MySQL查询与结构
1 多表关联查询
交叉连接:
交叉连接返回的结果,是被连接的两个表中所有数据行的笛卡尔积,也就是返回第一个表中符合查询条件的数据行数,乘以第二个表中符合查询条件的数据行数
比如,Department表中有4个部门,employee表中有4个员工,那么,交叉连接的结果就有16条数据
SELECT * FROM 表1 CROSS JOIN 表2;
交叉连接关键字: CROSS JOIN
交叉连接语法:
SELECT * FROM 表名1 CROSS JOIN 表名2
案例:
CROSS JOIN,用于连接两个要查询的表,通过该语句,可以查询两个表中所有的数据组合
首先,在chapter05数据库中,创建两个表,department表和employee表
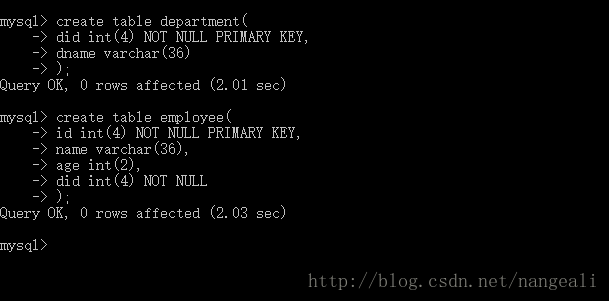
在两个表中,分别插入相关数据
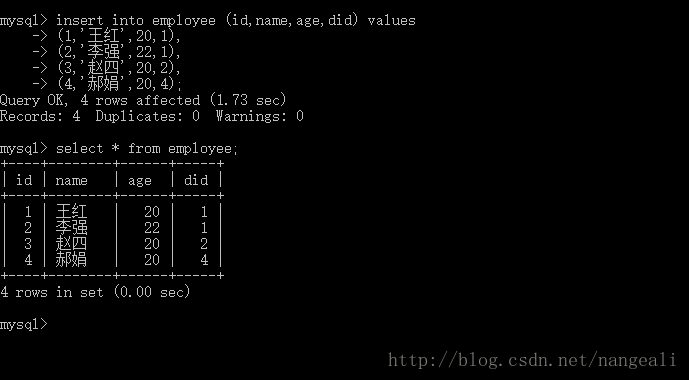
为department表,添加数据

为employee表,添加数据
使用交叉连接,查询部门表和员工表中的所有数据
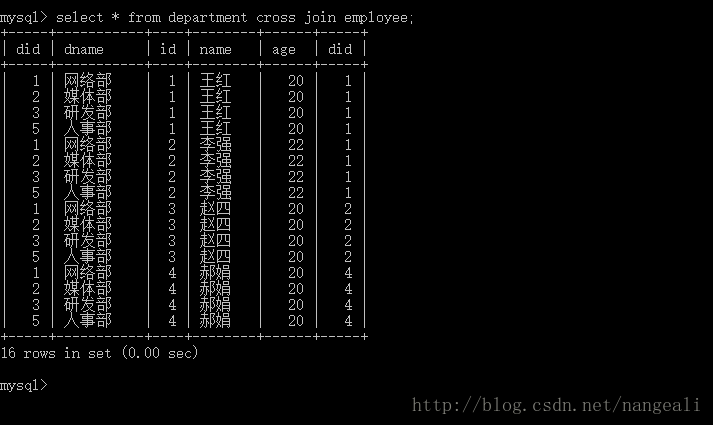
可以看出,交叉连接的结果,就是两个表中所有数据的组合
注意:在实际开发中,这种业务需求是很少见的,一般不会使用交叉连接,而是使用具体的条件,对数据进行有目的的查询
内连接:
内连接也叫等值连接,内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。
数据表内数据如下:
books表:

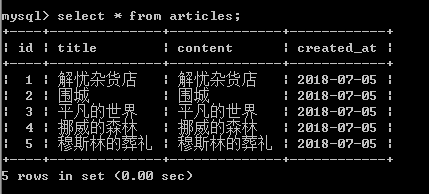
articles表:
内连接的关键字:INNER JOIN
命令执行代码如下:
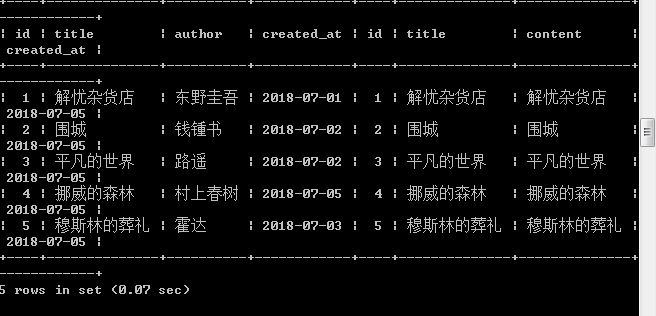
select * from books as b inner join articles as a on b.title=a.title
其中a.title 表示books表中的title字段,b.title表示的articles表中的字段,这行命令的意思是使用mysql中的inner join关键字来连接两张表(books表与articles表)组合两张表的字段并且返回关联字段相对应的字段(a.title=b.title)
运行结果如图下所示:
注意:这里也可以省略inner直接写为join,也能实现上述功能。

inner join 获取的就是两个表中的交集部分
左连接:
左连接关键字:LEFT JOIN
左表:books 右表:articles
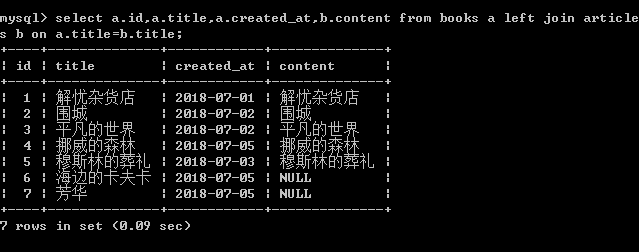
左连接会读取左边数据表的全部数据,即使右边数据表没有对应数据。(如果两个表中数据有相同部分,只显示一个)
右连接:
右连接关键字:
左表:books 右表:articles
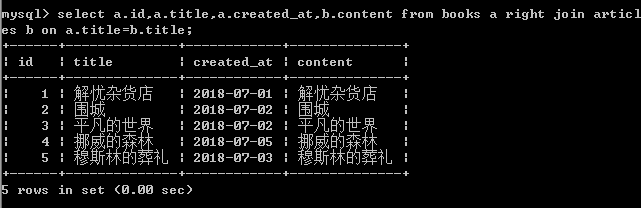
