一、 基本操作
1. 表操作
1.1 复制建表
create table test as select * from dept; --从已知表复制数据和结构 create table test as select * from dept where 1=2; --从已知表复制结构但不包括数据
1.2 复制插入
insert into test select * from dept;
1.3 创建临时表
临时表是只在会话(SESSION)期间或在事务(TRANSACTION)处理期间存在的表插入数据时,动态分配空间。SESSION级的临时表数据在整个SESSION都存在,直到结束此次 SESSION;而TRANSACTION级的临时表数据在TRANACTION结束后消失,即COMMIT/ROLLBACK或结束SESSION都会清除TRANACTION临时表数据。语法如下:
create global temporary table 临时表名(表定义) on commit preserve|delete rows;
说明:
(1) 用preserve时就是SESSION级的临时表,用delete就是TRANSACTION级的临时表;
(2) SESSION级的临时表,被本次会话使用,删除表时需结束本次会话。
示例:
--创建临时表 create global temporary table temp_dept (dno number, dname varchar2(10)) on commit delete rows; --插入数据 insert into temp_dept values(10,'ABC'); commit; --查询 select * from temp_dept;-- 无数据显示,事务结束时数据自动清除,应在事务前使用 --删除 drop table temp_dept;
二、 运算符
算术运算符:+ - * / 可以在select 语句中使用
连接运算符:|| select deptno|| dname from dept;
比较运算符:> >= = != < <= like between is null in
逻辑运算符:not and or
集合运算符: intersect ,union, union all, minus
select * from emp intersect select * from emp where deptno=10 ;--取交集 select * from emp minus select * from emp where deptno=10;--取差集 select * from emp where deptno=10 union select * from emp where deptno in (10,20); --不包括重复行 select * from emp where deptno=10 union all select * from emp where deptno in (10,20); --包括重复行
【注】集合运算符使用注意事项:
1.对应集合的列数和数据类型相同
2.查询中不能包含long 列
3.列的标签是第一个集合的标签
4.使用order by时,必须使用位置序号,不能使用列名、
三、 常用函数
1. 日期函数
1.1 add_months(d,n)
返回指定日期加(减)指定月份后(前)的日期:
select sysdate S1,add_months(sysdate,-1) S2,add_months(sysdate,1) S3 from dual;--查询当前时间及其前后一个月的时间
1.2 last_day(d)
返回指定日期月的最后一天的日期:
select last_day(sysdate) from dual;
1.3 months_between(d1,d2)
返回日期之间的月份差:
select months_between('13-2月-18','15-10月-17') S3 from dual;
1.4 next_day(d,day)
返回下个星期的日期(day为1-7或星期日-星期六,1表示星期日):
select sysdate S1,next_day(sysdate,1) S2,next_day(sysdate,'星期日') S3 FROM DUAL
1.5 round(d,[fmt])
四舍五入到最接近的日期(不含时间),这里的fmt是可选参数,类似于精确度,默认精确到日,参入day时舍入到最接近的星期日:
select sysdate S1, round(sysdate) S2, round(sysdate, 'year') YEAR, round(sysdate, 'month') MONTH, round(sysdate, 'day') DAY, round(sysdate, 'hh') YEAR, from dual;
1.6 greatest( expr1, ... expr_n )
取得值最大值,数字按大小排 ,字符按首字符比较(如果相等则向下比较),日期则返回最晚日期:
select greatest('01-1月-04','04-1月-04','10-2月-04') from dual;
1.7 extract(expr)
oracle中extract()函数从oracle 9i中引入,用于从一个date或者interval类型中截取到特定的部分。
语法如下:
EXTRACT ( { YEAR | MONTH | DAY | HOUR | MINUTE | SECOND } | { TIMEZONE_HOUR | TIMEZONE_MINUTE } | { TIMEZONE_REGION | TIMEZONE_ABBR } FROM { date_value | interval_value } )
