16.1问题形式化
(1)讲推荐系统的原因主要有以下几点:
1.推荐系统是一个很重要的机器学习的应用,虽然在学术界上占比较低,但是在商业应用中非常的重要,占有很高的优先级。
2.传达机器学习的一个大思想:特性是可以学习而来的,不需要人工去选择。
(2)说明的案例:电影推荐系统
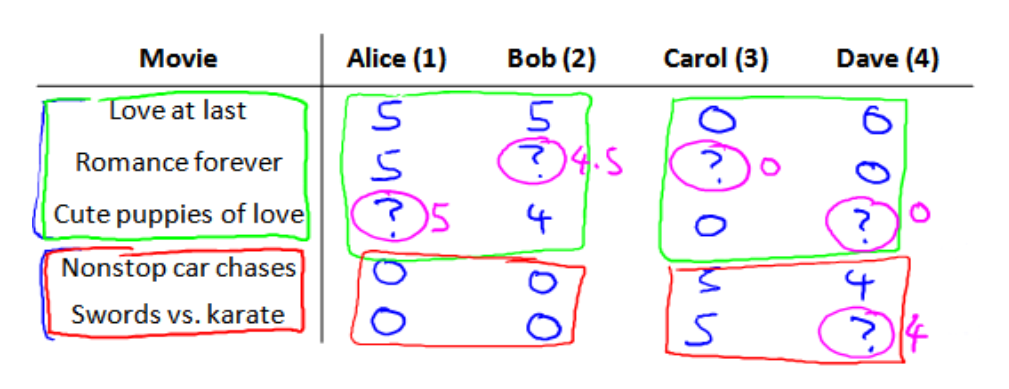
希望创建一个算法来预测每个人可能会给他们没看过的电影打多少分,并以此作为推荐依据。
(3)此外引入一些标记:
nu代表用户的数量,
nm代表电影的数量,
r(i,j)如果用户j给电影i评过分则r(i,j)=1,
y(i,j)代表用户j给电影打的分数,
mj表示用户评分的电影的总数。
16.2基于内容的推荐系统
(1)总结:基于内容其实就是已经有了电影的特征X,然后求拟合的参数θ,后面提到的基于用户,则是已经有了参数θ,来求拟合的电影特征X。
(2)假设每部电影已知特征(基于内容):
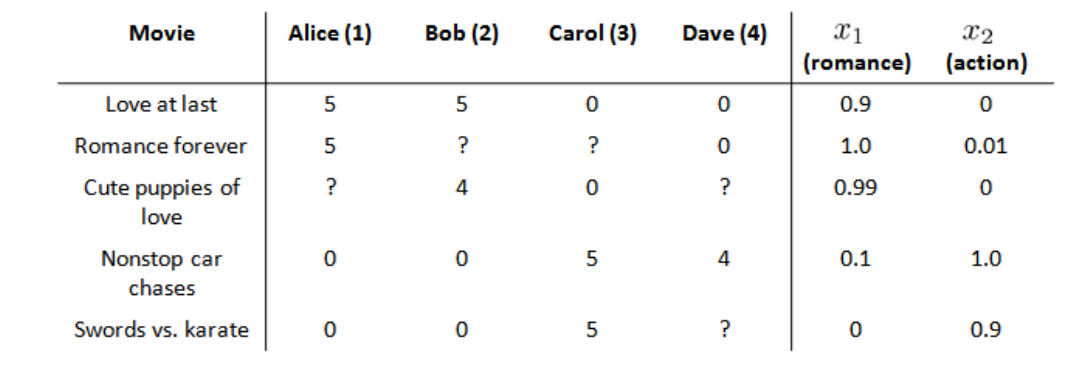
参数说明:θ(j)表示用户j的参数,x(i)表示电影i的特征,
