接下来,记录下Zookeeper在Hadoop HA中相关的作用,部分内容参考文末博文。
HDFS高可用
Zookeeper的一个重要的应用就是实现Hadoop集群的高可用,在Hadoop 1.x版本中只有一个NameNode来负责整个集群的元数据管理,以及与client的交互,如果这个唯一的NameNode宕机,会出现单点故障,无法对外提供服务。
到了Hadoop 2.0版本,出现了HA高可用解决方案,如下图所示会有两个NameNode,一台为主另一台为backup用。其中处于standby备用状态的NameNode也会接收DataNode的block report,它上面的元数据也需要和active状态NameNode的元数据保持一致,其中元数据同步是通过JournalNode来实现的,为了防止同步不可用,JournalNode也会配置成集群。
下图为两个NameNode竞争active的大致过程,竞争失败的会变成standby状态。
- ZKFC进程启动后,会初始化HealthMonitor和ActiveStandbyElector服务,其中HealthMonitor会监控NameNode健康状况。
- HealthMonitor会将监控健康状态结果反馈给ZKFailoverController。
- ZKFailoverController会调用ActiveStandbyElector服务进行主备选举。
- ActiveStandbyElector是通过在Zookeeper中创建临时节点是否抢先,来决定是否发起的NameNode就是active,由于Zookeeper的写一致性,只有保证其中一个创建临时节点成功,另外一个将失败。
- 如果下图中左边的成功,会在Zookeeper集群中创建两个节点,一个为临时节点(ActiveStandbyElectorLock),一个为永久节点(ActiveBreadCrumb),其中临时节点创建成功与否将决定谁是active,而永久节点是为了防止active状态的NameNode非正常退出后再恢复导致的双主脑裂问题,选举的结果会返回到ActiveStandbyElector。
- ActiveStandbyElector服务将主备状态返回到ZKFailoverController。
- ZKFailoverController会将选举成功的NameNode切换为active,失败则为standby状态。
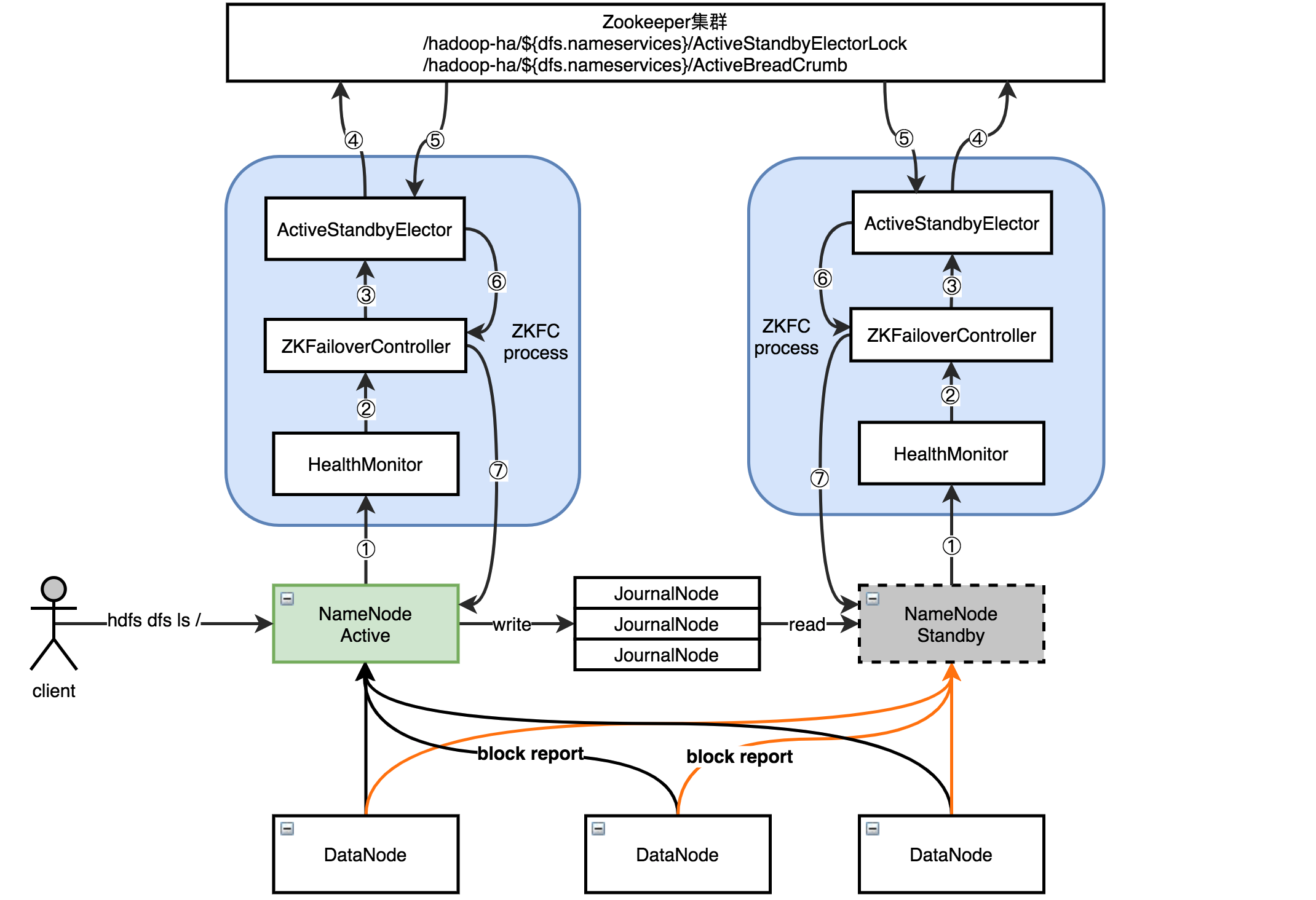
故障恢复主要组件
为了保证active NameNode宕机后,standby→active自动切换实现故障恢复,需要依靠如下几个组件。
- HealthMonitor对象:监控NameNode是否"不可用"或进入"不健康"状态。
- ActiveStandbyElector对象:控制和监控ZK上的节点的状态,一个永久节点一个临时节点。
