创建语法:
create [unique] [clustered|nonclustered] index ix_索引名字 on 表名
(
列1 desc|asc
,列2 desc|asc)
,...
)
unique : 表示是否创建唯一索引,不是必须
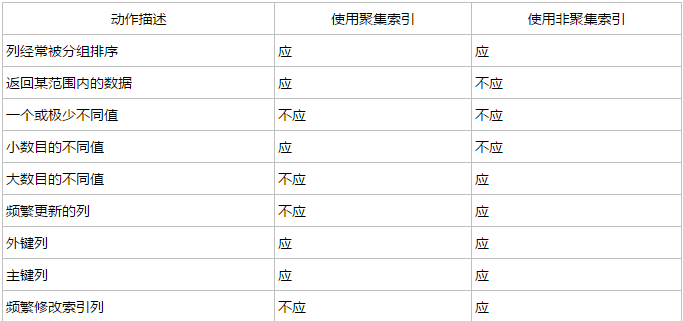
聚集索引:表记录的排列顺序和与数据的存储顺序一致(主键),一个表只能有一个,但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
-->聚集索引规定了数据文件的存储顺序
非聚集索引:表记录的排列顺序和与数据的存储顺序不一致(唯一),一个表可以有多个
-->是一个单独存放的指针表,用来快速找到对应点的地址
更形象的说字典的拼音目录就是聚集索引,笔画目录就是非聚集索引。
相同点:都是按照索引查找.
列举三种导致索引不生效的SQL语句写法
(1)对索引列使用了函数或计算
假如表table1的索引列是id,但如下语句会使索引无效
select * from table1 where dbo.fn_fun(id)='xxx'
(2)对索引列使用了Like ‘%X’或Like ‘%X%’
引用上面的表,如下语句也会使索引无效
select * from table1 where id like '%xx%'
(3)在where子句中使用了In(子查询)
如下语句会使索引无效
select * from table1 where id in (select id from table2)
(4)数据类型转换将导致不能利用索引
如下语句会使索引无效
select * from table1 where cast(id as varchar(50))='xxx'
(5)负向比较将导致不能利用索引
如下语句会使索引无效
select * from table1 where 'xxx'=id
索引有什么不足?
缺点:过多的索引,在insert、update 和 delete 的时候增加索引的维护成本,降低并发量;
转载自 https://www.cnblogs.com/xiaoweigogo/p/7778781.html