对于用户j和电影i,我们预测评分为:(θ(j))Tx(i)
对于单用户的代价函数(省略了样本数m,对θ0不做正则化,只计算有评分的)如下:
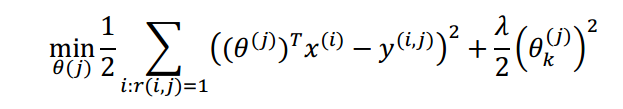
故对于所有用户的代价函数为:
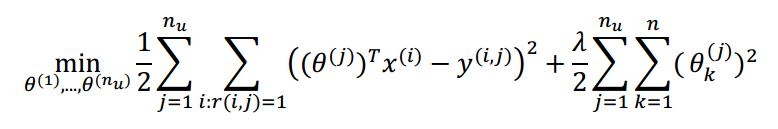
梯度下降式的梯度更新方式: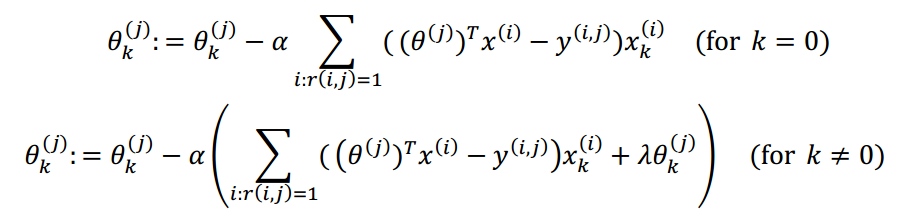
16.3协同过滤
(1)基于用户的(即已知用户的参数θ,求电影特征x),其代价函数为:

(2)协同过滤算法是既不知道特性X,也不知道用户参数θ时同时对二者进行优化。
其代价函数为:
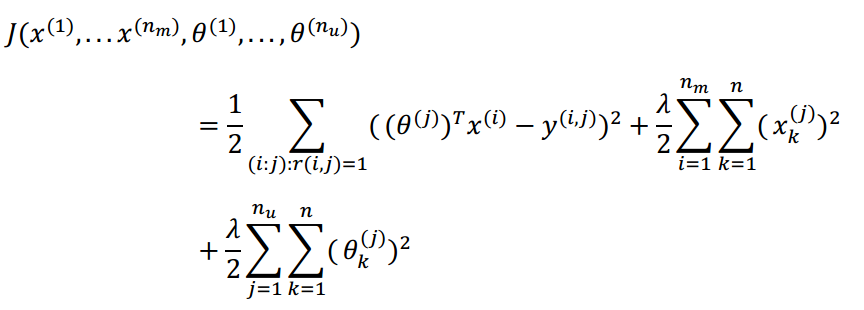
对代价函数求偏导数:
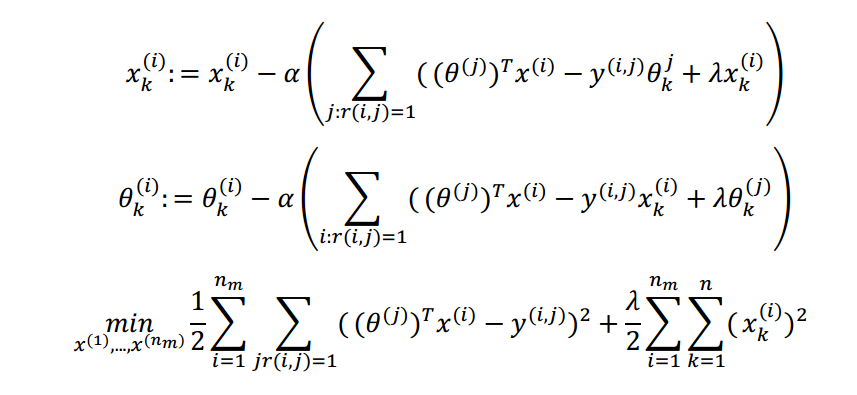
(3)协同过滤的算法步骤:
1.初始化x(1),x(2),……,x(nm),θ(1),θ(1),……,θ(nu)为一些随机小值;
2.使用梯度下降算法最小化代价函数;
