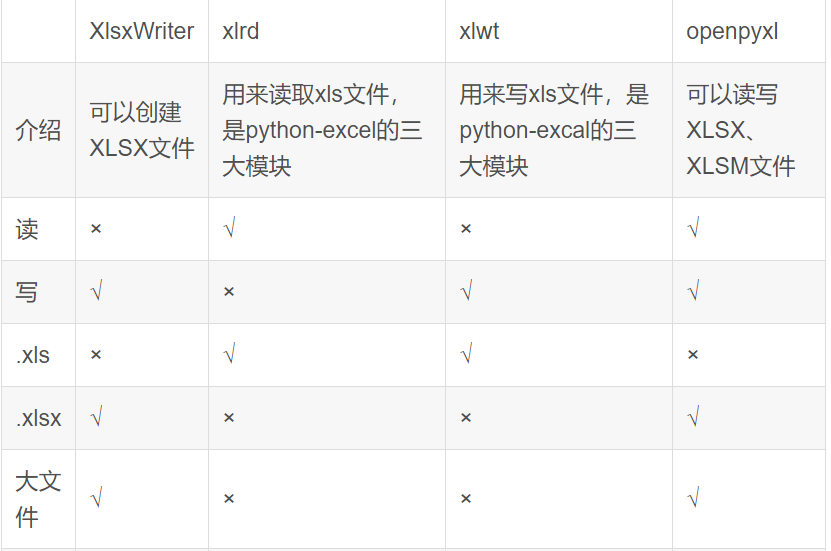
几种常用模块的使用方法
注释:Excel 2003 即XLS文件有大小限制即65536行256列,所以不支持大文件,而Excel 2007以上即XLSX文件的限制则为1048576行16384列
下面则为几种模块的使用:
1.xlwt 写入xls文件内容

import xlwt
book = xlwt.Workbook() # 新建工作簿
table = book.add_sheet('Over',cell_overwrite_ok=True) # 如果对同一单元格重复操作会发生overwrite Exception,cell_overwrite_ok为可覆盖
sheet = book.add_sheet('Test') # 添加工作页
sheet.write(1,1,'A') # 行,列,属性值 (1,1)为B2元素,从0开始计数
style = xlwt.XFStyle() # 新建样式
font = xlwt.Font() #新建字体
font.name = 'Times New Roman'
font.bold = True
style.font = font # 将style的字体设置为font
table.write(0,0,'Test',style)
book.save(filename_or_stream='excel_test.xls') # 一定要保存
2.xlrd读取xls文件内容
import xlrd
data = xlrd.open_workbook('excel_test.xls')
print(data.sheet_names()) # 输出所有页的名称
table = data.sheets()[0] # 获取第一页
table = data.sheet_by_index(0) # 通过索引获得第一页
table = data.sheet_by_name('Over') # 通过名称来获取指定页
nrows = table.nrows # 为行数,整形
ncolumns = table.ncols # 为列数,整形
print(type(nrows))
print(table.row_values(0))# 输出第一行值 为一个列表
# 遍历输出所有行值
for row in range(nrows):
print(table.row_values(row))
# 输出某一个单元格值
print(table.cell(0,0).value)
print(table.row(0)[0].value)
3.综合使用python-excel三大模块完成Excel内容追加写入
import xlwt,xlrd
from xlutils.copy import copy
data = xlrd.open_workbook('excel_test.xls',formatting_info=True)
excel = copy(wb=data) # 完成xlrd对象向xlwt对象转换
excel_table = excel.get_sheet(0) # 获得要操作的页
table = data.sheets()[0]
nrows = table.nrows # 获得行数
ncols = table.ncols # 获得列数
values = ["E","X","C","E","L"] # 需要写入的值
for value in values:
excel_table.write(nrows,1,value) # 因为单元格从0开始算,所以row不需要加一
nrows = nrows+1
excel.save('excel_test.xls')
4.使用openpyxl写xlsx文件
import openpyxl
data = openpyxl.Workbook() # 新建工作簿
data.create_sheet('Sheet1') # 添加页
#table = data.get_sheet_by_name('Sheet1') # 获得指定名称页
table = data.active # 获得当前活跃的工作页,默认为第一个工作页
table.cell(1,1,'Test') # 行,列,值 这里是从1开始计数的
data.save('excel_test.xlsx') # 一定要保存
5.使用openpyxl读取xlsx文件
import openpyxl
data = openpyxl.load_workbook('excel_test.xlsx') # 读取xlsx文件
table = data.get_sheet_by_name('Sheet') # 获得指定名称的页
nrows = table.rows # 获得行数 类型为迭代器
ncols = table.columns # 获得列数 类型为迭代器
print(type(nrows))
for row in nrows:
print(row) # 包含了页名,cell,值
line = [col.value for col in row] # 取值
print(line)
# 读取单元格
print(table.cell(1,1).value)
6.综合使用openpyxl对Excel内容追加写入
import openpyxl
data = openpyxl.load_workbook('excel_test.xlsx')
print(data.get_named_ranges()) # 输出工作页索引范围
print(data.get_sheet_names()) # 输出所有工作页的名称
# 取第一张表
sheetnames = data.get_sheet_names()
table = data.get_sheet_by_name(sheetnames[0])
table = data.active
print(table.title) # 输出表名
nrows = table.max_row # 获得行数
ncolumns = table.max_column # 获得行数
values = ['E','X','C','E','L']
for value in values:
table.cell(nrows+1,1).value = value
