Zookeeper也可以实现分布式锁,下面记录下相关原理,主要参考文末书籍和博文。
原理
在分布式系统中,当多个系统或同一个系统的不同主机想使用某个共享资源时,需要使用互斥的手段,保证使用资源的合理性,防止相互之间读写的干扰。
举个栗子,当多个男生同时追求某位女生,其实同时只能有一个能和这位女士聊天,其他的男生以为他们女神睡觉或者在忙,其实正和某位男生正聊得飞起,这位幸运的男士获得了女士的心锁,当他感觉新鲜感褪去释放心锁后,其他男士才有重新获取心锁的机会,这就是分布式锁的一个案例,如果么有这个锁,后果将不堪设想。
在单个JVM中的并发情况,可以使用JDK提供的Synchronized或ReentrantLock来定义锁,实现资源互斥,在分布式系统中多个JVM中的并发,不能使用这两种方式,需要使用分布式锁。
实现分布式锁,目前博客里推荐的有关系型数据库、Memcached(add命令)、Redis(setnx命令+后期完善)、Zookeeper(临时顺序节点),Chubby。这里主要记录Zookeeper是如何实现分布式锁,主要有排他锁和共享锁两种。
排他锁(Exclusive Locks)
排他锁又称为独占锁,如果某个事务占用了这个锁,获取到数据对象O的读写权限,其他事务就不能对这个数据对象O做任何操作,直到这个事务释放了锁。其他事务监听到锁释放后,会重新竞争获取锁,新得到锁的事务才有对象O的操作权限。
排他锁在Zookeeper中的实现主要通过临时节点实现,参考文末书籍,获取和释放锁的流程如下。
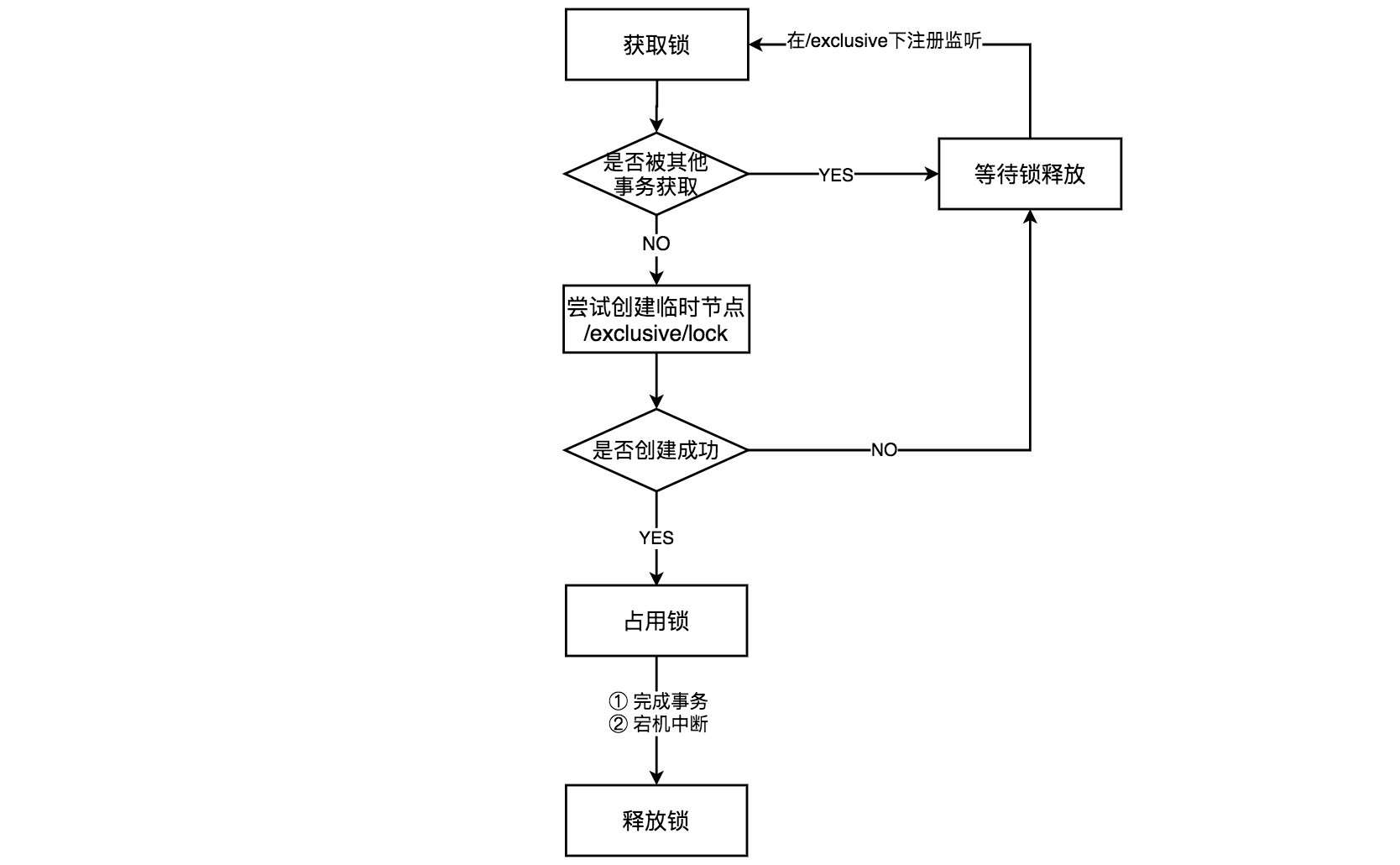
在获取锁的过程中,只有成功创建了/exclusive下lock临时节点的客户端才算获取锁成功,没有成功的就在/exclusive下注册Watcher监听,一旦监听到临时节点删除就会加入获取锁的竞争中。
释放锁有两种可能,一种是正常执行完了业务逻辑,客户端自动删除这个临时节点,一种是获取到锁的客户端宕机,与Zookeeper服务器的session失效也会自动删除临时节点,释放锁。
共享锁(Shared Locks)
共享锁又称为读锁,相比排他锁,它在读请求上,是共享锁的,多个节点创建了临时顺序节点后,会获取节点列表并且排序,如果是多个读请求连在一起,他们都可以获取共享锁,对数据对象进行读操作。而在写请求上,类似排他锁,必须保证它是最小序号的才可以获取锁,否则就进行等待,哪怕它前面序号的请求是读请求,也必须等待。
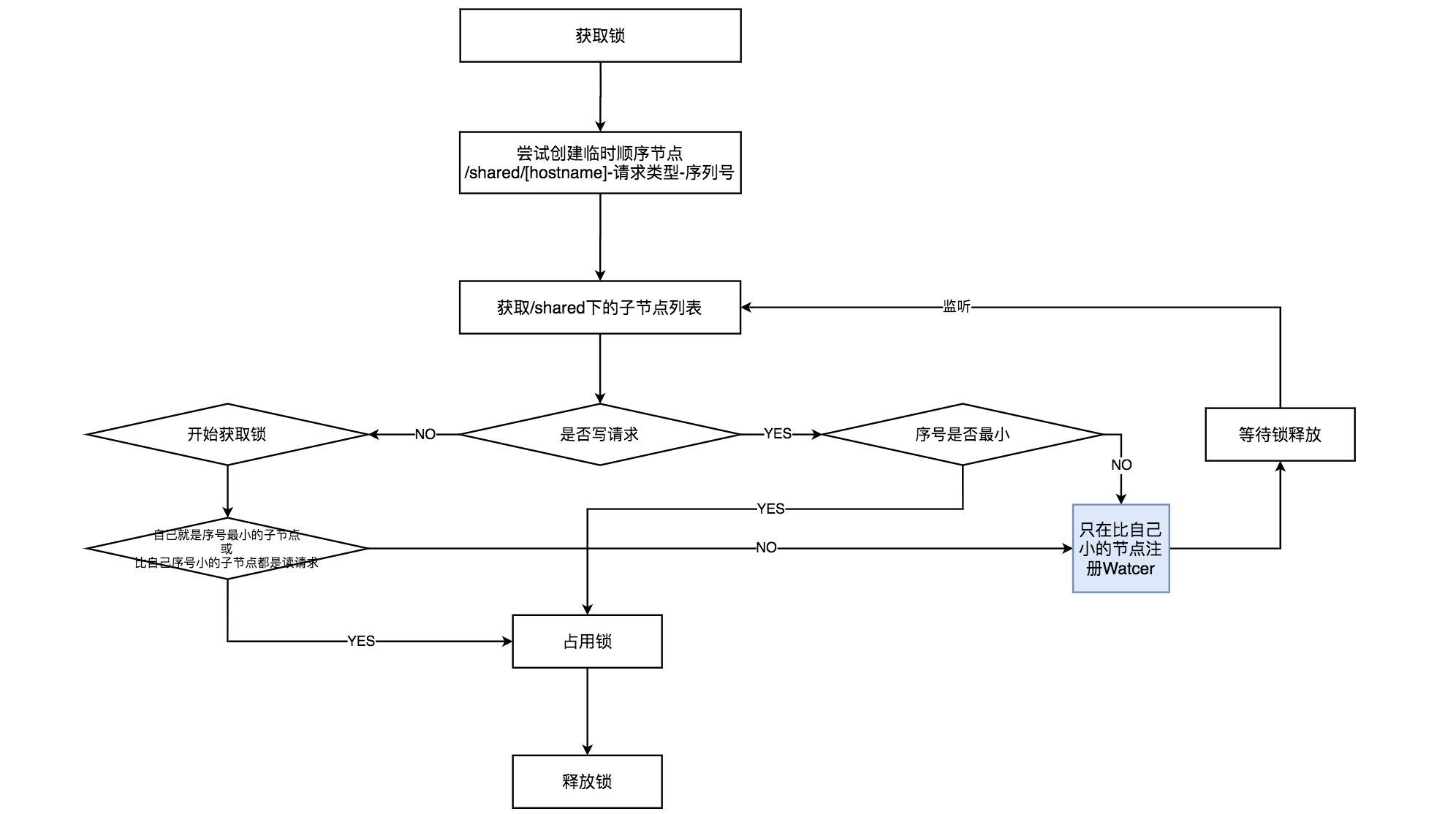
共享锁在Zookeeper中的实现主要通过临时顺序节点实现,参考文末书籍,获取和释放锁的流程如下。
