在上一篇博客,我们介绍了 Map 集合的一种典型实现 HashMap ,在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,相对于早期版本的 JDK HashMap 实现,新增了红黑树作为底层数据结构,在数据量较大且哈希碰撞较多时,能够极大的增加检索的效率。了解 HashMap 的具体实现后,我们再来介绍由 HashMap 作为底层数据结构实现的一种数据结构——HashSet。(如果不了解 HashMap 的实现原理,建议先看看 HashMap,不然直接看 HashSet 是很难看懂的)
1、HashSet 定义
HashSet 是一个由 HashMap 实现的集合。元素无序且不能重复。
1 public class HashSet<E> 2 extends AbstractSet<E> 3 implements Set<E>, Cloneable, java.io.Serializable
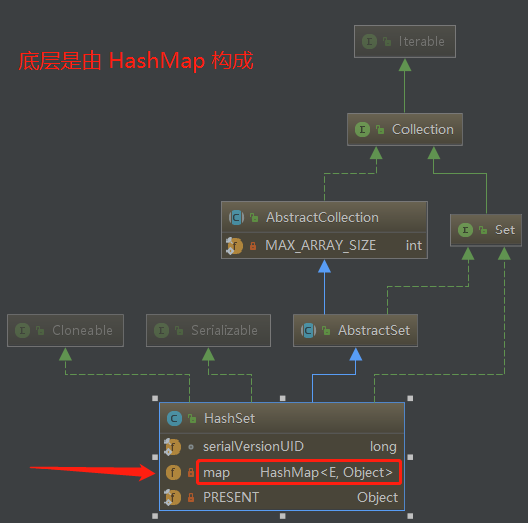
和前面介绍的大多数集合一样,HashSet 也实现了 Cloneable 接口和 Serializable 接口,分别用来支持克隆以及支持序列化。还实现了 Set 接口,该接口定义了 Set 集合类型的一套规范。
2、字段属性
1 //HashSet集合中的内容是通过 HashMap 数据结构来存储的 2 private transient HashMap<E,Object> map; 3 //向HashSet中添加数据,数据在上面的 map 结构是作为 key 存在的,而value统一都是 PRESENT 4 private static final Object PRESENT = new Object();
第一个定义一个 HashMap,作为实现 HashSet 的数据结构;第二个 PRESENT 对象,因为前面讲过 HashMap 是作为键值对 key-value 进行存储的,而 HashSet 不是键值对,那么选择 HashMap 作为实现,其原理就是存储在 HashSet 中的数据 作为 Map 的 key,而 Map 的value 统一为 PRESENT(下面介绍具体实现时会了解)。
3、构造函数
①、无参构造
1 public HashSet() { 2 map = new HashMap<>(); 3 }
直接 new 一个 HashMap 对象出来,采用无参的 HashMap 构造函数,具有默认初始容量(16)和加载因子(0.75)。
②、指定初始容量
1 public HashSet(int initialCapacity) { 2 map = new HashMap<>(initialCapacity); 3 }
③、指定初始容量和加载因子
1 public HashSet(int initialCapacity, float loadFactor) { 2 map = new HashMap<>(initialCapacity, loadFactor); 3 }
④、构造包含指定集合中的元素
1 public HashSet(Collection<? extends E> c) { 2 map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); 3 addAll(c); 4 }
集合容量很好理解,这里我介绍一下什么是加载因子。在 HashMap 中,能够存储元素的数量就是:总的容量*加载因子 ,新增一个元素时,如果HashMap集合中的元素大于前面公式计算的结果了,那么就必须要进行扩容操作,从时间和空间考虑,加载因子一般都选默认的0.75。
4、添加元素
1 public boolean add(E e) { 2 return map.put(e, PRESENT)==null; 3 }
通过 map.put() 方法来添加元素,在上一篇博客介绍该方法时,说明了该方法如果新插入的key不存在,则返回null,如果新插入的key存在,则返回原key对应的value值(注意新插入的value会覆盖原value值)。
也就是说 HashSet 的 add(E e) 方法,会将 e 作为 key,PRESENT 作为 value 插入到 map 集合中,如果 e 不存在,则插入成功返回 true;如果存在,则返回false。
5、删除元素
1 public boolean remove(Object o) { 2 return map.remove(o)==PRESENT; 3 }
调用 HashMap 的remove(Object o) 方法,该方法会首先查找 map 集合中是否存在 o ,如果存在则删除,并返回该值,如果不存在则返回 null。
也就是说 HashSet 的 remove(Object o) 方法,删除成功返回 true,删除的元素不存在会返回 false。
6、查找元素
1 public boolean contains(Object o) { 2 return map.containsKey(o); 3 }
调用 HashMap 的 containsKey(Object o) 方法,找到了返回 true,找不到返回 false。
7、遍历元素
1 HashSet<Integer> set = new HashSet<>(); 2 set.add(1); 3 set.add(2); 4 //增强for循环 5 for(Integer i : set){ 6 System.out.println(i); 7 } 8 //普通for循环 9 Iterator<Integer> iterator = set.iterator(); 10 while (iterator.hasNext()){ 11 System.out.println(iterator.next()); 12 }