---
title: 不懂SQL优化?那你就OUT了(十)
MySQL如何优化-- 分区(二)-- RANGE 分区
date: 2019-01-05
categories: 数据库优化
---

上篇博客我们讨论了分区的概述,优点和分区的类型。 这篇我们将更详细的讨论分区的类别:
###RANGE 分区
按范围分区的分区方式:每个分区 包含 分区表达式值位于给定范围内的行。范围应该是连续的,而不是重叠的,并且使用 <font style='color:coral'>VALUES LESS THAN</font> 操作符来进行定义.
案列:
CREATE TABLE t_range_employee (
id INT NOT NULL, -- 员工编号
ename VARCHAR(30), -- 员工姓名
hired DATE NOT NULL DEFAULT '1970-01-01', -- 雇佣时间
separated DATE NOT NULL DEFAULT '9999-12-31', -- 离职时间
job_code INT NOT NULL, -- 职位编号
store_id INT NOT NULL -- 所在音像店编号
)ENGINE=INNODB ;
> 注意:
>
> 这里使用的t_range_employee表<span style='color:coral;font-size:20px;'>没有主键或惟一键</span>。
>
> 你应该记住,极有可能在实践中表是有主键,唯一键,或两者兼而有之,这使得在 选择分区列 时要取决于这些列是否有主键和唯一键, 如果有主键或则唯一键时,我们将在后面 关于分区的限制中讨论(分区键、主键和惟一键)
根据你的需要,这个表可以有多种方式来按照范围区间进行分区。
一种分区方案是使用store_id列进行分区。例如,可以通过添加一个<span style='color:coral;font-size:15px;'>partition by RANGE子句</span>把这个表分割成4个区间,如下所示:
CREATE TABLE t_range_employee (
id INT NOT NULL, -- 员工编号
ename VARCHAR(30), -- 员工姓名
hired DATE NOT NULL DEFAULT '1970-01-01', -- 雇佣时间
separated DATE NOT NULL DEFAULT '9999-12-31', -- 离职时间
job_code INT NOT NULL, -- 职位编号
store_id INT NOT NULL -- 所在音像店编号
) ENGINE=INNODB
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
