概念
- 类比mysql
增删改查都是用的json
| elastic | mysql |
|---|---|
| index | database |
| type | table |
| document | row |
| file | column |
| mapping | schema |
| everything | index |
| PUT index/type | insert |
| DELETE index/type | delete |
| PUT index/type | update |
| GET index/type | select |
每个index有10个shard,对应5个primary shade,5个replicate shard
ElasticSearchTemplate的使用
ElasticSearchTemplate更多是对ESRepository的补充,里面提供了一些更底层的方法。
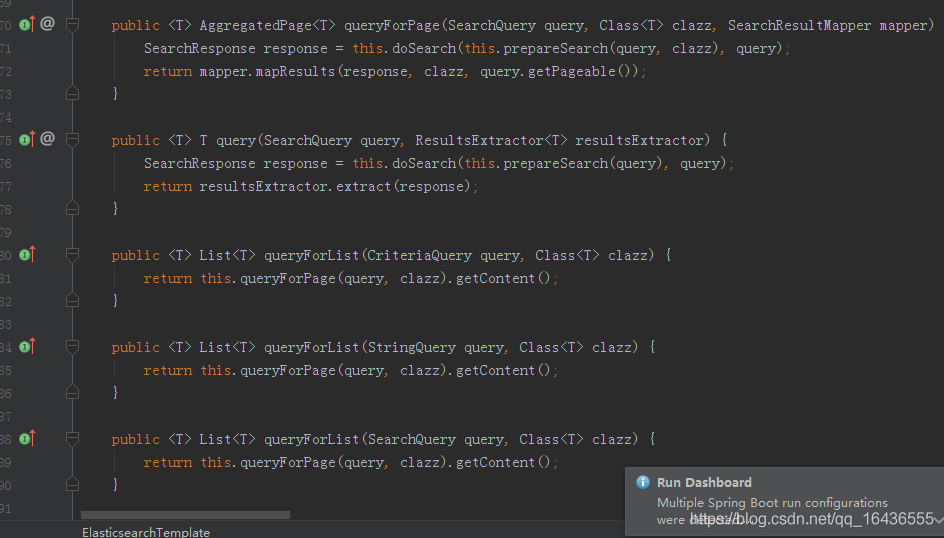
这里主要是一些查询相关的,同样是构建各种SearchQuery条件。
也可以完成add操作
String documentId = "123456"; SampleEntity sampleEntity = new SampleEntity(); sampleEntity.setId(documentId); sampleEntity.setMessage("some message"); IndexQuery indexQuery = new IndexQueryBuilder().withId(sampleEntity.getId()).withObject(sampleEntity).build(); elasticsearchTemplate.index(indexQuery);
add主要是通过index方法来完成,需要构建一个IndexQuery对象

构建这个对象,主要是设置一下id,就是你的对象的id,Object就是对象本身,indexName和type就是在你的对象javaBean上声明的
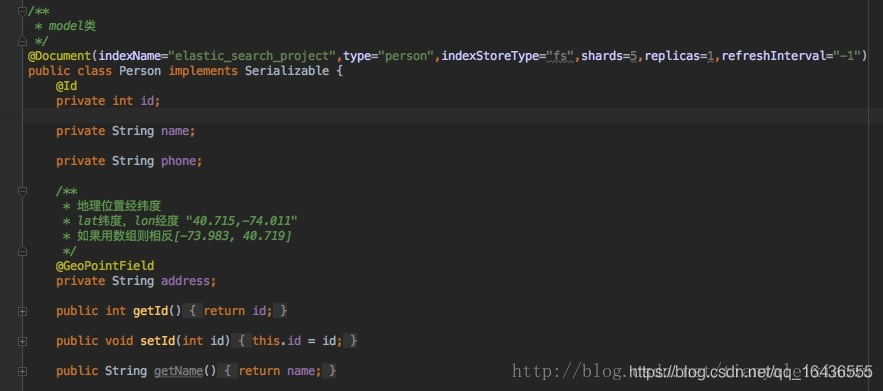
其他的字段自行发掘含义,构建完IndexQuery后就可以通过Template的index方法插入了。
template里还有各种deleteIndex,delete,update等方法,用到的时候就查查看吧。
下面讲一个批量插入的方法,我们经常需要往ElasticSearch中插入大量的测试数据来完成测试搜索,一条一条插肯定是不行的,ES提供了批量插入数据的功能——bulk。
前面讲过JPA的save方法也可以save(List)批量插值,但适用于小数据量,要完成超大数据的插入就要用ES自带的bulk了,可以迅速插入百万级的数据。
public void bulkIndex(List<IndexQuery> queries) { BulkRequestBuilder bulkRequest = this.client.prepareBulk(); Iterator var3 = queries.iterator(); while(var3.hasNext()) { IndexQuery query = (IndexQuery)var3.next(); bulkRequest.add(this.prepareIndex(query)); } BulkResponse bulkResponse = (BulkResponse)bulkRequest.execute().actionGet(); if (bulkResponse.hasFailures()) { Map<String, String> failedDocuments = new HashMap(); BulkItemResponse[] var5 = bulkResponse.getItems(); int var6 = var5.length; for(int var7 = 0; var7 < var6; ++var7) { BulkItemResponse item = var5[var7]; if (item.isFailed()) { failedDocuments.put(item.getId(), item.getFailureMessage()); } } throw new ElasticsearchException("Bulk indexing has failures. Use ElasticsearchException.getFailedDocuments() for