在UML和模式应用一书中,发送给Die的roll消息之后跟随着第二个消息getFaceValue用于提取其新的faceValue,特别是:roll()方法是void的,没有返回值,例如:
public void roll()
{
faceValue=//生成随机数
}
public int getFaceValue()
{
return faceValue;
}
为什么不将两个方法合并起来,使roll()方法返回新的faceValue呢?如下所示:
//为什么这种方法不好
public int rolll()
{
faceValue=//生成随机数
return faceValue;
}
第二种方式违反了命令-查询分离原则command-query separation principle。CQS是针对方法的经典oo设计原则,该原则指出,任何方法都可能是如下情况之一;
1.执行动作(更新,调整。。。。)的命令方法,这种方法通常具有改变对象状态等副作用。并且是void的,没有返回值。
2向调用者返回数据的查询,这种方法没有副作用,不会永久性地改变任何对象的状态。
关键是,一个方法不应该同时属于以上2个类型。
roll()方法是命令,它具有改变Die对象的faceValue属性状态的副作用,因此,他不应该同时返回新的faceValue,否则该方法也会成为查询,从而违法了“必须为void”的规则。
CQS被公认为是计算机科学中具有价值的原则,因为遵循该原则,你能够更容易地推测出程序的状态,在查询状态时不会同时发生变更。这样使得设计更便于理解和预见,例如,如果应用一直遵循CQS,那么你会知道查询或getter方法不会有任何修改,而命令也不会有任何返回,这是个简单的模式,这通常要严格遵循的,因为如果突然改用其他方法,将会产生令人不悦的意外,从而违反软件开发中的最小意外(least surprise)的原则。
考虑如下的反面示例,其中的查询方法违反了CQS:
Missile m=new Missile();
String name=m.getName();
public classs Missile
{
///......
public string getName()
{
launch();//发射导弹
return name;
}
}
一篇文章:
CQRS(命令查询职责分离)
CQRS(Command Query Responsibility Segregation)指的是命令查询职责分离。这是一种我从Greg Young处听到的模式描述。它的核心思想很简单,就是你在更新和读取操作时使用不同的模型,这样的话,会给整个系统的设计带来深远的变革。
人们和信息系统交互的主流行为就是对数据仓库CRUD的使用,我们构思一个可以供创建、读取、更新和删除的数据模型。简单来说,我们的接口提供出来的目的就是供存储和获取数据之用的。
现在我们要脱离这样一种模型,看看另一种存储数据的方式,可能是把很多数据打包成一个数据对象,或者把一些数据按照某种格式压缩成一种新的格式存储起来。在数据更新这块,我们可以找到一些校验方式来对上述要存储的数据进行校验,甚至可以推断出我们提供的数据和现有的存储数据有什么不同。
传统方式:
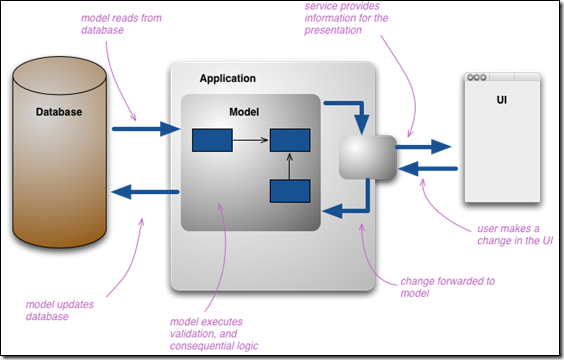
