2011-08-01');
INSERT INTO t_customers_list_column_3 VALUES(3,'客户三','成都','青羊区','街道地址一','2017-02-14');
INSERT INTO t_customers_list_column_3 VALUES(4,'客户四','昆明','官渡区','街道地址一','2018-05-25');
INSERT INTO t_customers_list_column_3 VALUES(5,'客户五','昆明','西山区','街道地址一','2018-02-18');
INSERT INTO t_customers_list_column_3 VALUES(6,'客户六','昆明','西山区','街道地址二','2017-03-14');
查看分区的数据