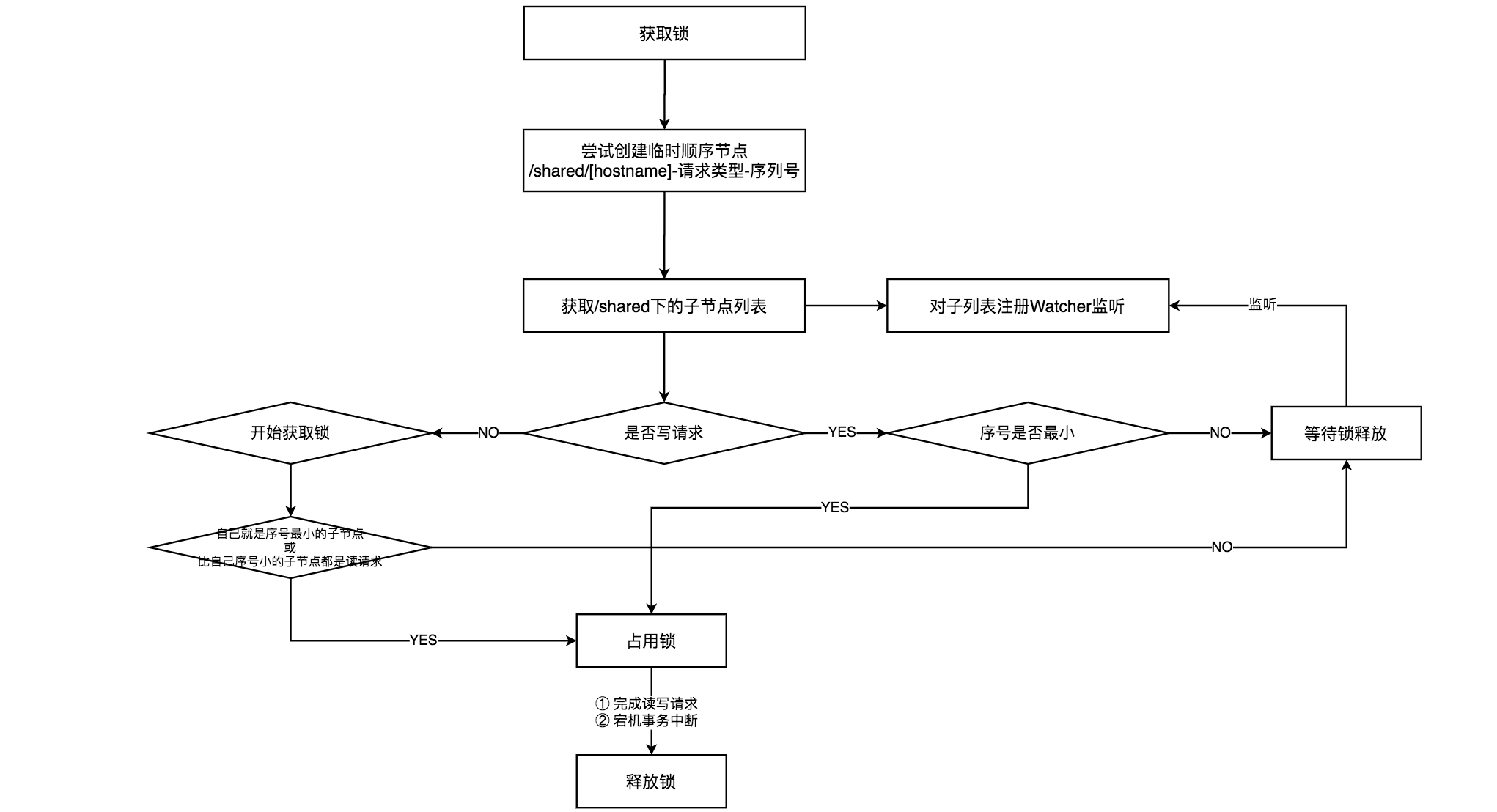
在获取锁的过程中,客户端在创建完/shared下"[hostname]-请求类型(R读或W写)-序列号"的临时顺序节点后,需要获取/shared下子节点列表,并且为每个子节点在/shared节点下注册Watcher监听。根据自己在字节点列表中的顺序,进行如上图所示的判断后,才能决定自己是否能获取到共享锁。
- 如果当前客户端创建的写请求是序号最小的,则获取到共享锁,否则需要等待锁。
- 如果当前客户端创建的读请求是序号最小的,或者读请求不是最小但是比它小的序号都是读请求,也将获取到共享锁,否则需要等待锁。
以下是客户端在示例节点/shared下创建临时顺序节点后,判断是否获取共享锁的示意图,注意区分读请求和写请求,看样子读请求更像是共享一把锁,而写请求还是独占。
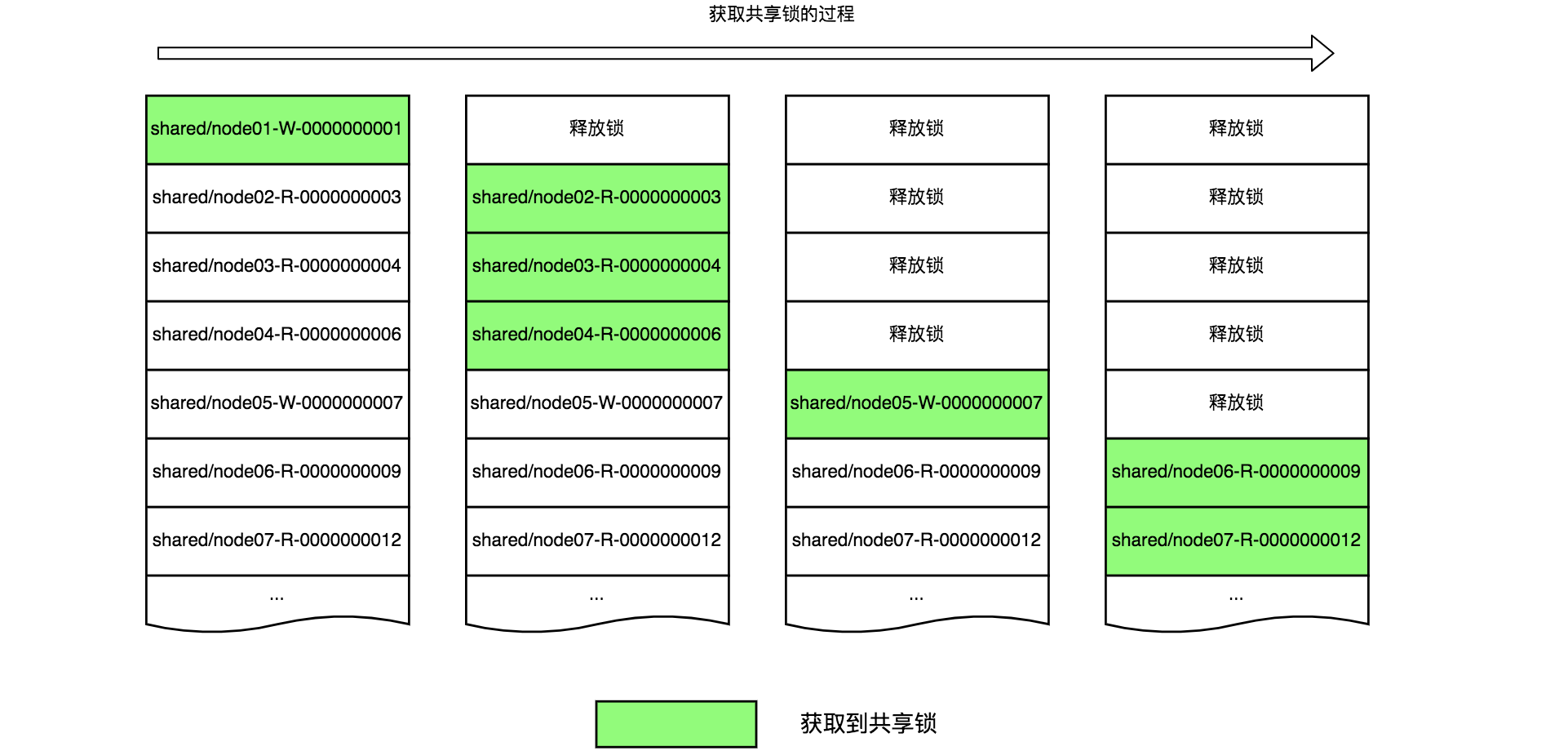
