前言
使用 pytest.mark.parametrize 参数化的时候,加 ids 参数用例描述有中文时,在控制台输出会显示unicode编码,中文不能正常显示。
使用 pytest_collection_modifyitems 钩子函数,对输出的 item.name 和 item.nodeid 重新编码。
问题描述
参数化 ids 用例描述有中文
import pytest
# test_ids.py
import pytest
# 作者:上海-悠悠
def login(username, password):
'''登录'''
# 返回
return {"code": 0, "msg": "success!"}
# 测试数据
test_datas = [
({"username": "yoyo1", "password": "123456"}, "success!"),
({"username": "yoyo2", "password": "123456"}, "success!"),
({"username": "yoyo3", "password": "123456"}, "success!"),
]
@pytest.mark.parametrize("test_input,expected",
test_datas,
ids=[
"输入正确账号,密码,登录成功",
"输入错误账号,密码,登录失败",
"输入正确账号,密码,登录成功",
]
)
def test_login(test_input, expected):
'''测试登录用例'''
# 获取函数返回结果
result = login(test_input["username"], test_input["password"])
# 断言
assert result["msg"] == expected
cmd终端运行 pytest test_ids.py -v
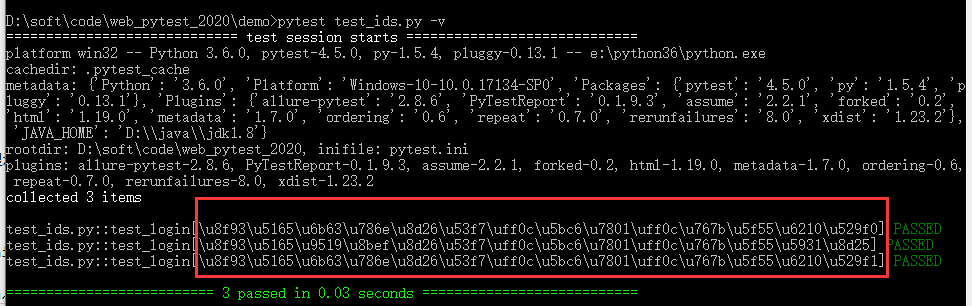
注意 [u8f93u5165u6b63 ...] 这种不叫乱码,这叫 unicode 编码
pytest_collection_modifyitems
在项目的根目录写个 conftest.py 文件,加以下代码
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的item的name和nodeid的中文显示在控制台上
:return:
"""
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
print(item.nodeid)
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
cmd 控制台重新运行