detailed messages [" + failedDocuments + "]", failedDocuments); } } public void bulkUpdate(List<UpdateQuery> queries) { BulkRequestBuilder bulkRequest = this.client.prepareBulk(); Iterator var3 = queries.iterator(); while(var3.hasNext()) { UpdateQuery query = (UpdateQuery)var3.next(); bulkRequest.add(this.prepareUpdate(query)); } BulkResponse bulkResponse = (BulkResponse)bulkRequest.execute().actionGet(); if (bulkResponse.hasFailures()) { Map<String, String> failedDocuments = new HashMap(); BulkItemResponse[] var5 = bulkResponse.getItems(); int var6 = var5.length; for(int var7 = 0; var7 < var6; ++var7) { BulkItemResponse item = var5[var7]; if (item.isFailed()) { failedDocuments.put(item.getId(), item.getFailureMessage()); } } throw new ElasticsearchException("Bulk indexing has failures. Use ElasticsearchException.getFailedDocuments() for detailed messages [" + failedDocuments + "]", failedDocuments); } }
和index插入单条数据一样,这里需要的是List仅此而已,是不是很简单。
/*** * 批量插入数据 */ @GetMapping(value = "/batchInsert") public void batchInsert(){ int counter = 0; //判断index 是否存在 if (!template.indexExists(CAR_INDEX_NAME)) { template.createIndex(CAR_INDEX_NAME); } Gson gson = new Gson(); List<IndexQuery> queries = new ArrayList<IndexQuery>(); List<Car> cars = this.assembleTestData(); if(cars != null && cars.size()>0){ for (Car car : cars) { IndexQuery indexQuery = new IndexQuery(); indexQuery.setId(car.getId().toString()); indexQuery.setSource(gson.toJson(car)); indexQuery.setIndexName(CAR_INDEX_NAME); indexQuery.setType(CAR_INDEX_TYPE); queries.add(indexQuery); //分批提交索引 if (counter % 500 == 0) { template.bulkIndex(queries); queries.clear(); System.out.println("bulkIndex counter : " + counter); } counter++; } } //不足批的索引最后不要忘记提交 if (queries.size() > 0) { template.bulkIndex(queries); } template.refresh(CAR_INDEX_NAME); }
这里是创建了100万个对象,每到500就用bulkIndex插入一次,速度飞快,以秒的速度插入了百万数据。
OK,这篇主要是讲一些ElasticSearchRepository和ElasticSearchTemplate的用法,构造QueryBuilder的方式
``
转载:https://blog.csdn.net/tianyaleixiaowu/article/details/76149547