右连接会读取右边数据表的全部数据,即使左边数据表没有对应数据。(如果两个表中数据有相同部分,只显示一个)
分页查询:
分页查询关键字:LIMIT
查询第1条到第10条的数据的sql是:select * from table limit 0,10; ->对应我们的需求就是查询第一页的数据:select * from table limit (1-1)*10,10;
查询第10条到第20条的数据的sql是:select * from table limit 10,10; ->对应我们的需求就是查询第二页的数据:select * from table limit (2-1)*10,10;
查询第20条到第30条的数据的sql是:select * from table limit 20,10; ->对应我们的需求就是查询第三页的数据:select * from table limit (3-1)*10,10;
子查询:
定义
子查询允许把一个查询嵌套在另一个查询当中。
子查询,又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询。
子查询可以包含普通select可以包括的任何子句,比如:distinct、 group by、order by、limit、join和union等;
但是对应的外部查询必须是以下语句之一:select、insert、update、delete。
位置
select 中、from 后、where 中.
group by 和order by 中无实用意义。
MySQL逻辑架构图
MySQL的最重要、最与众不同的特性就是它的存储引擎架构,这种架构将查询处理以及其他系统任务和数据的存储/提取相分离。所带来的好处就是可以在使用时根据性能、特性,以及其他需求来选择数据存储的方式。
下图就是MySQL的逻辑架构图:
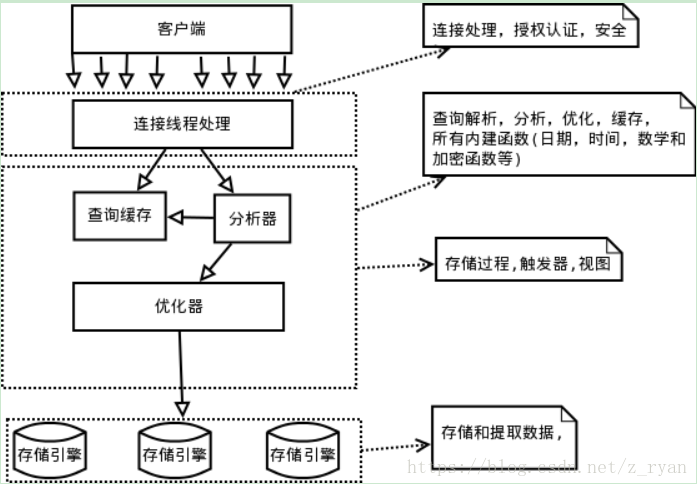
MySQL架构总共三层,在上图中以虚线作为划分。
首先,最上层的服务并不是MySQL独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
第二层的架构包括大多数的MySQL的核心服务。包括:查询解析、分析、优化、缓存以及所有的内置函数(例如:日期、时间、数学和加密函数)。同时,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。服务器通过API和存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明化。存储引擎API包含十几个底层函数,用于执行“开始一个事务”等操作。但存储引擎一般不会去解析SQL(InnoDB会解析外键定义,因为其本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单的响应上层的服务器请求。
更加详细的MySQL系统架构图
看完上图后,大家是不是觉得MySQL的系统架构挺简单的?其实不然。上图只是MySQL系统架构的大的模块图,其实每一层的结构都相当复杂,下图就是详细模块图:
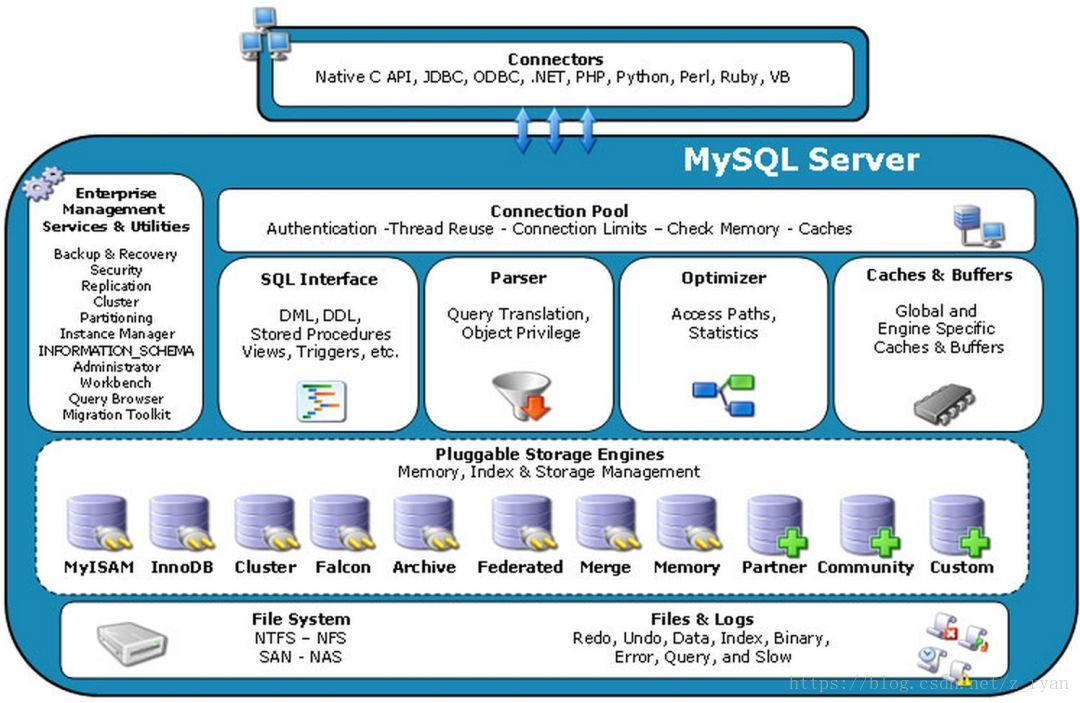
