前言
开心一刻
一个女人自朋友圈写道:我家老公昨天和别人家的老婆出去旅游,迄今未归,我则被别人家的老公折腾了一天,好累哦!
圈子下面,评论无数,老公在下面评论到:能不能好好说话,我只不过陪女儿去毕业旅游行,而你负责在家留守,照顾三岁儿子,要不要写的这么刺激、让人浮想联翩的? 你是不是有点虎?

诺维斯基:你往哪射了?
周子瑜:我只是个娱乐明星,射箭我不是专业的...
路漫漫其修远兮,吾将上下而求索!
github:https://github.com/youzhibing
码云(gitee):https://gitee.com/youzhibing
前情回顾
通过前面的两篇博文:Mycat - 实现数据库的读写分离与高可用 和 Mycat - 高可用与负载均衡实现,满满的干货!,我们完成了如下图所示的组件部署
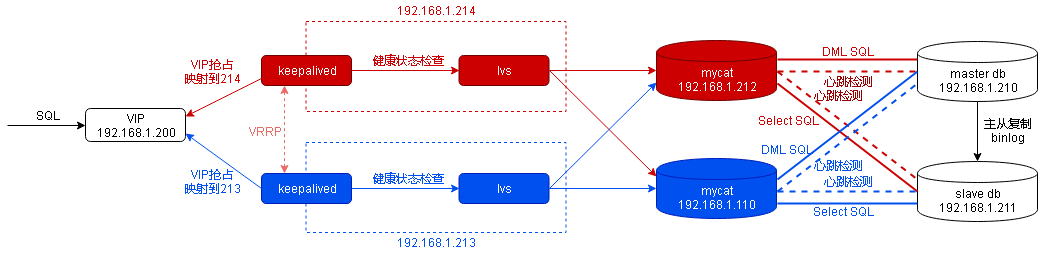
组件结构图一
SQL请求发给VIP,keepalived完成VIP的映射,并通过lvs将请求转发mycat,mycat根据SQL请求类型(DML SQL还是SELECT SQL,亦或是强制指定db节点)将SQL分发到具体的db,完成由具体的数据库服务完成SQL的执行。
但这还只是停留在数据库层面的部署,还没集成我们的应用,没有实际意义,那么我们如何集成我们的应用,实现mycat的使命呢?
应用集成
如果mycat搭建好了,进行应用集成非常简单,下面我们一步一步来实现各种情况下的应用集成
Mysql的读写分离与高可用
数据库的读写分离可以在代码层面实现(可参考:spring集成mybatis实现mysql读写分离),但不推荐,代码的核心职责应该是业务的实现,如果将大篇的代码用来实现数据库的读写分离与高可用,那就背离了本意、南辕北辙了。
计算机领域有句名言:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”。既然我们的代码直接对接数据库不好实现数据库的读写分离与高可用,那就在中间新增一层中间件来实现,从而产生了数据库中间件(mycat只是实现之一),应用代码直接与数据库中间对接,由数据库中间件来实现数据库的读写分离与高可用。此时的组件结构图如下
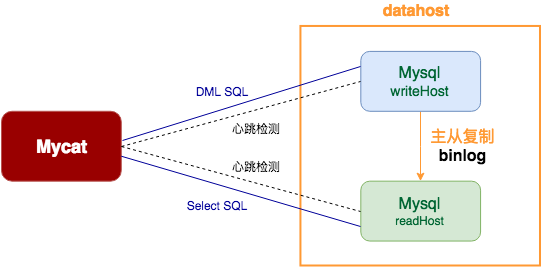
组件结构图二
具体的部署过程可参考:Mycat - 实现数据库的读写分离与高可用,此时应用如何集成了?其实非常简单,只需要将我们的连接池配置中的数据库地址改成mycat的地址即可(将mycat看成数据库),具体如下
application.yml


server: port: 8886 spring: #连接池配置 datasource: type: com.alibaba.druid.pool.DruidDataSource druid: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.1.212:8066/TESTDB?useSSL=false&useUnicode=true&characterEncoding=utf-8 username: root password: 123456 initial-size: 1 #连接池初始大小 max-active: 20 #连接池中最大的活跃连接数 min-idle: 1 #连接池中最小的活跃连接数 max-wait: 60000 #配置获取连接等待超时的时间 pool-prepared-statements: true #打开PSCache,并且指定每个连接上PSCache的大小 max-pool-prepared-statement-per-connection-size: 20 validation-query: SELECT 1 FROM DUAL validation-query-timeout: 30000 test-on-borrow: false #是否在获得连接后检测其可用性 test-on-return: false #是否在连接放回连接池后检测其可用性 test-while-idle: true #是否在连接空闲一段时间后检测其可用性 #mybatis配置 mybatis: type-aliases-package: com.lee.mycat.entity #config-location: classpath:mybatis/mybatis-config.xml mapper-locations: classpath:mybatis/*.xml # pagehelper配置 pagehelper: helperDialect: mysql #分页合理化,pageNum<=0则查询第一页的记录;pageNum大于总页数,则查询最后一页的记录 reasonable: true supportMethodsArguments: true params: count=countSql logging: level: com.lee.mycat.mapper: DEBUG
UserWeb.java
package com.lee.mycat.web; import com.lee.mycat.entity.User; import com.lee.mycat.service.IUserService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/mycat") public class UserWeb { @Autowired private IUserService userService; @RequestMapping("/getUserByNameFromMasterDb") public User getUserByNameFromMasterDb(String name) { return userService.getUserByNameFromMasterDb(name); } @RequestMapping("/getUserByNameFromSlaveDb") public User getUserByNameFromSlaveDb(String name) { return userService.getUserByNameFromSlaveDb(name); } @RequestMapping("/getUserByName") public User getUserByName(String name) { return userService.getUserByName(name); } @RequestMapping("/addUser") public Integer addUser(String name, Integer age) { return userService.insertUser(new User(name, age)); } }
