前言
ClientTimeout 是设置整个会话的超时时间,默认情况下是300秒(5分钟)超时。
ClientTimeout
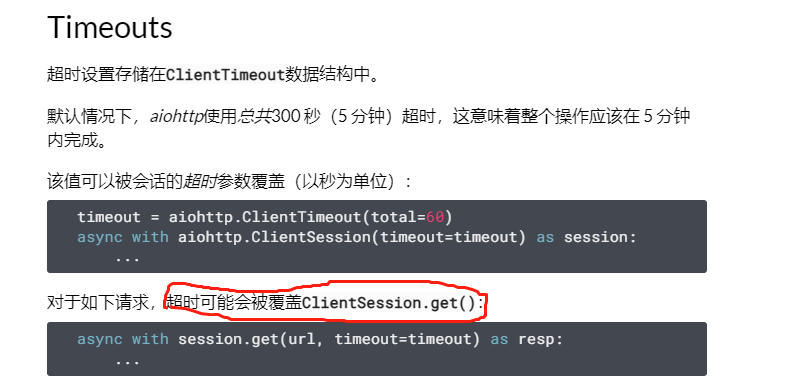
默认情况下,aiohttp使用总共300 秒(5 分钟)超时,这意味着整个操作应该在 5 分钟内完成。
timeout = aiohttp.ClientTimeout(total=60)
async with aiohttp.ClientSession(timeout=timeout) as session:
...
对于如下对session会话发单个请求,超时可能会被覆盖ClientSession.get():
async with session.get(url, timeout=timeout) as resp:
...
ClientTimeout 可以支持的字段
- total 整个操作的最大秒数,包括建立连接、发送请求和读取响应。
- connect 如果超出池连接限制,则建立新连接或等待池中的空闲连接的最大秒数。
- sock_connect 为新连接连接到对等点的最大秒数,不是从池中给出的。
- sock_read 从对等点读取新数据部分之间允许的最大秒数。
默认超时为:
aiohttp.ClientTimeout(total=5*60, connect=None,
sock_connect=None, sock_read=None)

实例
timeout参数是对整个aiohttp.ClientSession 会话的超时时间,比如我创建一个会话,里面有10个请求。
设置超时时间为3秒,那么从创建会话开始,在3秒内完成所有的请求就不会报错,当大于3秒还没完成10个请求就会抛异常
import aiohttp
import asyncio
from pathlib import Path
async def down_img(session, url):
"""下载图片"""
name = url.split('/')[-1] # 获得图片名字
img = await session.get(url)
# 触发到await就切换,等待get到数据
content = await img.read()
# 读取内容
with open('./down_img/'+str(name), 'wb') as f:
# 写入至文件
f.write(content)
print(f'{name} 下载完成!')
return str(url)
async def main(URL):
# 建立会话session
timeout = aiohttp.ClientTimeout(total=3)
conn = aiohttp.TCPConnector(ssl=False) # 防止ssl报错
async with aiohttp.ClientSession(timeout=timeout, connector=conn) as session:
# 建立所有任务
tasks = [asyncio.create_task(down_img(session, img_url)) for img_url in URL]
# 触发await,等待任务完成
done, pending = await asyncio.wait(tasks)
# all_results = [done_task.result() for done_task in done]
# # 获取所有结果
# print("ALL RESULT:"+str(all_results))
URL = [
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
'https://cdn.pixabay.com/photo/2018/03/12/20/07/maldives-3220702_960_720.jpg',
'https://cdn.pixabay.com/photo/2017/08/04/17/56/dolomites-2580866_960_720.jpg',
'https://cdn.pixabay.com/photo/2016/06/20/03/15/pier-1467984_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/07/30/02/00/iceberg-404966_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/11/02/10/41/plane-513641_960_720.jpg',
'https://cdn.pixabay.com/photo/2015/10/30/20/13/sea-1014710_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
]
fp = Path('./down_img')
if not fp.exists():
fp.mkdir()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(URL))
由于3秒内没完成所有的请求,运行结果会抛出异常:asyncio.TimeoutError
sea-1014710_960_720.jpg 下载完成!
railroad-163518_960_720.jpg 下载完成!
plane-513641_960_720.jpg 下载完成!
iceberg-404966_960_720.jpg 下载完成!
Task exception was never retrieved
future: <Task finished name='Task-2' coro=<down_img() done, defined at D:/demo/demo/new/xuexi/d1.py:6> exception=TimeoutError()>
Traceback (most recent call last):
File "D:/demo/demo/new/xuexi/d1.py", line 12, in down_img
content = await img.read()
...
raise asyncio.TimeoutError from None
asyncio.exceptions.TimeoutError
给单个请求添加timeout
如果我们的需求是每个请求设置超时,单个请求大于3秒就超时,把timeout参数放到get请求上
timeout = aiohttp.ClientTimeout(total=3)
img = await session.get(url, timeout=timeout)
完整的代码
import aiohttp
import asyncio
from pathlib import Path
async def down_img(session, url):
"""下载图片"""
name = url.split('/')[-1] # 获得图片名字
timeout = aiohttp.ClientTimeout(total=3)
img = await session.get(url, timeout=timeout)
# 触发到await就切换,等待get到数据
content = await img.read()
# 读取内容
with open('./down_img/'+str(name), 'wb') as f:
# 写入至文件
f.write(content)
print(f'{name} 下载完成!')
return str(url)
async def main(URL):
# 建立会话session
conn = aiohttp.TCPConnector(ssl=False) # 防止ssl报错
async with aiohttp.ClientSession(connector=conn) as session:
# 建立所有任务
tasks = [asyncio.create_task(down_img(session, img_url)) for img_url in URL]
# 触发await,等待任务完成
done, pending = await asyncio.wait(tasks)
# all_results = [done_task.result() for done_task in done]
# # 获取所有结果
# print("ALL RESULT:"+str(all_results))
URL = [
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
'https://cdn.pixabay.com/photo/2018/03/12/20/07/maldives-3220702_960_720.jpg',
'https://cdn.pixabay.com/photo/2017/08/04/17/56/dolomites-2580866_960_720.jpg',
'https://cdn.pixabay.com/photo/2016/06/20/03/15/pier-1467984_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/07/30/02/00/iceberg-404966_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/11/02/10/41/plane-513641_960_720.jpg',
'https://cdn.pixabay.com/photo/2015/10/30/20/13/sea-1014710_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
]
fp = Path('./down_img')
if not fp.exists():
fp.mkdir()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(URL))
这样写其实并不会达到我们的预期,官方文档上说对于如下请求,超时可能会被覆盖ClientSession.get()
那你timeout不管放在ClientSession() 还是单个get/post请求里,其实效果都一样,都是针对整个会话超时。
捕获超时异常 asyncio.TimeoutError
触发的超时异常是 asyncio.TimeoutError,从Traceback可以看到是content = await img.read() 这里报错
import aiohttp
import asyncio
from pathlib import Path
async def down_img(session, url):
"""下载图片"""
name = url.split('/')[-1] # 获得图片名字
try:
img = await session.get(url)
# 触发到await就切换,等待get到数据
content = await img.read()
# 读取内容
with open('./down_img/'+str(name), 'wb') as f:
# 写入至文件
f.write(content)
print(f'{name} 下载完成!')
return str(url)
except asyncio.TimeoutError as msg:
print('timeout: '+str(url))
return str(url)
async def main(URL):
# 建立会话session
timeout = aiohttp.ClientTimeout(total=3)
conn = aiohttp.TCPConnector(ssl=False) # 防止ssl报错
async with aiohttp.ClientSession(timeout=timeout, connector=conn) as session:
# 建立所有任务
tasks = [asyncio.create_task(down_img(session, img_url)) for img_url in URL]
# 触发await,等待任务完成
done, pending = await asyncio.wait(tasks)
# all_results = [done_task.result() for done_task in done]
# # 获取所有结果
# print("ALL RESULT:"+str(all_results))
URL = [
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
'https://cdn.pixabay.com/photo/2018/03/12/20/07/maldives-3220702_960_720.jpg',
'https://cdn.pixabay.com/photo/2017/08/04/17/56/dolomites-2580866_960_720.jpg',
'https://cdn.pixabay.com/photo/2016/06/20/03/15/pier-1467984_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/07/30/02/00/iceberg-404966_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/11/02/10/41/plane-513641_960_720.jpg',
'https://cdn.pixabay.com/photo/2015/10/30/20/13/sea-1014710_960_720.jpg',
'https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg',
'https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg',
]
fp = Path('./down_img')
if not fp.exists():
fp.mkdir()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(URL))
运行结果:
plane-513641_960_720.jpg 下载完成!
maldives-3220702_960_720.jpg 下载完成!
sea-1014710_960_720.jpg 下载完成!
dolomites-2580866_960_720.jpg 下载完成!
iceberg-404966_960_720.jpg 下载完成!
mountain-477832_960_720.jpg 下载完成!
timeout: https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg
timeout: https://cdn.pixabay.com/photo/2016/06/20/03/15/pier-1467984_960_720.jpg
timeout: https://cdn.pixabay.com/photo/2013/07/18/10/56/railroad-163518_960_720.jpg
timeout: https://cdn.pixabay.com/photo/2014/10/07/13/48/mountain-477832_960_720.jpg