共享锁释放锁的过程,和排他锁是一样的,参考上文排他锁。
羊群效应
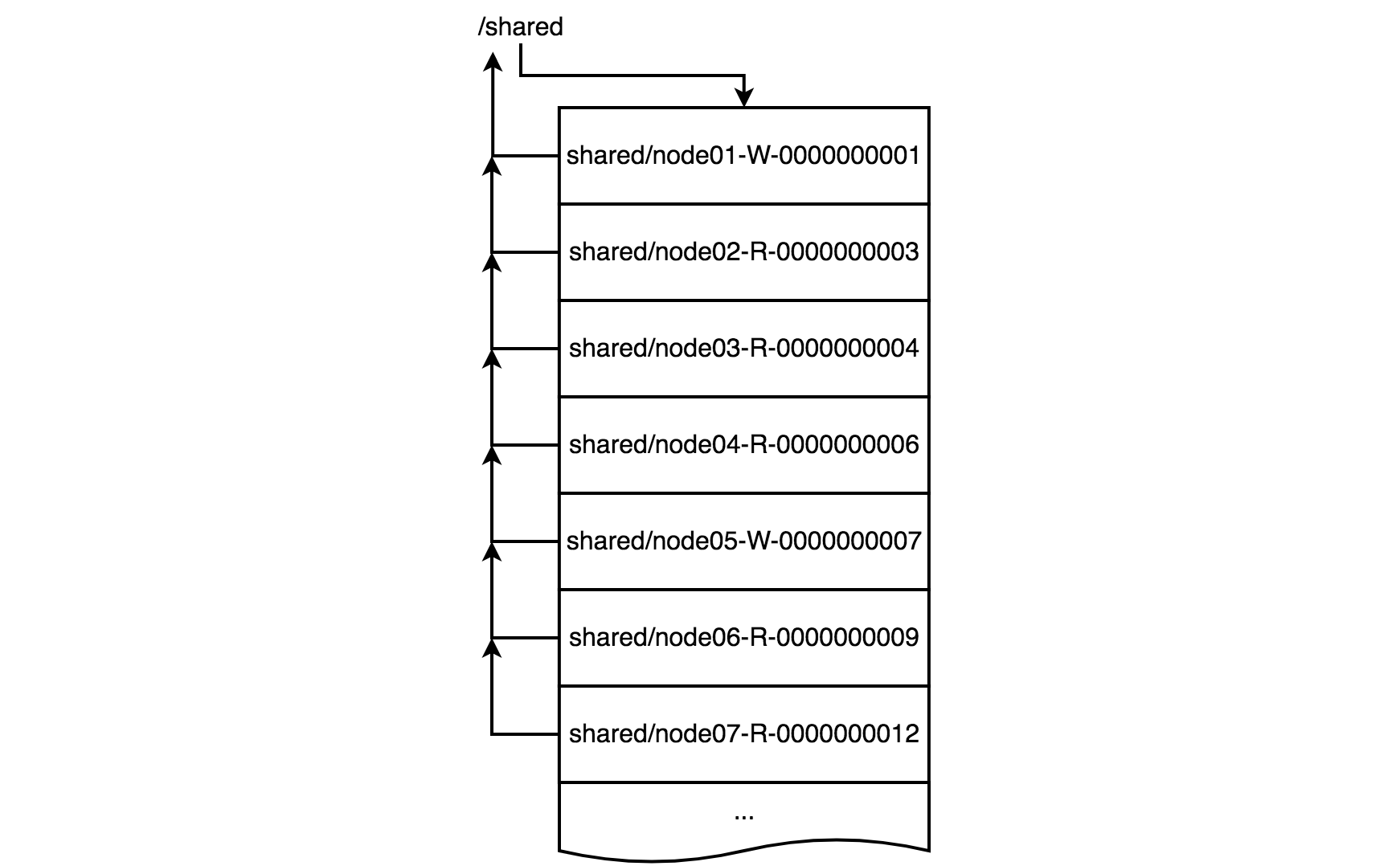
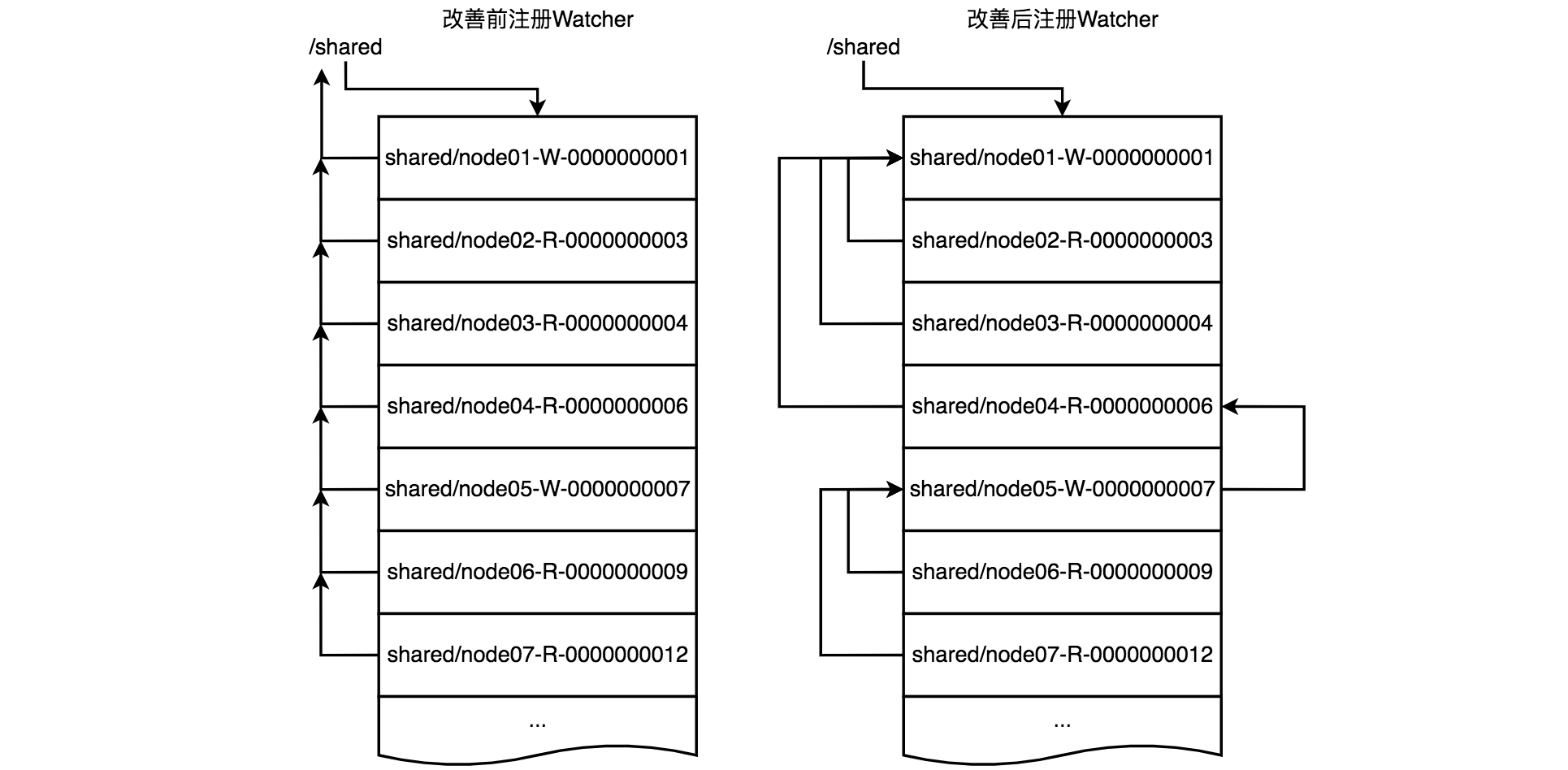
上面在/shared节点下注册完子节点后,需要获取子节点列表,并且/shared节点被其他子节点注册的Watcher监听着,如下图所示,子节点都在监听/shared的变化,这样会产生如下问题,以node01为例。
- 当node01完成写操作后,会删除临时顺序节点node01-W-0000000001,并且被其他节点监听到。
- 剩余的节点,会继续从/shared下获取一份子节点列表,并判断是否自己可以获取到共享锁,只有获取到共享锁的,才可以执行业务逻辑,剩余的依然要等待下一次判断,如此反复。