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lee.mycat.mapper.UserMapper">
<sql id="Base_Column_List">
id,name,age
</sql>
<select id="getUserByNameFromMasterDb" resultType="User" parameterType="String">
/*!mycat:db_type=master*/ SELECT
<include refid="Base_Column_List" />
FROM
tbl_user
WHERE name=#{name}
</select>
<select id="getUserByNameFromSlaveDb" resultType="User" parameterType="String">
/*!mycat:db_type=slave*/ SELECT
<include refid="Base_Column_List" />
FROM
tbl_user
WHERE name=#{name}
</select>
<select id="getUserByName" resultType="User" parameterType="String">
SELECT
<include refid="Base_Column_List" />
FROM
tbl_user
WHERE name=#{name}
</select>
<insert id="insertUser" parameterType="User" useGeneratedKeys="true" keyProperty="id">
INSERT INTO
tbl_user(name, age)
VALUES
(#{name}, #{age})
</insert>
</mapper>
UserMapper.xml文件中会与我们平时的写法有些许不同,有时候需要明确指定强制走master还是slave节点。具体细节可查看:spring-boot-mycat
测试结果
如上图所示,我们一开始新增了一个用户:Jiraiye,其年龄是50,我们手动改了mysql slave中Jiraiye的年龄为52是为了更直观的验证SQL请求最终走的是mysql master还是mysql slave。从上图可知,一般的Select SQL走的是从库(DML SQL走主库这个就不用说了),如在mapper.xml中强制指定了db节点,那么就会在指定的mysql节点上来执行SQL。
mysql的高可用就没进行测试了,应用其实是感知不到的;mysql master宕机了,mycat会按我们配置好的进行mysql db的切换,正常服务于我们的应用。
Mycat的高可用
mysql的读写分离与高可用我们是实现了,可mycat却存在高可用问题,一旦mycat宕机了,整个数据库层就相当于宕机了。可想而知,我们需要实现mycat的高可用。
mycat的高可用搭建过程可参考:Mycat - 高可用与负载均衡实现,满满的干货!,此时的组件结构图如下
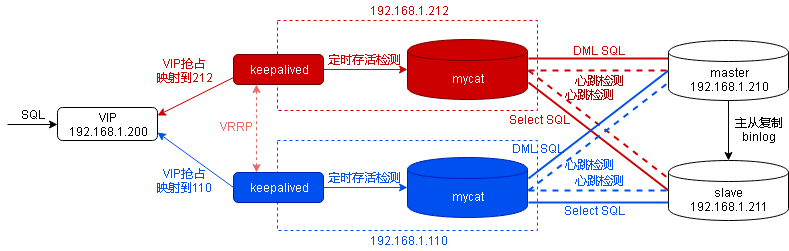
组件结构图三
应用工程改动非常小,只需要将数据库连接配置的url改成VIP即可,如下
jdbc:mysql://192.168.1.212:8066/TESTDB?useSSL=false&useUnicode=true&characterEncoding=utf-8 改成 jdbc:mysql://192.168.1.200:8066/TESTDB?useSSL=false&useUnicode=true&characterEncoding=utf-8
测试结果
mysql的读写分离依然正常工作,当mycat master宕机后,mycat slave接管任务,进行sql的转发,实现了mycat的高可用;期间出现了非常短时间的异常提示,这是因为数据库连接池中都是212上的mycat连接,212现在已经宕机了,所以会出现一次异常提示,但连接池立马做出了反应,重新建立数据库连接,此时连接池中的连接都是连接的110。
Mycat的负载均衡
上述mycat的高可用中,绝大多数情况下,mycat slave一直处于等待状态,未提供任何服务,因为我们的mycat master一般而言是不会宕机的。那有没有什么做法可以让slave也处理SQL请求,而又和master互备实现mycat高可用呢?那就是实现Mycat的负载均衡,此时mycat不存在主从关系,而是它俩两两互备,此时的组件结构图就是组件结构图一。应用工程不用变,数据库连接还是配置VIP。具体就不演示了,大家自行去实践即可。
总结
1、数据库中间件可以降低应用代码的复杂性,让其专职于业务代码的实现,而数据库层面的工作交给数据库中间件;mycat只是数据库中间件的一种实现,却也是比较优秀的实现,她是开源的。
2、并发量不高的情况下,实现mycat的高可用即可,无需实现Mycat的负载均衡;实现mycat的负载均衡需要更多的硬件成本和维护成本,却没有带来质变的收益,就性价比而言,不升反降。
3、具体需要部署成什么组件结构,需要看具体的需求,很多情况下根本用不到mycat中间件,如果用到了mycat中间件,个人认为最好还是实现mycat的高可用,至于需不需要实现mycat的负载均衡,就看具体的并发量了,这个也没个标准,就要结合实际情况来排查是不是mycat的负载过高了,如果确实是mycat负载过高,那么就有必要实现mycat的负载均衡来降低单个mycat的负载了。没有绝对的最优部署,只有当下最合适的部署。