正则表达式爬取豆瓣电影TOP前250的中英文名
1、首先要实现网页的数据的爬取。新建test.py文件
test.py
1 import requests
2
3 def get_Html_text(url,p):
4 try:
5 h= {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg}#User-Agent随便进入一个网页F12->Network->选择xxx?xxx,找到自己的User-Agent复制粘贴就好了
6
7 r = requests.get(url,params=p,headers=h)
8 r.raise_for_status()
9 r.encoding=r.apparent_encoding
10 return r.text
11 except:
12 return 'error'
13
14
15
16 if __name__=='__main__':
17 url = 'https://movie.douban.com/top250'
18 for i in range(0,226,25):#实现循环爬取
19 p={'start':str(i),'filter':''}
20 html_text=get_Html_text(url,p)
21 if html_text!='error':
22 with open('c.txt','at',encoding='utf-8') as f:#将文件爬取到的文件写入c.txt中
23 f.write(html_text)
24
2、利用正则表达式规则对爬取到的数据进行筛选,当前我们仅需要中文电影名与英文电影名。
test2.py
1 import re#这里我们需要导入re
2 with open ('c.txt','rt',encoding='utf-8')as f:
3 html_text=f.read()
4 pat=re.compile(r'<span class="title">(.*?)</span>.*?<span class="title"> / (.*?)</span>',re.S)
5 mats=pat.finditer(html_text)
6 for i in mats:
7 print(i.group(1),i.group(2))
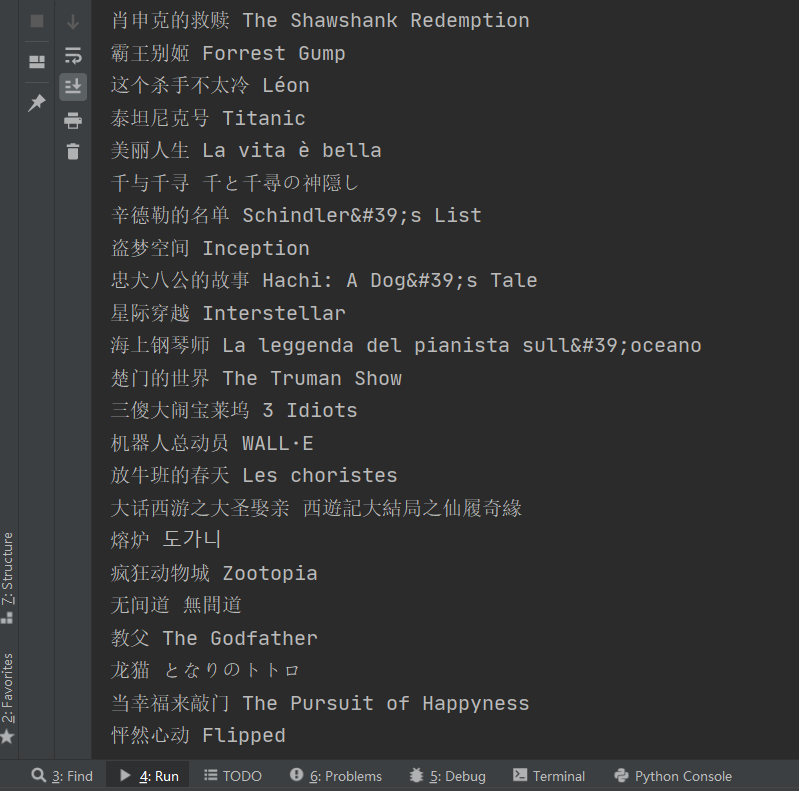
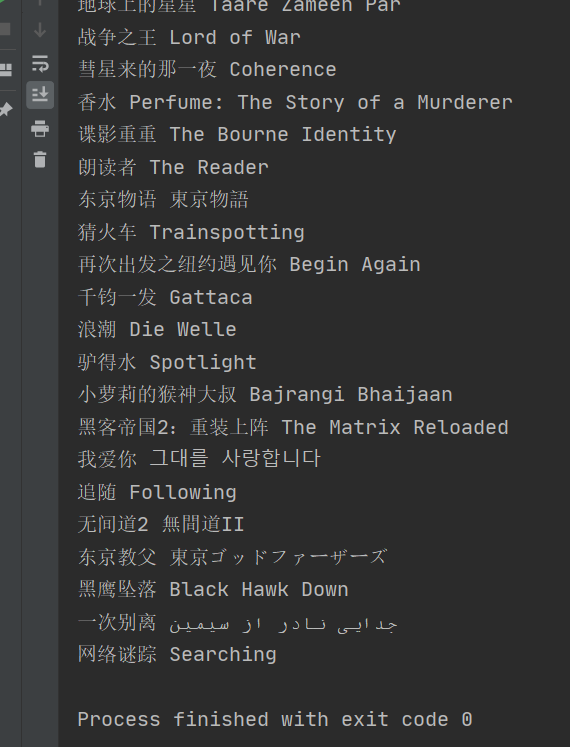
3、运行结果