我们只可以从一个date类型中截取 year,month,day(date日期的格式为yyyy-mm-dd); 也只可以从一个 timestamp with time zone 的数据类型中截取TIMEZONE_HOUR和TIMEZONE_MINUTE;获取两个日期之间的具体时间间隔,extract函数是最好的选择。
示例:
select systimestamp s, extract(year from systimestamp) year, extract(month from systimestamp) month, extract(day from systimestamp) day, extract(minute from systimestamp) minute, extract(second from systimestamp) second, extract(timezone_hour from systimestamp) th,--时区:8 extract(timezone_minute from systimestamp) tm, extract(timezone_region from systimestamp) tr, extract(timezone_abbr from systimestamp) ta from dual;

【注】关于TIMEZONE_HOUR、TIMEZONE_MINUTE、TIMEZONE_REGION和TIMEZONE_ABBR,用到时再研究。
2. 数字函数
2.1 取整函数
ceil 向上取整,floor 向下取整:
select ceil(66.6) N1,floor(66.6) N2 from dual;--结果为67和66
2.2 取幂(power) 和 求平方根(sqrt)
select power(3,2) N1,sqrt(9) N2 from dual;
2.3 求余mod(n1,n2)
select mod(9,5) from dual;
2.4 返回固定小数位数
round(num,len)四舍五入,trunc(num,len)直接截断:
select round(66.667,2) N1,trunc(66.667,2) N2 from dual;
2.5 返回值的符号
sign(n),正数返回为1,负数为-1:
select sign(-32),sign(293) from dual;
3. 字符函数
3.1 initcap(st)
返回st将每个单词的首字母大写,所有其他字母小写
3.2 lower(st)
返回st将每个单词的字母全部小写
3.3 upper(st)
返回st将每个单词的字母全部大写
3.4 concat(st1,st2)
返回st为st2接st1的末尾(可用操作符"||")
3.5 lpad(st1,n[,st2])
返回右对齐的st,st为在st1的左边用st2填充直至长度为n,st2的缺省为空格
3.6 rpad(st1,n[,st2])
返回左对齐的st,st为在st1的右边用st2填充直至长度为n,st2的缺省为空格
3.7 ltrim(st[,set])
返回st,st为从左边删除set中字符直到第一个不是set中的字符。缺省时,指的是空格
3.8 rtrim(st[,set])
返回st,st为从右边删除set中字符直到第一个不是set中的字符。缺省时,指的是空格
3.9 replace(st,search_st[,replace_st])
将每次在st中出现的search_st用replace_st替换,返回一个st。缺省时,删除search_st
3.10 substr(st,m[,n])
n=返回st串的子串,从m位置开始,取n个字符长。缺省时,一直返回到st末端
3.11 length(st)
数值,返回st中的字符数
3.12 instr(st1,st2[,m[,n]])
数值,返回st1从第m字符开始,st2第n次出现的位置,m及n的缺省值为1
4. 转换函数
4.1 to_char(type,[fmt])
这里type为date/timestamp/int/float/numeric等,数据类型不同,格式fmt也不同。
4.1.1 日期转字符
select to_char(sysdate) s1,--日-月-年,格式与语言环境有关 to_char(sysdate, 'yyyy-mm-dd') s2, to_char(sysdate, 'yyyy') s3, to_char(sysdate, 'yyyy-mm-dd hh12:mi:ss') s4, to_char(sysdate, 'hh24:mi:ss') s5, to_char(sysdate, 'DAY') s6 from dual;
4.1.2 时间戳转字符
select sysdate, systimestamp, to_char(systimestamp, 'yyyymmdd hh24:mi:ssxff6'), to_char(systimestamp, 'yyyymmdd hh24:mi:ss.ff6'), to_char(timestamp '2011-09-14 12:52:42.123456789', 'YYYY-MM-DD') from dual;
4.1.3 数字转字符
