版权声明:本文为原创文章,未经允许不得转载。
SparkContext(简称sc)是Spark程序的主入口,代表一个连接到Spark集群(Standalone、YARN、Mesos三种集群部署模式)的连接,能被用来在集群上创建RDDs、计数器(accumulators)和广播(broadcast)变量等。一旦和集群连接,sc首先得到集群中节点的executor信息,然后把app代码(jar形式或python文件)发送给executors,最后把job细分后的tasks派发给具体的executor执行。
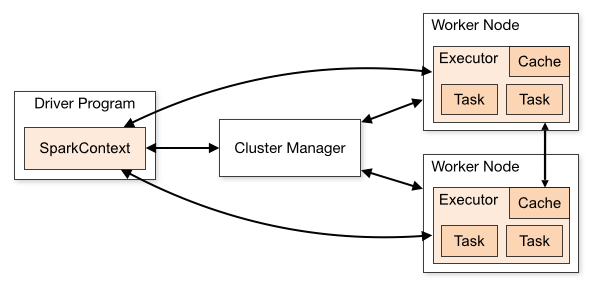
Spark集群架构图
1.属性
(1)Spark异步事件监听器总线,可以理解为监听器的管家
private[spark] val listenerBus = new LiveListenerBus
(2)两个map集合,用于存储为每个静态文件和jar存放对应的URL和本地时间戳
private[spark] val addedFiles = HashMap[String, Long]
private[spark] val addedJars = HashMap[String, Long]
(3)用一个弱引用类型的Map,记录所有的持久化的RDDs,若值被gc后,那么引用将为null,每当插入N个元素后,就会从Map移除引用为空的entry
private[spark] val persistentRdds = new TimeStampedWeakValueHashMap[Int, RDD[_]]
(4)根据sparkconf、isLocal、监听总线创建Spark运行环境
private var _env: SparkEnv = createSparkEnv(_conf, isLocal, listenerBus)
(5)构造SparkContext的元数据清理器,使用了Timer周期性地清理日志信息,元数据类型不同,清理周期也可能不同
private var _metadataCleaner: MetadataCleaner = new MetadataCleaner(MetadataCleanerType.SPARK_CONTEXT, this.cleanup, _conf)
(6)默认executor的执行内存为1024M
private var _executorMemory: Int = _conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM"))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
(7)一个Spark application唯一的主键,它的形式取决于调度的实现,例如本地模式为'local-1433865536131'、YARN模式为 'application_1433865536131_34483'
private var _applicationId: String = _
(8)DAG调度器,把job根据shuffle边界划分为TaskSets
@volatile private var _dagScheduler: DAGScheduler = _
(9)Task调度器,目前只有一个实现子类TaskSchedulerImpl,负责接受从DAG调度器生成的TaskSets然后把他们分配到executor中执行,而TaskSetManager负责TaskSet的调度
private var _taskScheduler: TaskScheduler = _
(10)一个后端的调度接口,用于不同集群模式的调度
private var _schedulerBackend: SchedulerBackend = _
(11)设置一个心跳接收器,driver接受executor的心跳
private var _heartbeatReceiver: RpcEndpointRef = _
(12)JobProgressListener 用于处理Job及Stage相关的事件监听器
private var _jobProgressListener: JobProgressListener = _
2.方法
构造方法有8个,比较简单就不介绍了。
2.1.创建RDD的方法如下所示:

创建RDD的方法总览
方法对应生成的RDD类型有:BinaryFileRDD、BlockRDD、CartesianRDD、CheckpointRDD、CoalescedRDD、CoGroupedRDD、EmptyRDD、HadoopRDD、LocalCheckpointRDD、MapPartitionsRDD、MapPartitionsWithPrepationRDD、NewHadoopRDD、ParallelCollectionRDD、ParititionerAwareUnionRDD、PartitionPruningRDD、PartitionwiseSampledRDD、PipeRDD、SampleRDD、ShuffleRDD、SubstractedRDD、UnionRDD、ZippedPartitionsRDD、ZippedWithIndexRDD,如此多的的RDD,可见RDD的重要性。
2.2.创建计数器(accumulators)的方法如下所示:

创建计数器的方法总览
2.3.创建广播(broadcast)变量的方法就一个:
def broadcast[T: ClassTag](value: T): Broadcast[T] = {
2.4.Spark程序程序job的运行是通过actions算子触发的,action算子如下所示:
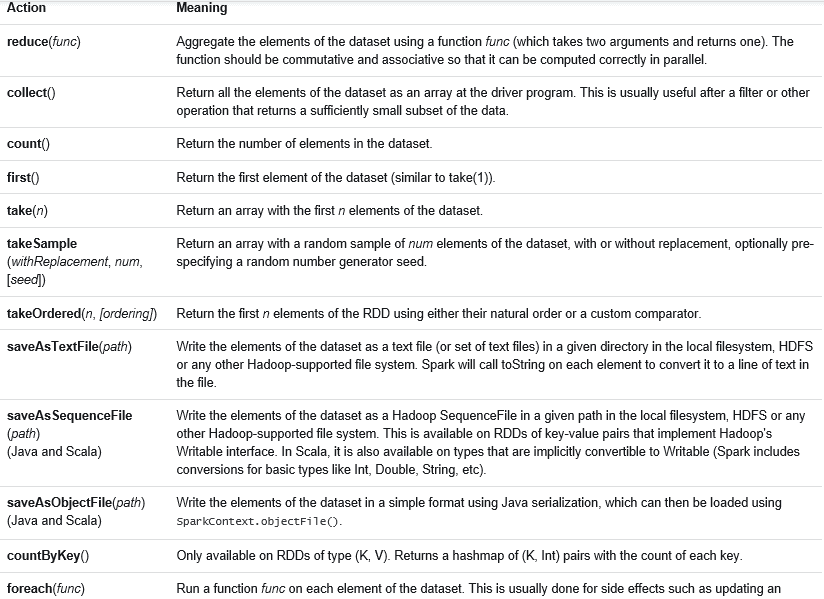
action算子总览
每一个action算子其实是一个runJob方法的运行,job的运行是将JobSubmitted事件添加到DAGScheduler中的事件执行队列中,并用JobWaiter等待结果的返回。runJob方法如下所示:

runjob方法总览
5.SparkContext如何在三种部署模式Standalone、YARN、Mesos下实现任务的调度
SparkContext中有一句关键性的代码:
//根据master(masterURL)及SparkContext对象创建TaskScheduler,返回SchedulerBackend及TaskScheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
考虑到篇幅的长度,方法createTaskScheduler的实现下一篇再介绍。