这样一来,我们可以开始用多种视角来看待数据的呈现了。当用户和数据交互的时候,他们使用的是不同种的数据呈现方式。开发者通常会构建他们自己觉得正确的核心属性的概念模型,如果你在使用领域模型,那么这就是一种概念上的领域模型的表达,你当然也可以对数据的存储定义这样的一个概念模型。
今天提到的方式:
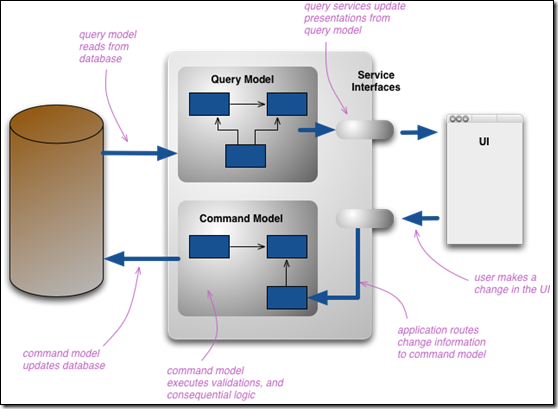
CQRS则做了改变,它将这个模型拆分成命令和展示两部分,分别叫做Command和Query。这样对于很多问题,特别是复杂的领域,相对于对命令和查询使用同一概念模型,复杂性降低。
把模型拆开来,这意味着可以用不同的逻辑进程、不同的硬件来做这两部分事情了。一个WEB上的例子,用户查看页面的时候使用查询模型;而如果要改变数据,这种改变会解析成若干命令模型来执行操作,操作完毕后通知状态的更新。
这里有一些变数需要考虑,内存中的两种模型可以来自同一个数据库,但也可以来自不同的数据库。比如可以让数据的查询来自实时的ReportingDatabase(一种只提供读取服务的数据库概念,Bliki上尽是概念,有的东西还真不怎么样,呵呵,译注),这样的话就需要一种存在于不同数据库之间的数据通信机制。
两种模型,那么原本相同的对象就需要不同的方法来操纵和查询了,就像关系数据库中的不同视图。不过我一听说了CQRS的介绍,这两种模型在脑海里一下子清晰起来。
我们把一个通过CRUD来交互的模型,挪到基于事件的UI层,对于基于事件溯源的场景我们使用命令模型。如何保持两种模型的一致性呢?这里需要考虑事件层面的一致性。很多情况下只有你在更新数据前才需要执行业务逻辑,所以使用EagerReadDerivation(这个我不知道怎么翻译,建议大家打开链接看一看,读请求可以直接从ReportingDatabase中获取数据,而不经过逻辑处理,这个思路是有些奇特,见下面的图,译注)来简化你的查询模型是有很大意义的。
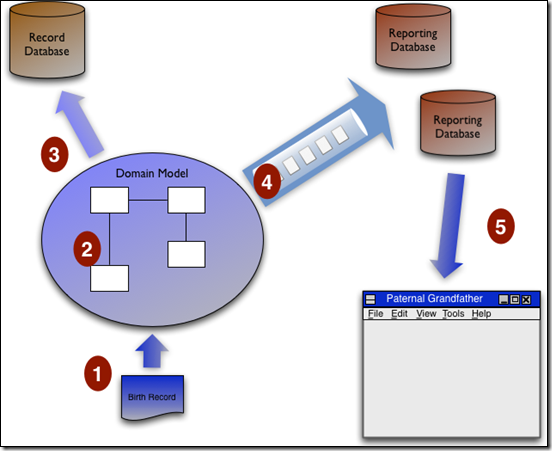
像很多模式一样,CQRS只在某些场合适用,它带来了一种思维上的跳跃,如果不能从中获益,就不要考虑它。尤其值得一提的是,CQRS只在某些特殊系统的某部分中使用(如面向领域设计中提到的Bounded Context)。
目前为止我只看到只有两个方面在此获益。一个是针对非常复杂的场景,可以用CQRS简化问题。通常我尽量不这么做,因为在命令和查询两部分重叠较多,有足够多的方法属性可以重用;另一个情况是对于高性能的应用,如果读写比例太悬殊,
CQRS可以让你分开考虑横向扩展,即便是传统方式,你也得对读写考虑不同的优化策略。一个例子是使用不同的数据库访问技术来处理查询和更新。
如果你的场景不适合使用CQRS,但是你又面对查询的复杂性和性能问题,你仍然可以试试这个ReportingDatabase,因为这样你仍然可以使用你原来的系统,只是对于一些特殊要求的查询,切换到这个ReportingDatabase上去(我通读了一下关于这个东西的文章,也没有见到它有特别优秀的地方,再者,对于这样一些变态场景,更可能会考虑的是一些成熟的读写库分离技术,译注)。
我们目前还没有看到很多使用CQRS的地方,我们理解大家对它赞成和反对的理由,CQRS依然是我工具箱中必不可少的一把利器,虽然我不经常使用它。
转自:http://www.raychase.net/259