MySQL性能优化
MySQL性能优化之explain
在日常的MYSQL优化中我们常常看到这样一个关键词:explain,例如这种:
EXPLAIN SELECT * FROM Cloud_Order WHERE money > 10;
explain是什么呢?使用 EXPLAIN 关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。通过explain命令可以得到:
-
表的读取顺序
-
数据读取操作的操作类型
-
哪些索引可以使用
-
哪些索引被实际使用
-
表之间的引用
-
每张表有多少行被优化器查询
首先让我们来看看使用EXPLAIN输入的结果

结果显示输出了结果一堆字段和对应的值,但是这些字段是什么意思?对应的值又是什么呢?如何通过这些字段来分析到SQL的性能并做出优化呢?别急,下面我们就一起来一一分析。
EXPLANIN字段分析

explain实践
说了这么多,实践才能出真知。下面我们通过一个简单的例子来优化我们一些不堪的SQL。
首先我们还是一张数据表举例。表结构如下。
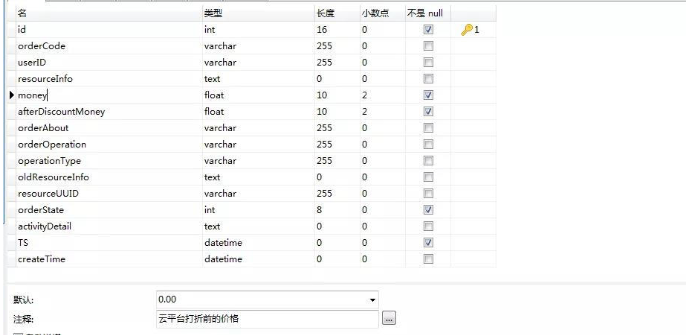
这是一张典型的订单表,其他字段我们可以省略不看,我们可以只看一个money字段,这基本是订单表都会用到的字段。由于时间关系,事先我已经为这个表准备了一堆模拟数据。

从上图可以看出,表中已经有一万条数据,下面我们来写一个根据money条件来查询订单的SQL。

只能说上图的结果不尽人意。让我们回到之前explain字段的分析,其中type字段的值是ALL,按照分析来说,这个表用了全表搜索,我们应尽量避免!!!再看rows字段,值是16242,天啊!!所有记录都去请求了,那慢是有原因的。
好了,通过上面的数据分析,我们可以去想一下,money字段是否能加上索引来提升查询速度呢?因为上述结果中好像是没用到索引的。话不多说,我们来为money字段加上索引

加上索引之后,我们再用刚刚的EXPLAIN语句执行一下,见证奇迹的时候到了!

经过加上索引之后,相同的sql语句,得出的结果完全不一样,type字段变成了range,我们也看到key显示了money,证明了索引值被用上了。更重要的是rows字段变成了785,跟原来相比少了不知道多少,可想而知性能有了多大的提高!
MySQL性能优化之慢查询
1.慢查询的用途
它能记录下所有执行超过long_query_time时间的SQL语句,帮我们找到执行慢的SQL,方便我们对这些SQL进行优化。
2.查看是否开启慢查询
show variables like 'slow_query%';

slow_query_log = off,表示没有开启慢查询
slow_query_log_file 表示慢查询日志存放的目录
3.开启慢查询(需要的时候才开启,因为很耗性能,建议使用即时性的)
方式一:(即时性的,重启mysql之后失效,常用的)
set global slow_query_log=1; 或者 set global slow_query_log=ON;
开启之后 我们会发现 /var/lib/mysql下已经存在 localhost-slow.log了,未开启的时候默认是不存在的。
方式二:(永久性的)
在/etc/my.cfg文件中的[mysqld]中加入:
slow_query_log=ON slow_query_log_file=/var/lib/mysql/localhost-slow.log
4.设置慢查询记录的时间
查询慢查询记录的时间:show variables like 'long_query%',默认是10秒钟,意思是大于10秒才算慢查询。
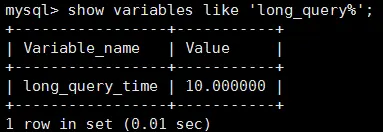
我们现在设置慢查询记录时间为1秒:set long_query_time=1;

5.执行select count(1) from order o where o.user_id in (select u.id where users);
因为我们开启了慢查询,且设置了超过1秒钟的就为慢查询,此sql执行了24秒,所以属于慢查询。
我们在日志中查看:
more /var/lib/mysql/localhost-slow.log,

我们可以看到查询的时间,用户,花费的时间,使用的数据库,执行的sql语句等信息。在生产上我们就可以使用这种方式来查看 执行慢的sql。
6.查询慢查询的次数:show status like 'slow_queries';

在我们重新执行刚刚的查询sql后,查询慢查询的次数会变为8

当然,用 more /var/lib/mysql/localhost-slow.log 也是可以看到详细结果的。
在生产中,我们会分析查询频率高的,且是慢查询的sql,并不是每一条查询慢的sql都需要分析。
7.慢查询日志分析工具Mysqldumpslow
由于在生产上会有很多慢查询,所以采用上述的方法查看慢查询sql会很麻烦,还好MySQL提供了慢查询日志分析工具Mysqldumpslow。
其功能是, 统计不同慢sql的出现次数(Count),执行最长时间(Time),累计总耗费时间(Time),等待锁的时间(Lock),发送给客户端的行总数(Rows),扫描的行总数(Rows)
(1)查询Mysqldumpslow的帮助信息,随便进入一个文件夹下,执行:mysqldumpslow --help
查看mysqldumpslow命令安装在哪个目录:whereis mysqldumpslow
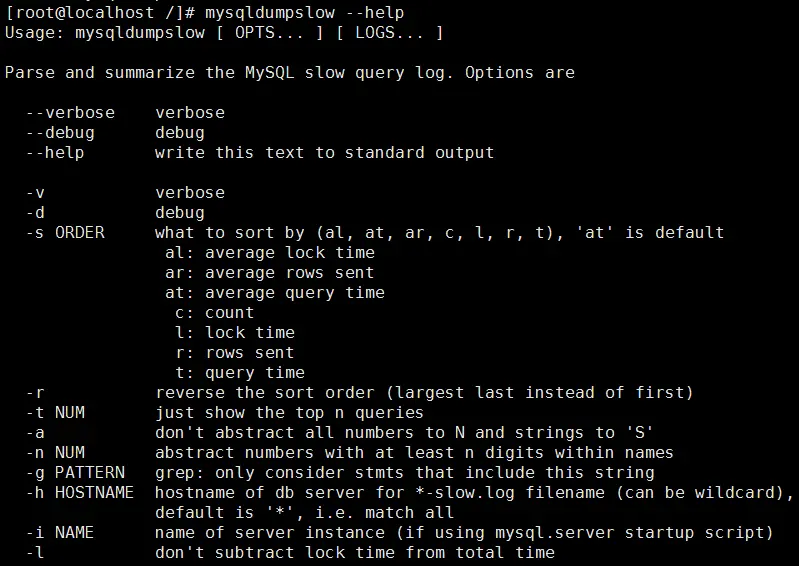
说明:
- -s,是order的顺序,主要有c(按query次数排序)、t(按查询时间排序)、l(按lock的时间排序)、r (按返回的记录数排序)和 at、al、ar,前面加了a的代表平均数
- -t,是top n的意思,即为返回前面多少条的数据
- -g,后边可以写一个正则匹配模式,大小写不敏感的
- -r:倒序
(2)案例:取出耗时最长的两条sql
格式:mysqldumpslow -s t -t 2 慢日志文件
mysqldumpslow -s t -t 2 /var/lib/mysql/localhost-slow.log

参数分析:
- 出现次数(Count),
- 执行最长时间(Time),
- 累计总耗费时间(Time),
- 等待锁的时间(Lock),
- 发送给客户端的行总数(Rows),
- 扫描的行总数(Rows),
- 用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).

这种方式更加方便,更加快捷!
8.show profile
用途:用于分析当前会话中语句执行的资源消耗情况
(1)查看是否开启profile,mysql默认是不开启的,因为开启很耗性能
show variables like 'profiling%';
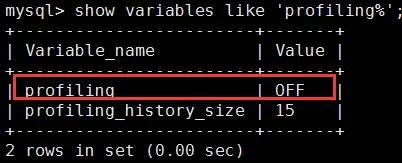
(2)开启profile(会话级别的,关闭当前会话就会恢复原来的关闭状态)
set profiling=1; 或者 set profiling=ON;
(3)关闭profile
set profiling=0; 或者 set profiling=OFF;
(4)显示当前执行的语句和时间
show profiles;

(5)显示当前查询语句执行的时间和系统资源消耗
show profile cpu,block io for query 4;(分析show profiles中query_id等于4的sql所占的CPU资源和IO操作)
或者直接 : show profile for query 4;

MySQL性能分析语句
show profile 和** show profiles** 语句可以展示当前会话退出session后,porfiling重置为0中执行语句的资源使用情况.
show profiles :以列表形式显示最近发送到服务器上执行的语句的资源使用情况.显示的记录数由变量:profiling_history_size 控制,默认15条

show profile: 展示最近一条语句执行的详细资源占用信息,默认显示 Status和Duration两列
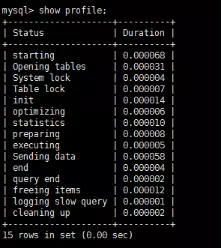
show profile 还可根据 show profiles 列表中的 Query_ID ,选择显示某条记录的性能分析信息
开启Profile功能
Profile 功能由My SQL会话变量:profiling控制,默认是OFF关闭状态。
查看是否开启了Profile功能:
show variables like ‘%profil%’;
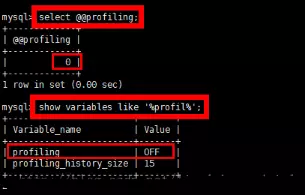
开启profile功能
set profiling=1; --1是开启、0是关闭
示例
1.查看是否打开了性能分析功能
select @@profiling;