在这个范围分区方案中,存储的音像店编号为 1到5 的员工对应的所有行 存储在分区p0中,存储音像店编号6到10的员工对应的行存储在分区p1中,以此类推。每个分区都是按照从低到高的顺序定义的。这是按范围语法划分的要求; 你可以把范围分区想象成C和JAVA语言中的if...elseif…语句
如果往表中添加一条数据:
INSERT INTO t_range_employee VALUES(18,'张某某','2008-11-02',DEFAULT,1,15);
此时很容易确定将这条新数据插入到分区p2中。 那么找查找这条数据时,mysql就会只在p2分区快中查找,这样效率就会快很多。
但是此时有个问题 ?如果此时往音像店表中添加第21家商店时,会发生什么呢?
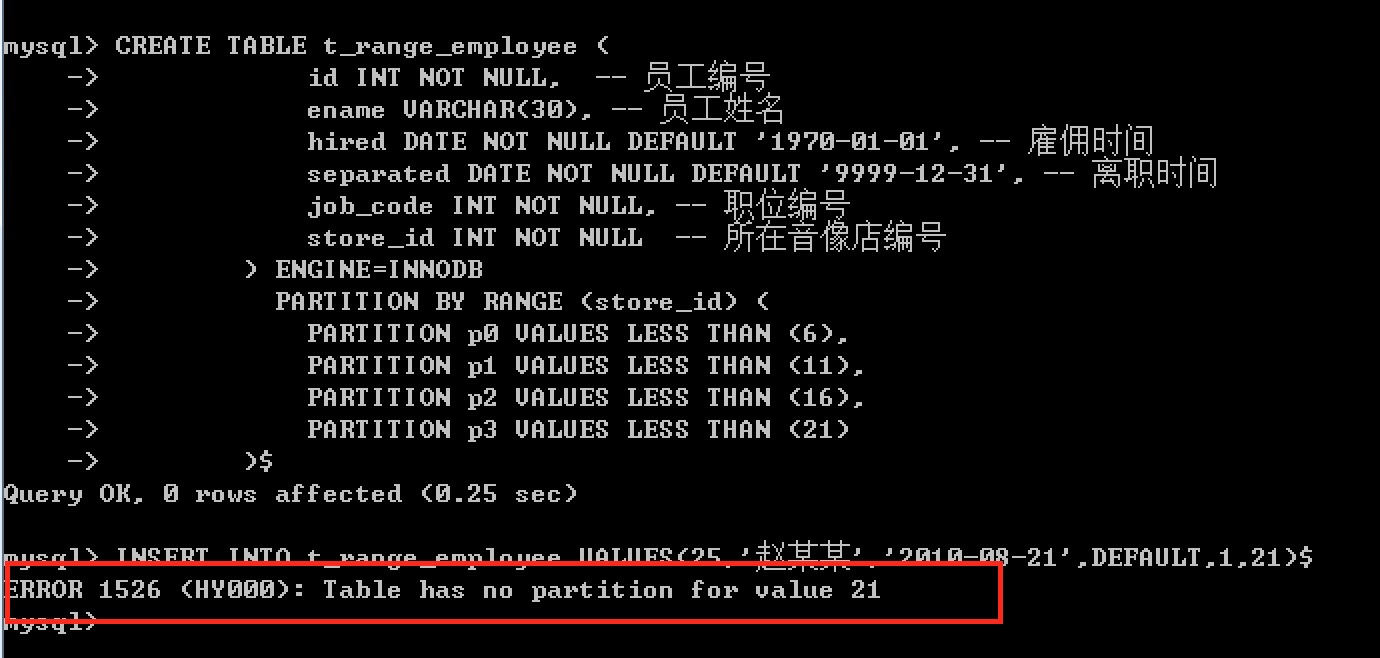
由于t_range_employee表没有放置store_id大于20的行的分区,因此会出现错误,因为服务器不知道将其放置在何处。要避免这种错误,你可以通过在 CREATE TABLE 语句中使用 一个 “catchall” VALUES LESS THAN子句,该子句提供了将所有大于指定最大值的行放置该分区中。
例如:
CREATE TABLE t_range_employee (
id INT NOT NULL, -- 员工编号
ename VARCHAR(30), -- 员工姓名
hired DATE NOT NULL DEFAULT '1970-01-01', -- 雇佣时间
separated DATE NOT NULL DEFAULT '9999-12-31', -- 离职时间
job_code INT NOT NULL, -- 职位编号
store_id INT NOT NULL -- 所在音像店编号
) ENGINE=INNODB
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
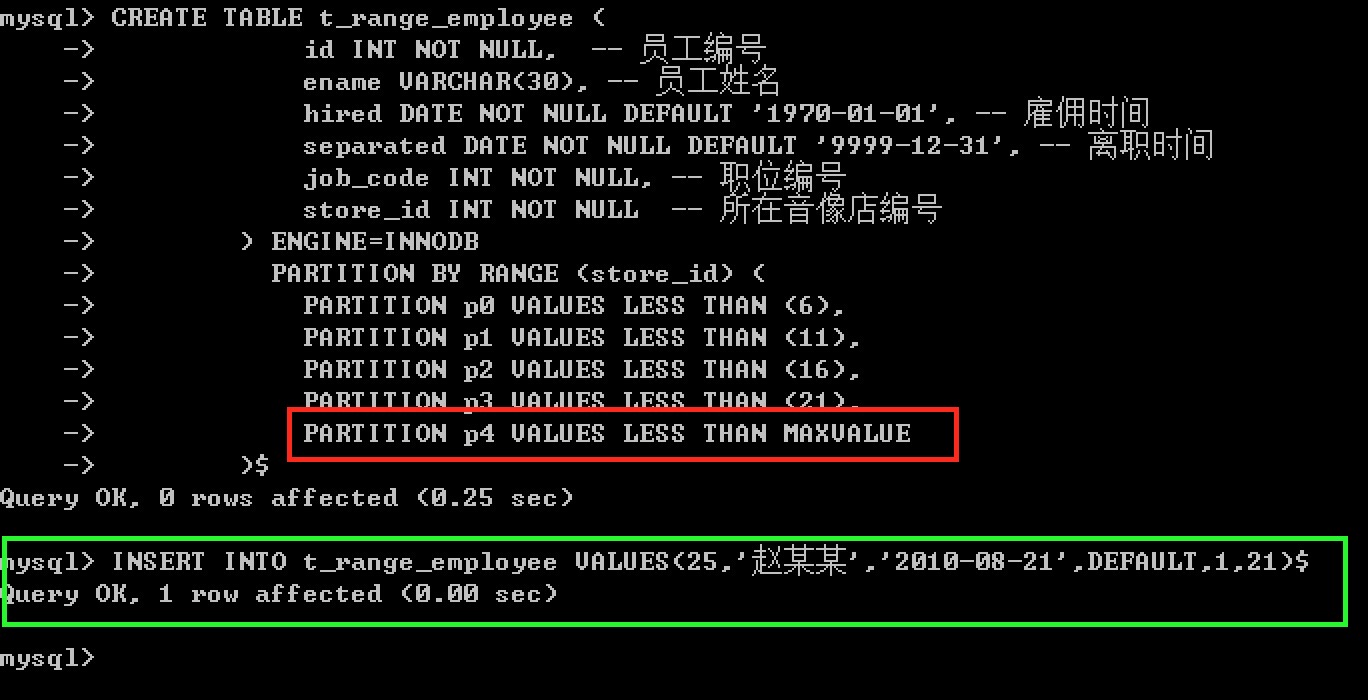
MAXVALUE 表示的整数值总是大于可能的最大整数值(在数学中,它是最小上界)。也就是说,当store_id 列值大于或等于21(定义的最大值)的任何行都存储在p4分区中,在将来的某个时候,当存储的数量增加到25、30或更多时,您可以使用ALTER TABLE语句为存储21-25、26-30等添加新的分区(有关如何做到这一点的详细信息,将会在后面的分区管理中讨论”)。
以同样的方式,你也可以使用 job_code 来进行分区,假设两位数的编号用于普通(店内)员工,三位数编号的用于办公室和技术支持人员,四位数编号用于管理职位,您可以使用以下语句创建分区表:
CREATE TABLE t_range_employee (
id INT NOT NULL, -- 员工编号
ename VARCHAR(30), -- 员工姓名
hired DATE NOT NULL DEFAULT '1970-01-01', -- 雇佣时间