3.在训练完算法后,我们预测(θ(j))Tx(i)为用户j给电影i的评分。
(4)如何给用户推荐:
1.根据计算出来的评分,把该用户评分高的电影给该用户;
2.如果用户观看某电影,根据计算电影特征间的相似度,推荐相似的电影给该用户。
16.4协同过滤算法
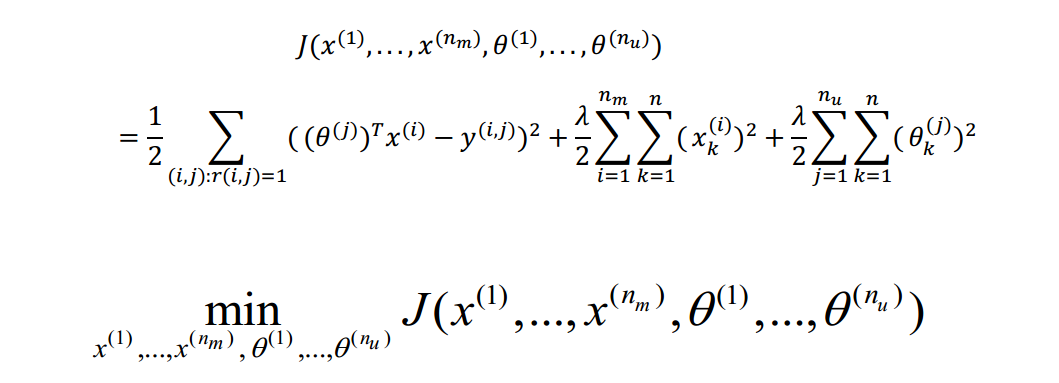
16.5向量化:低秩矩阵分解
将数据集评分存储在矩阵中->通过协同过滤学习得到元素为(θ(j))Tx(i)的预测矩阵->根据电影特征距离求电影间的相似性


16.6推行工作的细节
总结:怎么给新用户推荐电影(会把每部电影的平均分作为该用户的评分)
(1)用户评分数据以及新用户Eve:
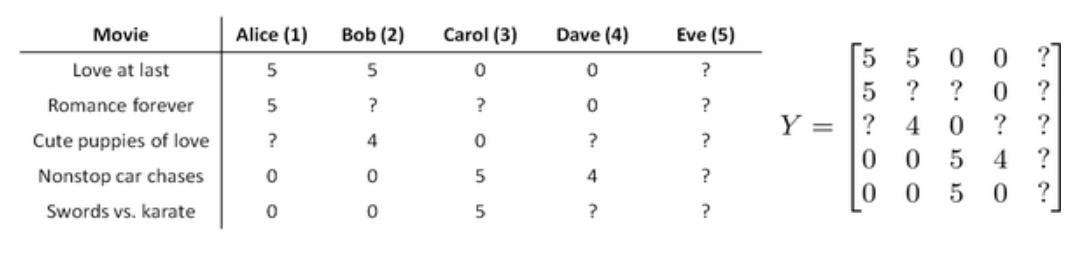
(2)对每部电影做均值归一化,然后作为数据来训练模型
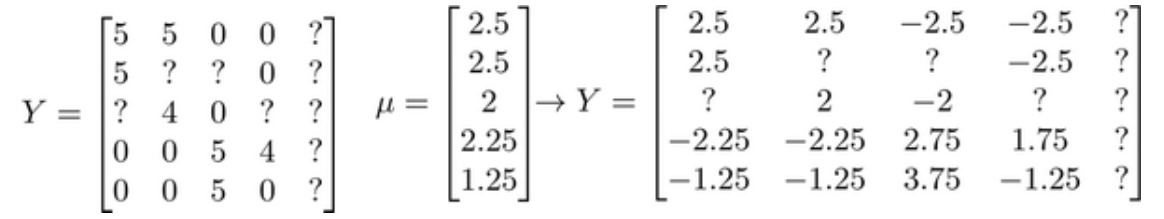
(3)预测的值加上该电影的均值为最终对电影的评分:
![]()
(4)学习到的模型会把每部电影的平均分作为新用户对电影的评分。