1. sklearn简介
sklearn是机器学习中一个常用的python第三方模块,网址:http://scikit-learn.org/stable/index.html ,里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
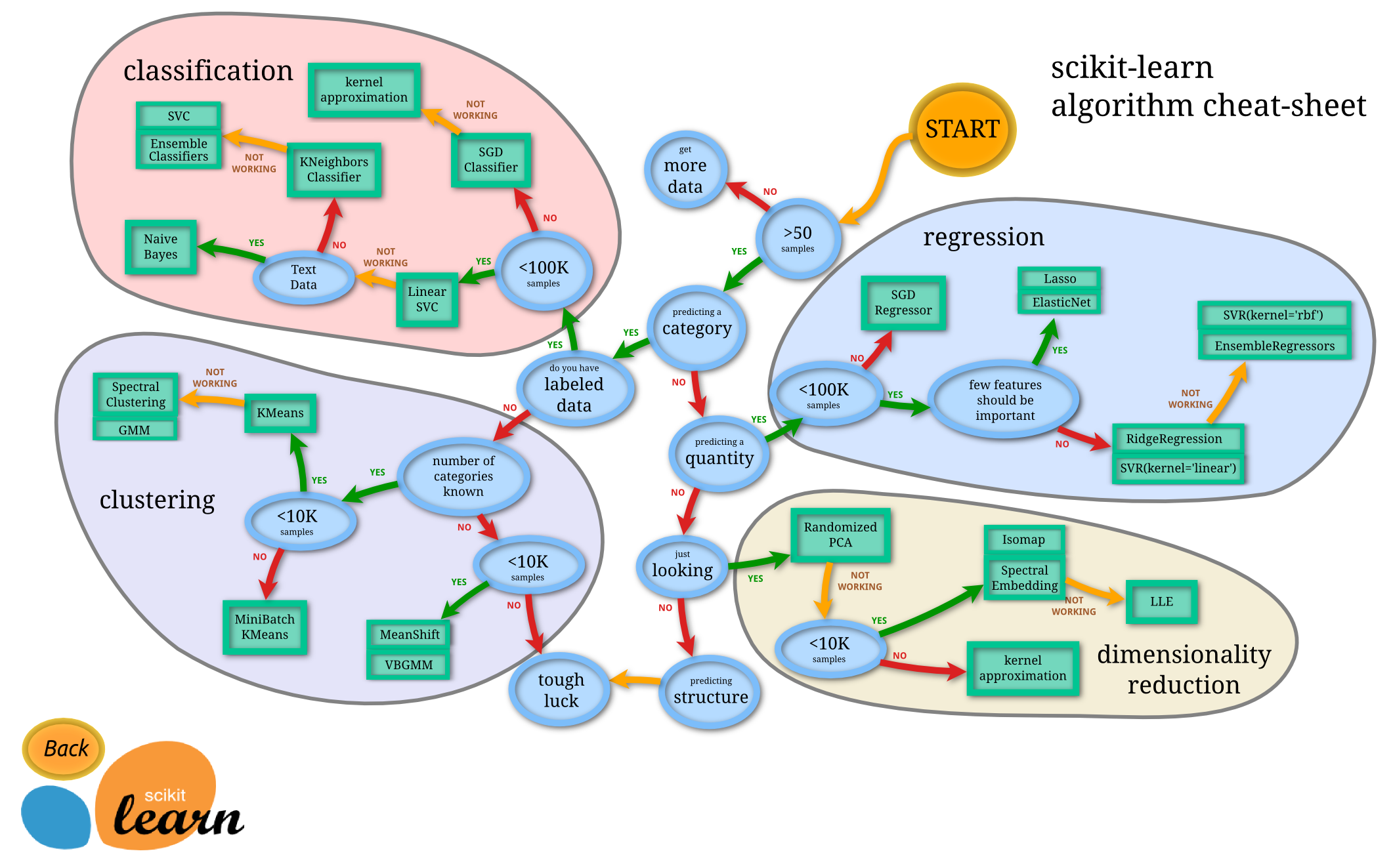
库的算法主要有四类:分类,回归,聚类,降维。其中:
常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维:LinearDiscriminantAnalysis、PCA
2. 名词说明

P=TP+FNP=TP+FN, N=TN+FPN=TN+FP
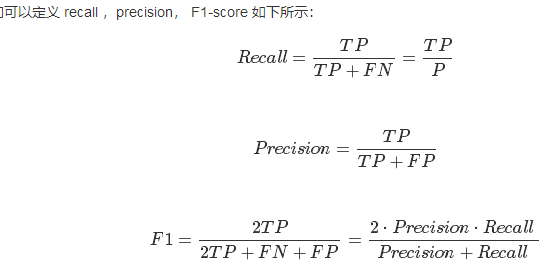
可以看到,recall 体现了分类模型HH对正样本的识别能力,recall 越高,说明模型对正样本的识别能力越强,precision 体现了模型对负样本的区分能力,precision越高,说明模型对负样本的区分能力越强。F1-score 是两者的综合。F1-score 越高,说明分类模型越稳健。