select to_char(88877) s1, to_char(1234567890, '099999999999999') s2,-- 000001234567890 to_char(12345678, '999,999,999,999') s3, to_char(123456, '99.999') s4,--溢出,显示##### to_char(1234567890, '999,999,999,999.9999') s5, to_char(123, 'xx') s6,--十六制,7b to_char(4567, 'xxxx') s7,--11d7 to_char(12345,'$99999') s8,--$12345 to_char(12345.6,'$99,999.00') s9--$12345.60 from dual;
【注】timestamp含义为时间戳,精确到小数秒(fractional_seconds_precision),可以是 0 to 9,缺省是6:
select systimestamp,systimestamp(9) from dual;
4.2 to_date(c,[fmt])
4.3 to_timestamp(c,[fmt])
4.4 to_number(c,[fmt])
5. 分组函数
Oracle中的分组有两种——group by 和partition by:
group by更强调的是一个整体,就是组,只能显示一个组里满足聚合函数的一条记录; partition by 在整体后更强调个体,能显示组里所有个体的记录。
相应的分组函数也可以分为两大类:
5.1 聚合函数
5.1.1 统计方式
5.1.1.1 rollup
按分组的第一个列进行统计和最后的小计:
select t.apply_id, t.disposal_field, count(1) from ebill_dump_apply_detail t group by rollup(t.apply_id, t.disposal_field);
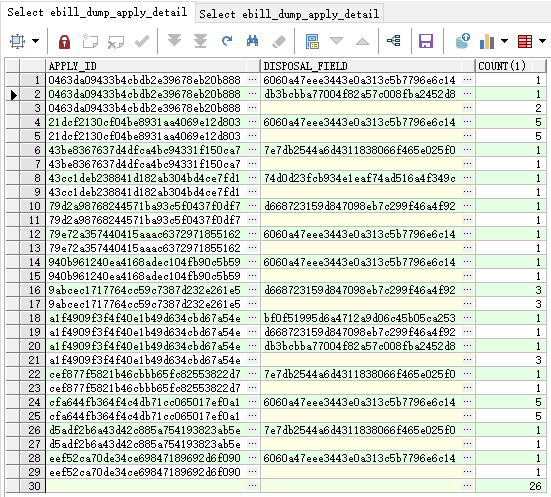
5.1.1.2 cube
按分组的所有列的进行统计和最后的小计:
select t.apply_id, t.disposal_field, count(1) from ebill_dump_apply_detail t group by rollup(t.apply_id, t.disposal_field);
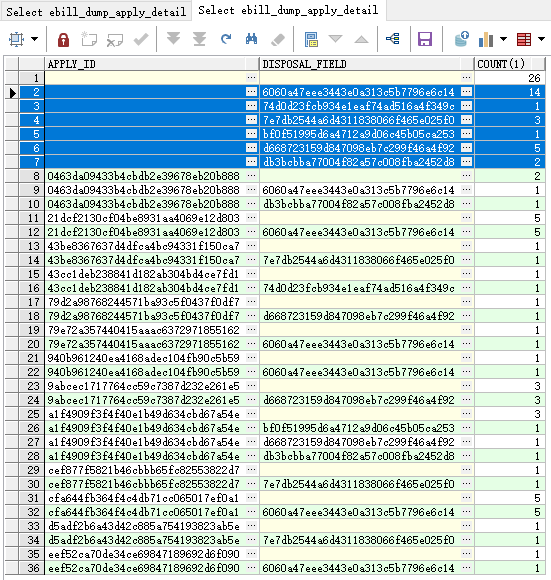
5.2 分析函数
5.2.1 什么是分析函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
5.2.2 分析函数的形式
分析函数的语法结构一般是:分析函数名(参数) OVER (PARTITION BY子句 ORDER BY子句 ROWS/RANGE子句)。
即由以下三部分组成:
分析函数名:如sum、max、min、count、avg等聚集函数以及lead、lag行比较函数等;
over: 关键字,表示前面的函数是分析函数,不是普通的集合函数;
分析子句:over关键字后面挂号内的内容;
分析子句又由下面三部分组成:
partition by :分组子句,表示分析函数的计算范围,不同的组互不相干;
ORDER BY: 排序子句,表示分组后,组内的排序方式;
ROWS/RANGE:窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),此时分析函数的计算范围窗口,而不是PARTITON。窗口有两种,ROWS和RANGE;
示例:
WITH t AS (SELECT (CASE WHEN LEVEL IN (1, 2) THEN 1 WHEN LEVEL IN (4, 5) THEN 6 ELSE LEVEL END) ID FROM dual CONNECT BY LEVEL < 10) SELECT id, SUM(ID) over(ORDER BY ID) default_sum, SUM(ID) over(ORDER BY ID RANGE BETWEEN unbounded preceding AND CURRENT ROW) range_unbound_sum, SUM(ID) over(ORDER BY ID ROWS BETWEEN unbounded preceding AND CURRENT ROW) rows_unbound_sum, SUM(ID) over(ORDER BY ID RANGE BETWEEN 1 preceding AND 2 following) range_sum, SUM(ID) over(ORDER BY ID ROWS BETWEEN 1 preceding AND 2 following) rows_sum FROM t;
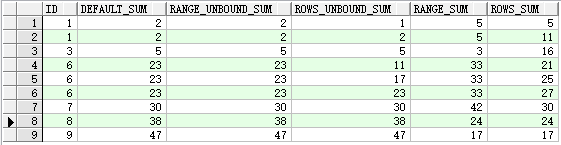
从上面的例子可知:
(1)窗口子句必须和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN unbounded
preceding AND CURRENT ROW,如上例结果集中的defult_sum等于range_unbound_sum;
(2)如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
(3)range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内,如上例中range_sum(即range 1 preceing and 2 following)例的分析结果:
当id=1时,是sum为1-1<=id<=1+2 的和,即sum=1+1+3=5(取id为1,1,3);
当id=3时,是sum为3-1<=id<=3+2 的和,即sum=3(取id为3);
当id=6时,是sum为6-1<=id<=6+2 的和,即sum=6+6+6+7+8=33(取id为6,6,6,7,8);
以此类推下去,结果如上例中所示。
4、rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关),如上例中rows_sum例结果,是取前1行和后2行数据的求和,分析上例rows_sum的结果:
当id=1(第一个1时)时,前一行没数,后二行分别是1和3,sum=1+1+3=5;
当id=3时,前一行id=1,后二行id都为6,则sum=1+3+6+6=16;
以此类推下去,结果如上例所示。
注:行比较分析函数lead和lag无window(窗口)子句。
参考:
http://www.cnblogs.com/lanzi/archive/2010/10/26/1861338.html;
https://www.cnblogs.com/cjm123/p/8033892.html;
http://blog.itpub.net/21251711/viewspace-1068855/;
6. 其他函数
6.1 分支函数
这是我给的分类,凡具有分支判断功能函数都列于此。
6.1.1 DECODE函数
DECODE函数,是ORACLE公司的SQL软件ORACLE PL/SQL所提供的特有函数计算方式。
DECODE的语法:DECODE(value,if1,then1,if2,then2,if3,then3,...,else),表示如果value等于if1时,DECODE函数的结果返回then1,...,如果不等于任何一个if值,则返回else。
需要注意的是,这里的if、then及else 都可以是函数或计算表达式。
6.1.2 NVL函数
NVL函数是Oracle PL/SQL中的一个函数。它的格式是NVL( string1, replace_with)。它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
注意事项:string1和replace_with必须为同一数据类型,除非显式的使用TO_CHAR函数进行类型转换。相当于Sql中的isnull方法。
6.1.3 NVL2函数
Oracle在NVL函数的功能上扩展,提供了NVL2函数。
NVL2(E1, E2, E3)的功能为:如果E1为NULL,则函数返回E3,否则返回E2。相当于.Net中的三元运算符。
6.1.4 NULLIF函数
NULLIF (ex1,ex2),值相等返空,否则返回第一个值。
6.2 TRUNC函数
截取函数,返回按指定要求截取后的数字或日期。
6.2.1 TRUNC(for number)
TRUNC函数返回处理后的数值,其工作机制与ROUND函数极为类似,只是该函数不对指定小数前或后的部分做相应舍入选择处理,而统统截去。
其具体的语法格式如下
TRUNC(number[,decimals])
其中:
number 待做截取处理的数值
decimals 指明需保留小数点后面的位数。可选项,忽略它则截去所有的小数部分
下面是该函数的使用情况:
TRUNC(89.985,2)=89.98
TRUNC(89.985)=89
TRUNC(89.985,-1)=80
注意:第二个参数可以为负数,表示为小数点左边指定位数后面的部分截去,即均以0记。与取整类似,比如参数为1即取整到十分位,如果是-1,则是取整到十位,以此类推。
6.2.2 TRUNC(for dates)
TRUNC函数为指定元素而截去的日期值。
其具体的语法格式如下:
TRUNC(date[,fmt])
其中:
date 一个日期值
fmt 日期格式,该日期将由指定的元素格式所截去。忽略它则由最近的日期截去
下面是该函数的使用情况:
TRUNC(TO_DATE(24-Nov-1999 08:00 pm),dd-mon-yyyyhh:mi am)
=24-Nov-1999 12:00:00 am
TRUNC(TO_DATE(24-Nov-1999 08:37 pm,dd-mon-yyyyhh:mi am),hh) =24-Nov-1999 08:00:00 am
trunc(sysdate,yyyy) --返回当年第一天。
trunc(sysdate,mm) --返回当月第一天。
trunc(sysdate,d) --返回当前星期的第一天。
trunc(sysdate,dd)--返回当前年月日
fmt值参考如下:
|
Unit |
Valid format parameters |
|
Year |
SYYYY, YYYY, YEAR, SYEAR, YYY, YY, Y |
|
ISO Year |
IYYY, IY, I |
|
Quarter |
Q |
|
Month |
MONTH, MON, MM, RM |
|
Week |
WW |
|
IW |
IW |
|
W |
W |
|
Day |
DDD, DD, J |
|
Start day of the week |
DAY, DY, D |
|
Hour |
HH, HH12, HH24 |
|
Minute |
MI |
四、 常用保留字
4.1 user
select user from dual;--返回登录的用户名称
4.2 sysdate
select sysdate from dual;--返回当前系统时间
http://streamsong.iteye.com/blog/1023922