当node01释放锁后,node02、node03和node04将获取到共享锁并进行读请求,而node05、node06和node07只能继续等待。
可以看到每次/shared节点变化,都会广播到下面的每个子节点,并且剩余子节点会获取/shared子节点列表来判断自己是否有机会获取到锁。这样的结果会导致很多重复的无用的广播,以及重复的获取子列表的情况,因为每次判断,只有少数的节点能获取到锁,对其他的节点好像一个废操作,并没有实际作用。
上面重复发送Watcher监听结果以及获取子列表的情况,在Zookeeper集群规模不大的情况下(书中给出数字10台)是可以接受的,在更多的机器下,这样显然会占用网络资源影响性能,这就是“羊群效应”,为了避免“羊群效应”,需要对原来的获取锁和释放锁的流程进行优化,如下图所示。
在获取/shared下子列表后,不为每个子节点注册监听。获取锁失败后,只在比自己"小"的节点上注册Watcher,这里的"小"需要区分读请求和写请求。
- 如果是读请求,比自己小的子节点就是上一个写请求对应的节点。
- 如果是写请求,比自己小的子节点,就是序号比自己小的上一个节点。
以下是改善前后注册Watcher监听示意图对比,可以明显看到两种节点注册的理念不一样,改善后的节点,只关心比它小的节点情况,这样只在小范围内进行信息传递就可以实现共享锁的释放后再获取。
以上,理解不一定正确,学习就是一个不断认识和纠错的过程,如果有误还请批评指正。
PS:人生,成功只是暂时的,失败却是主旋律,面对失败的态度,将人分成不同的样子。
参考博文:
(1)《从Paxos到Zookeeper-分布式一致性原理与实践》分布式锁
(2)http://www.360doc.com/content/18/0528/08/36490684_757590223.shtml 分布式锁漫画