首先,我们对该图中的各个模块做一简单介绍:
1、Connectors
指的是不同语言中与SQL的交互。
2、Connection Pool
管理缓冲用户连接,线程处理等需要缓存的需求。负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到线程管理模块。每一个连接上 MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递 Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的 cache 等。
3、 Management Serveices & Utilities
系统管理和控制工具。
4、 SQL Interface
接受用户的SQL命令,并且返回用户需要查询的结果。
5、 Parser
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。在 MySQL中我们习惯将所有 Client 端发送给 Server 端的命令都称为 query ,在 MySQL Server 里面,连接线程接收到客户端的一个 Query 后,会直接将该 query 传递给专门负责将各种 Query 进行分类然后转发给各个对应的处理模块。
主要功能:
a 、 将SQL语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的;
b、 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的。
6、 Optimizer
查询优化器:SQL语句在查询之前会使用查询优化器对查询进行优化。就是优化客户端请求query,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果。
使用的是“选取-投影-联接”策略进行查询:
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤;然后根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤。最后将这两个查询条件联接起来生成最终查询结果。
7 、Cache和Buffer
查询缓存:主要功能是将客户端提交 给MySQL 的 Select 类 query 请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该 query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。
8 、存储引擎接口
MySQL区别于其他数据库的最重要的特点就是其插件式的表存储引擎。MySQL插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都必需的,如SQL分析器和优化器等,而存储引擎是底层物理结构的实现,每个存储引擎开发者都可以按照自己的意愿来进行开发。
注意:存储引擎是基于表的,而不是数据库。