2.打开 profiling 功能
set profiling=1;

3.执行sql语句

4. 执行 show profiles 查看分析列表

5.可指定资源类型查询
show profile cpu ,swaps for query 1;
MySQL事务处理
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
read uncommitted

read committed

repeatable read

serializable

持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。

事务控制语句:
BEGIN或START TRANSACTION;显式地开启一个事务;
COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT;
RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier;把事务回滚到标记点;
SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。
MYSQL 事务处理主要有两种方法:


回滚rollback之后数据库没有数据

MySQL锁
1.全局锁
命令
Flush tables with read lock (FTWRL)
使用这个命令后,其他线程的以下语句会被阻
- 数据更新语句(数据的增删改)
- 数据定义语句(包括建表、修改表结构等)
- 更新类事务的提交语句
场景
做全库逻辑备份,也就是把整个库的所有表都select出来存成文本
风险
- 备份期间都不能执行更新,业务基本就得停摆
- 如果你在从库备份,那么备份期间从库不能执行主库同步过来的binlog,会导致主从延迟
替代方法
- mysqldump -single-transaction,导数据时会启动一个事务,来确保拿到一致性视图。而由于MVCC(多版本并发控制)的支持,这个过程中的数据可以正常更新。缺点:只有innodb支持。
- set global readonly=true的方式,不建议使用,原因
- 在有些系统中,readonly的值会被是用来做其他逻辑。比如用来判断一个库是主库还是从库。因此修改global变量的方式,影响范围更大,我不建议使用。
- 在异常处理机制上有差异。如果执行FTWRL命令之后,由于客户端发生异常断开。那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库的设置readonly之后,如果客户端发生异常。在数据后就会一直保持readonly的状态。这样会导致整个库长时间处于不可写的状态,风险较高。
2.表级别锁
与FTWRL类似,可以用unlock tables 主动释放锁;也可以在客户端切断的时候自动释放。需要注意的是,lock tables语法除了会限制别的县城的读写外,也限定了本线程接下来的操作对象。
MySQL5.5版本中引入了MDL,当对一个表做增删改查操作时,加MDL读锁;当需要对表结构变更操作时,加MDL写锁。
- 读锁之间不互斥。因此,你可以有多个线程同时对一张表增删改查。
- 读写锁之间、写锁之间是互斥的。用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段。其中一个要等另外一个执行完才能开始执行。
3.行锁
- 行锁属于引擎层实现的,比如MyISAM引擎就不支持。
- 两阶段锁协议
在innodb事务中,行锁是在需要的时候才加上的。但并不是不需要了就立即释放。而是等到事务结束才释放。
MySQL集群搭建之主从复制
主从复制原理
binlog介绍和relay日志
查看binlog日志 mysqlbinlog 文件名称
主从复制实践
主服务器配置
第一步:修改my.conf文件:
在[mysqld]段下添加:
#启用二进制日志 log-bin=mysql-bin #服务器唯一ID,一般取IP最后一段 server-id=133
第二步:重启mysql服务
service mysqld restart
第三步:建立帐户并授权slave
mysql>GRANT FILE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456'; mysql>GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'backup'@'%' identified by '123456';
#一般不用root帐号,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
刷新权限
mysql> FLUSH PRIVILEGES;
查看mysql现在有哪些用户
mysql>select user,host from mysql.user;
第四步:查询master的状态
mysql> show master status;

从服务器配置
第一步:修改my.conf文件
[mysqld] server-id=134
第二步:删除UUID文件
错误处理:
如果出现此错误:
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
因为是mysql是克隆的系统所以mysql的uuid是一样的,所以需要修改。
解决方法:
删除/var/lib/mysql/auto.cnf文件,重新启动服务。
第三步:配置从服务器
mysql>change master to master_host='192.168.25.134',master_port=3306,master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=120
注意语句中间不要断开,master_port为mysql服务器端口号(无引号),master_user为执行同步操作的数据库账户,“120”无单引号(此处的120就是show master status 中看到的position的值,这里的mysql-bin.000001就是file对应的值)。
第四步:启动从服务器复制功能
mysql>start slave;
第五步:检查从服务器复制功能状态:
mysql> show slave status
……………………(省略部分)
Slave_IO_Running: Yes //此状态必须YES
Slave_SQL_Running: Yes //此状态必须YES
……………………(省略部分)
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。

以上操作过程,从服务器配置完成。
集群搭建之读写分离
1.MySQL-Proxy下载
2.MySQL-Proxy安装
3. MySQL-Proxy配置
创建mysql-proxy.cof文件

修改rw-splitting.lua脚本
MySQL-Proxy启动域测试
mysql-proxy --defaults-file=mysql-proxy.cnf配置文件的地址
注意事项:如果没有配置profile文件的环境变量,则需要去拥有mysql-proxy命令的目录通过./mysql-proxy进行启动。
mysql>start slave;