2017-10-30 21:49:55
前言:
初步使用scrapy爬虫框架,爬取各个网站信息
系统环境:
64位win10系统,装有64位python3.6,IDE为pycharm,使用cmd命令行工具
预备知识:
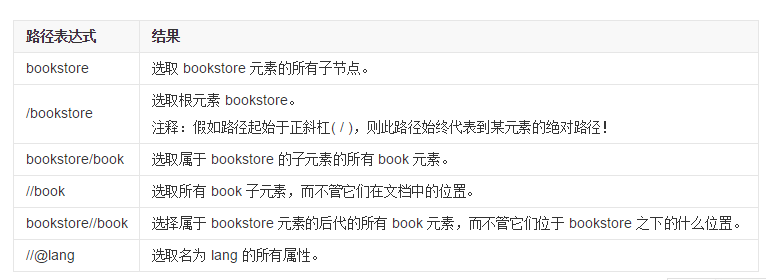
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似,以下是最有用的路径表达式:

代码:
import scrapy class JulyeduSpider(scrapy.Spider): name = 'julyedu' start_urls = ['https://www.julyedu.com/category/index'] def parse(self,response): for julyedu_class in response.xpath('//div[@class="course_info_box"]'): print (julyedu_class.xpath('a/h4/text()').extract_first()) print (julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first()) print (julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()) yield {'title':julyedu_class.xpath('a/h4/text()').extract_first(), 'desc':julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first(), 'time':julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()}
代码解释:
首先建立一个文件名为“julyedu_spider”的py文件,导入scrapy框架,然后创建一个JulyeduSpider的类,名字为'juyedu',start_urls为起始的网址。
然后定义解析网页的方法parse,我们需要获取标题,描述,时间等信息,因此右键检查,
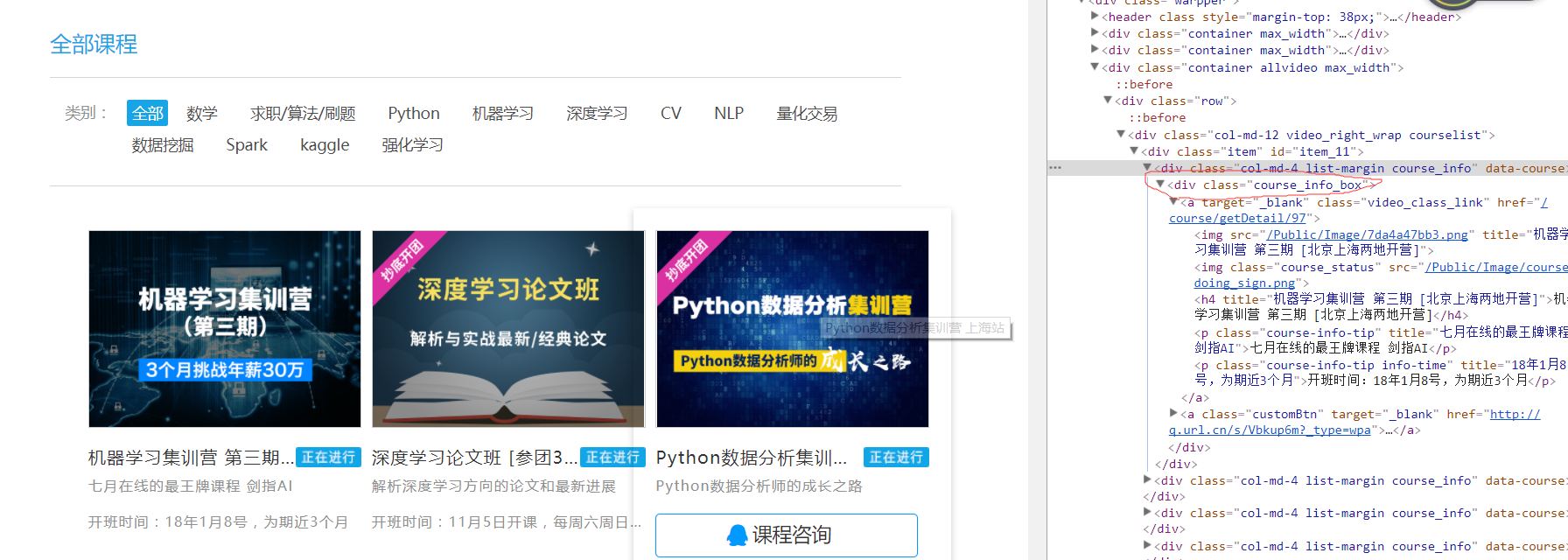
'//div[@class="course_info_box”]'表示选取属性为"course_info_box”标签的子元素,而不管他们的在文档中的位置
'a/h4/text()'表示a标签的子标签h4的文本内容
'a/p[@class="course-info-tip"]/text()'表示a标签的class属性为“..”的p标签的文本内容
'a/p[@class="course-info-tip info-time"]/text()'同理
yield表示创建对应的字典,将数据导入到json,xml,csv等格式的文件中
保存文件后,我们打开cmd窗口,注意要在py文件的目录下打开(按住shift右键即可),输入
scrapy runspider julyedu_spider.py
即可看到打印的内容
再输入
scrapy runspider julyedu_spider.py -o julyedu_class.csv
即可将爬取数据保存到CSV文件中
另外
再补充scrapy shell的用法,同样我们需要在进入项目的根目录,在命令行中输入:
scrapy shell 'https://www.julyedu.com/category/index'
即可加载shell,会获得一个response回应,然后输入
response.xpath('xpath路径')
即可得到所需的内容