nrows = nrows + 1
data.save('excel_test.xlsx')
7.XlsxWriter
import xlsxwriter
# 1. 创建一个Excel文件
workbook = xlsxwriter.Workbook('demo1.xlsx')
# 2. 创建一个工作表sheet对象
worksheet = workbook.add_worksheet()
# 3. 设定第一列(A)宽度为20像素
worksheet.set_column('A:A',20)
# 4. 定义一个加粗的格式对象
bold = workbook.add_format({'bold':True})
# 5. 向单元格写入数据
# 5.1 向A1单元格写入'Hello'
worksheet.write('A1','Hello')
# 5.2 向A2单元格写入'World'并使用bold加粗格式
worksheet.write('A2','World',bold)
# 5.3 向B2单元格写入中文并使用加粗格式
worksheet.write('B2',u'中文字符',bold)
# 5.4 用行列表示法(行列索引都从0开始)向第2行、第0列(即A3单元格)和第3行、第0列(即A4单元格)写入数字
worksheet.write(2,0,10)
worksheet.write(3,0,20)
# 5.5 求A3、A4单元格的和并写入A5单元格,由此可见可以直接使用公式
worksheet.write(4,0,'=SUM(A3:A4)')
# 5.6 在B5单元格插入图片
worksheet.insert_image('B5','./demo.png')
# 5.7 关闭并保存文件
workbook.close()
pandas
数据写入csv文件


import json import requests import pandas as pd url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' data = { 'cname': '', 'pid': '', 'keyword': '上海',# 查询城市 'pageIndex':'1', # 显示第几页的数据 'pageSize': '100', # 一页显示多少数据 } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } # 请求网址 response = requests.post(url=url,data=data,headers=headers) # 反序列化 dic = json.loads(response.text) for i in dic["Table1"]: storeName = i["storeName"] addressDetail = i["addressDetail"] pro= i["pro"] provinceName = i["provinceName"] cityName = i["cityName"] # 构建数据结构 data={ 'storeName':[storeName], 'addressDetail':[addressDetail], 'pro':[pro], 'provinceName':[provinceName], 'cityName':[cityName], } # 实例化DataFrame对象 df1 = pd.DataFrame(data=data) # 写入本地 不要标题|不要索引|追加的方式写入 df1.to_csv('./lagou.csv',header=False,index=False,mode='a+',encoding='gbk') print("写入成功")
读取csv文件
import pandas as pd
df_example = pd.read_csv('./lagou.csv',encoding="gbk")
print(df_example)
写入数据
import json import xlwt import requests url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' data = { 'cname': '', 'pid': '', 'keyword': '上海',# 查询城市 'pageIndex':'1', # 显示第几页的数据 'pageSize': '100', # 一页显示多少数据 } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } # 请求网址 response = requests.post(url=url,data=data,headers=headers) # 反序列化 dic = json.loads(response.text) title = ["storeName","addressDetail","pro","provinceName","cityName"] li = [] # 获取数据 for i in dic["Table1"]: storeName = i["storeName"] addressDetail = i["addressDetail"] pro= i["pro"] provinceName = i["provinceName"] cityName = i["cityName"] li.append([storeName,addressDetail,pro,provinceName,cityName]) #新建一个excel对象 wbk = xlwt.Workbook() #添加一个名为stu的sheet页 sheet = wbk.add_sheet('stu') # 写入表头 for i in range(len(title)): # 从0行i列写入标题 sheet.write(0,i,title[i]) # 写入数据 for i in range(len(li)): # 如果不是表头的话 if i!=0: # 循环写入数据 for j in range(len(title)): sheet.write(i,j,li[i][j]) wbk.save('szz.xls') print("下载成功") 爬虫演示