可以看到,当 β=1β=1,那么FβFβ就退回到F1F1了,ββ 其实反映了模型分类能力的偏好,β>1β>1 的时候,precision的权重更大,为了提高FβFβ,我们希望precision 越小,而recall 应该越大,说明模型更偏好于提升recall,意味着模型更看重对正样本的识别能力; 而 β<1β<1 的时候,recall 的权重更大,因此,我们希望recall越小,而precision越大,模型更偏好于提升precision,意味着模型更看重对负样本的区分能力。
3.例子1:实现线性分类器
样本:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
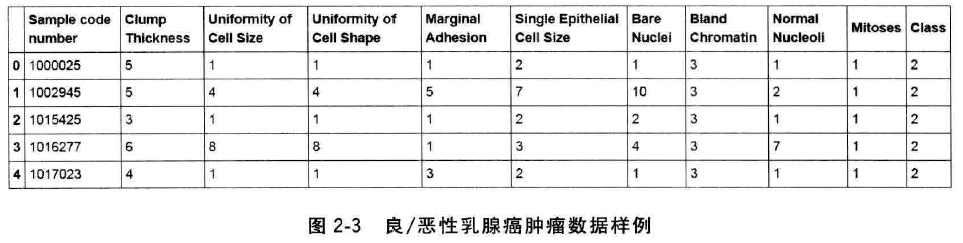
csv文件形式:

#coding=utf-8
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import stochastic_gradient
from sklearn.metrics import classification_report
#1.数据获取
#创建特征列表
#'样品代码编号','团块厚度','细胞大小均匀性', '细胞形状的均匀性','边缘粘附','单个上皮细胞大小',...'种类'
column_names=['Sample code number','Clump Thickness','Uniformity of Cell Size',
'Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size',
'Bare nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
# 使用pandas.read_csv函数从互联网读取制定数据
data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',names=column_names)
#打印信息
print data.info() #查看详细信息
print data.head() #查看部分信息
print data.shape #(699, 11)
#2.数据预处理:缺失值,标准化
#替换和去除缺失值
data=data.replace(to_replace='?',value=np.nan) # 将?代换为标准缺失值表示 nan
data=data.dropna(how='any') # 丢弃带有缺失值的数据(只要有一个纬度有缺失)
print data.shape #(683, 11)
## 随机采用25%的数据用于测试,剩下的75%的数据用于训练集 random_state是随机数的种子,不同的种子会造成不同的随机采样结果,相同的种子采样结果相同
X_train,X_test,y_train,y_test=train_test_split(data[column_names[1:10]],data[column_names[10]],test_size=0.25,random_state=33) #编号没有进入训练
#标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导。
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test=ss.transform(X_test)
#3.使用逻辑斯蒂回归
lr = LogisticRegression() # 初始化LogisticRegression
lr.fit(X_train,y_train) # 使用训练集对测试集进行训练
lr_y_predit=lr.predict(X_test) # 使用逻辑回归函数对测试集进行预测
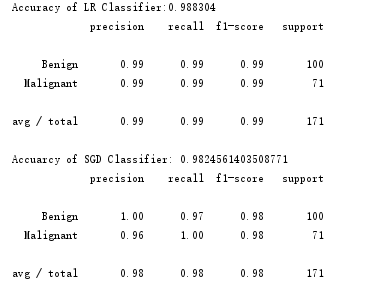
print ('Accuracy of LR Classifier:%f'%lr.score(X_test,y_test)) # 使得逻辑回归模型自带的评分函数score获得模型在测试集上的准确性结果
print classification_report(y_test,lr_y_predit,target_names=['Benign','Malignant']) #良性,恶性
#4.使用逻辑斯蒂回归(基于随机梯度下降法SGD)
sgdc=stochastic_gradient.SGDClassifier(max_iter=5) # 初始化分类器
sgdc.fit(X_train,y_train)
sgdc_y_predit=sgdc.predict(X_test)
print 'Accuarcy of SGD Classifier:', sgdc.score(X_test, y_test)
print classification_report(y_test,sgdc_y_predit,target_names=['Benign','Malignant'])
运行结果(第3,4部分):
4.例子2:实现SVM对手写数字的识别
#coding=utf-8
from sklearn.datasets import load_digits # 从skleran.datasets里有导入手写体数字加载器
from sklearn.model_selection import train_test_split #导入train_test_split用于数据分割
from sklearn.preprocessing import StandardScaler # 导入标准化数据
from sklearn.svm import LinearSVC # 从sklearn.svm中导入基于现行假设的支持向量机分类器LinearSVC
from sklearn.metrics import classification_report
#1.数据获取
digits = load_digits() #从通过数据加载器获得手写数字的数码图像数据并存储在digits中
print digits.data.shape # 检视数据规模和数据纬度
#2.数据预处理:训练集测试集分割,数据标准化
X_train,X_test,y_train,y_test = train_test_split(digits.data,digits.target,test_size=0.25,random_state=33)
print X_train
print y_train
print y_train.shape
ss = StandardScaler() # 对测试集和训练集进行标准化
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
#3.使用SVM训练
lsvc = LinearSVC() # 初始化现行假设的支持向量机分类器 LinearSVC
lsvc.fit(X_train,y_train) # 进行模型训练
y_predict = lsvc.predict(X_test)
#4.生成结果报告
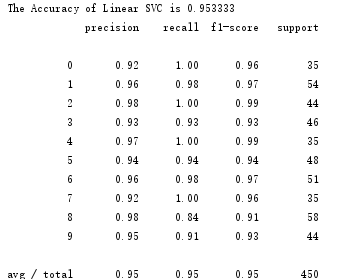
print ('The Accuracy of Linear SVC is %f'%lsvc.score(X_test,y_test)) # 使用自带的模型评估函数进行准确性评测
print classification_report(y_test,y_predict,target_names=digits.target_names.astype(str)) # 使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析
运行结果: