开心一刻
女孩睡醒玩手机,收到男孩发来一条信息:我要去跟我喜欢的人表白了!
女孩的心猛的一痛,回了条信息:去吧,祝你好运!
男孩回了句:但是我没有勇气说不来,怕被打!
女孩:没事的,我相信你!此时女孩已经伤心的流泪了
男孩:我已经到她家门口了,不敢敲门!
女孩擦了擦眼泪:不用怕,你是个好人,会有好报的!
男孩:那你来开下门吧,我在你家门口!
女孩不敢相信,赶紧跑去开门,看到他的那一刻伤心的泪水变成了感动
男孩拿出手里那束玫瑰花说:你姐姐在家吗?

前情回归
一般来讲,读写分离无非两种实现方式。第一种是依靠数据库中间件(比如:MyCat),也就是说应用程序连接到中间件,中间件帮我们做读写分离;第二种是应用程序自己做读写分离,结合 Spring AOP 实现读写分离
数据库中间件的方式不做过多的阐述(谁让你是配角!),有兴趣的可以去查看
spring集成mybatis实现mysql读写分离,简单介绍了通过 Spring AOP 从应用程序层面实现读写分离;读写分离效果是达到了,可我们知道为什么那么做就能实现读写分离吗 ?知道的请快点走开

接下来请好好欣赏我的表演
原理解密
我们逐个讲解其中涉及的点,然后串起来理解读写分离的底层原理
Spring AOP
AOP:Aspect Oriented Program
关于 Spring AOP,相信大家耳熟能详,它是对 OOP 的一种补充,OOP 是纵向的,AOP 则是横向的

如上图所示,OOP 属于一种纵向拓展,AOP 则是一种横向拓展。AOP 依托于 OOP,将公共功能代码抽象出来作为一个切面,减少重复代码量,降低耦合
AOP 的底层实现是动态代理,具体的表现形式粗略如下

对 Spring AOP 有个大致了解了,我们就可以接着往下看了
Spring 数据源
无论是 Spring JDBC,还是 Hibernate,亦或是 MyBatis,其实都是对 JDBC 的封装;对于JDBC,我们不要太熟,大体流程如下

然而,在实际应用中,我们往往不会直接使用 JDBC,而是使用 ORM,ORM 会封装上述的流程,也就说我们不再需要关注了;MyBatis 使用步骤大致如下

我们以 SpringBoot + pagehelper + Druid(ssm) 为例,来看看具体是怎么获取 Connection 对象的
可以看到,如果事务管理器中存在 Connection 对象,则直接返回,否则从数据源中获取返回(同时也赋值给了事务管理器);当取到 Connection 对象后,后续的流程大家就非常清楚了
然而我们不需要关注 Connection 对象,只需要关注数据源,为什么呢 ? 因为我们的配置文件中配置的是数据源而不是 Connection,是不是很有道理 ?
ThreadLocal
如果我们需要在各层之间进行参数的传递,实现方式有哪些 ?
最常见的方式可能就是方法参数,但还有一种容易忽略的方式:ThreadLocal,可以在当前线程内传递参数,减少方法的参数个数
关于 ThreadLocal,有兴趣的可以查看:结合ThreadLocal来看spring事务源码,感受下清泉般的洗涤!
当我们熟悉上面的三点后,后面的就好理解了,接着往下看
动态数据源
一个数据源只能对应一个数据库,如果我们有多个数据库(一主多从),那么就需要配置多个数据源,类似如下