separated DATE NOT NULL DEFAULT '9999-12-31', -- 离职时间
job_code INT NOT NULL, -- 职位编号
store_id INT NOT NULL -- 所在音像店编号
) ENGINE=INNODB
PARTITION BY RANGE (job_code) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (10000)
);
当然您也可以在分区子句中使用表达式。但是,MySQL必须能够计算表达式的值,并且返回值作为小于(<)比较的一部分。
例如: 使用雇佣时间来分区,把雇佣时间在2000年之前的划分到p0区,2000到2015年的划分到p1区,2015年--2020年放到p2区,其他年份的放到p3区
CREATE TABLE t_range_employee (
id INT NOT NULL, -- 员工编号
ename VARCHAR(30), -- 员工姓名
hired DATE NOT NULL DEFAULT '1970-01-01', -- 雇佣时间
separated DATE NOT NULL DEFAULT '9999-12-31', -- 离职时间
job_code INT NOT NULL, -- 职位编号
store_id INT NOT NULL -- 所在音像店编号
) ENGINE=INNODB
PARTITION BY RANGE (YEAR(hired)) (
PARTITION p0 VALUES LESS THAN (2000),
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
####什么时候使用范围分区
RANGE分区在如下场合特别有用:
1. 需要删除一些旧数据的时候。
如果你使用的是按雇佣时间来分区的方案,那么您可以简单地使用 alter table t_range_employee drop partition p0 来删除 雇佣分年在2000以前的数据。这比你执行 delete from t_range_employee where year(hired) <2000 语句的效率高很多。
2. 想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。
3. 经常运行直接依赖于用于分割表的列的查询。
例如: 当你需要执行:
EXPLAIN SELECT COUNT(*) FROM t_range_employee WHERE separated BETWEEN '2000-01-01' AND '2000-12-31' GROUP BY store_id; MySQL可以快速确定只需要扫描分区p1,因为其余的分区不能包含任何满足WHERE子句的记录。