<!-- master数据源 --> <bean id="masterDataSource" class="com.alibaba.druid.pool.DruidDataSource"> <!-- 基本属性 url、user、password --> <property name="driverClassName" value="${jdbc.driverClassName}" /> <property name="url" value="${jdbc.url}" /> <property name="username" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> <property name="initialSize" value="${jdbc.initialSize}" /> <property name="minIdle" value="${jdbc.minIdle}" /> <property name="maxActive" value="${jdbc.maxActive}" /> <property name="maxWait" value="${jdbc.maxWait}" /> <!-- 超过时间限制是否回收 --> <property name="removeAbandoned" value="${jdbc.removeAbandoned}" /> <!-- 超过时间限制多长; --> <property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}" /> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}" /> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}" /> <!-- 用来检测连接是否有效的sql,要求是一个查询语句--> <property name="validationQuery" value="${jdbc.validationQuery}" /> <!-- 申请连接的时候检测 --> <property name="testWhileIdle" value="${jdbc.testWhileIdle}" /> <!-- 申请连接时执行validationQuery检测连接是否有效,配置为true会降低性能 --> <property name="testOnBorrow" value="${jdbc.testOnBorrow}" /> <!-- 归还连接时执行validationQuery检测连接是否有效,配置为true会降低性能 --> <property name="testOnReturn" value="${jdbc.testOnReturn}" /> </bean> <!-- slave数据源 --> <bean id="slaveDataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="${slave.jdbc.driverClassName}" /> <property name="url" value="${slave.jdbc.url}" /> <property name="username" value="${slave.jdbc.username}" /> <property name="password" value="${slave.jdbc.password}" /> <property name="initialSize" value="${slave.jdbc.initialSize}" /> <property name="minIdle" value="${slave.jdbc.minIdle}" /> <property name="maxActive" value="${slave.jdbc.maxActive}" /> <property name="maxWait" value="${slave.jdbc.maxWait}" /> <property name="removeAbandoned" value="${slave.jdbc.removeAbandoned}" /> <property name="removeAbandonedTimeout" value="${slave.jdbc.removeAbandonedTimeout}" /> <property name="timeBetweenEvictionRunsMillis" value="${slave.jdbc.timeBetweenEvictionRunsMillis}" /> <property name="minEvictableIdleTimeMillis" value="${slave.jdbc.minEvictableIdleTimeMillis}" /> <property name="validationQuery" value="${slave.jdbc.validationQuery}" /> <property name="testWhileIdle" value="${slave.jdbc.testWhileIdle}" /> <property name="testOnBorrow" value="${slave.jdbc.testOnBorrow}" /> <property name="testOnReturn" value="${slave.jdbc.testOnReturn}" /> </bean>
可是事务管理器中只有一个数据源的引用
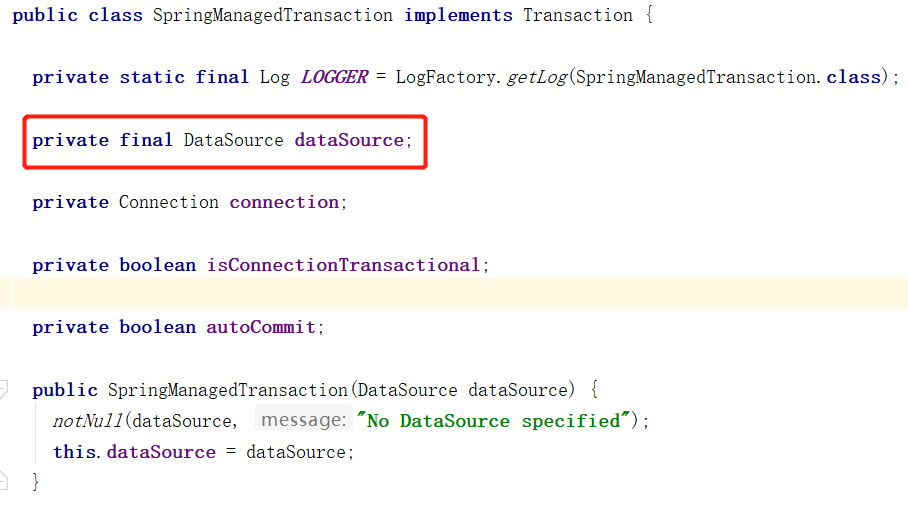
那怎么对应我们配置文件中的多个数据源呢 ?其实,我们可以自定义一个类 DynamicDataSource 来实现 DataSource,DynamicDataSource 中存储我们配置的多数据源,然后将 DynamicDataSource 的实例配置给事务管理器;当从事务管理器获取 Connection 对象的时候,会从 DynamicDataSource 实例获取,然后再由 DynamicDataSource 根据 routeKey 路由到某个具体的数据源,从中获取 Connection;大体流程如下

Spring 也考虑到了这一点,提供了一个抽象类:AbstractRoutingDataSource,DynamicDataSource 继承它可以为我们省非常多的代码
public class DynamicDataSource extends AbstractRoutingDataSource { /** * 获取与数据源相关的key 此key是Map<String,DataSource> resolvedDataSources 中与数据源绑定的key值 * 在通过determineTargetDataSource获取目标数据源时使用 */ @Override protected Object determineCurrentLookupKey() { return HandleDataSource.getDataSource(); } }
配置文件中增加如下配置
<!-- 动态数据源,根据service接口上的注解来决定取哪个数据源 --> <bean id="dataSource" class="com.yzb.util.DynamicDataSource"> <property name="targetDataSources"> <map key-type="java.lang.String"> <!-- write or slave --> <entry key="slave" value-ref="slaveDataSource"/> <!-- read or master --> <entry key="master" value-ref="masterDataSource"/> </map> </property> <property name="defaultTargetDataSource" ref="masterDataSource"/> </bean> <!-- Mybatis文件 --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="configLocation" value="classpath:mybatis-config.xml" /> <property name="dataSource" ref="dataSource" /> <!-- 映射文件路径 --> <property name="mapperLocations" value="classpath*:dbmappers/*.xml" /> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.yzb.dao" /> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" /> </bean> <!-- 事务管理器 --> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean>
但是问题又来了,这个 routeKey 怎么处理,也就说 DynamicDataSource 怎么知道用哪个数据源 ? AbstractRoutingDataSource 提供了一个方法: determineCurrentLookupKey 我们只需要实现它,DynamicDataSource 就知道是使用哪个 lookupKey (routeKey 在 Spring 中的命名)了;determineCurrentLookupKey 具体该如何实现了,我们可以结合 ThreadLocal 来实现;整个流程大致如下

一旦我们在切面中指定了 lookupKey,那么后续就会使用 lookupKey 对应的数据源来操作数据库了
自此,相信大家已经明白了动态数据源的底层原理
总结
Spring AOP → 将我们指定的 lookupKey 放入 ThreadLocal
ThreadLocal → 线程内共享 lookupKey
DynamicDataSource → 对多数据源进行封装,根据 ThreadLocal 中的 lookupKey 动态选择具体的数据源
如果我们对其中的某个环节不懂,可以试着删掉它,然后看这个流程能否正常串起来,这样就能明白各个环节的作用了
Springboot 版示例代码:spring-boot-dynamic-DataSource
悬念
Spring AOP 实现多数据源,是否与 Spring 事务冲突 ,若冲突了该如何解决 ?