- ZKFailoverController对象:订阅HealMonitor和ActiveStandbyElector对象发来的event事件,管理NameNode的状态,当NameNode不能提供服务还会负责对它进行隔离。
上面三个组件运行在各自NameNode的JVM中,上图中有两个NameNode,因此运行在两个不同NameNode的JVM中,这三个一起组成一个ZKFC进程。
HealthMonitor
HealthMonitor会定时调用NameNode的HAServiceProtocol RPC接口的monitorHealth和getServiceStatus方法,监控NameNode的健康状态并向ZKFC反馈。具体在doHealthChecks方法中会调用,但是在执行doHealthChecks方法之前,会先执行MonitorDaemon方法,给NameNode发送RPC请求。
MonitorDaemon方法。
private class MonitorDaemon extends Daemon {
private MonitorDaemon() {
super();
setName("Health Monitor for " + targetToMonitor);
setUncaughtExceptionHandler(new UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
LOG.fatal("Health monitor failed", e);
enterState(HealthMonitor.State.HEALTH_MONITOR_FAILED);
}
});
}
@Override
public void run() {
//循环监控
//shouldRun是使用volatile关键字修饰的,初始值是true
while (shouldRun) {
try {
//循环连接直到成功
loopUntilConnected();
//执行一次健康检测
doHealthChecks();
} catch (InterruptedException ie) {
Preconditions.checkState(!shouldRun,
"Interrupted but still supposed to run");
}
}
}
}
doHealthChecks方法。
private void doHealthChecks() throws InterruptedException {
while (shouldRun) {
HAServiceStatus status = null;
boolean healthy = false;
try {
//调用HAServiceProtocol RPC接口的方法
status = proxy.getServiceStatus();
proxy.monitorHealth();
healthy = true;
} catch (Throwable t) {
if (isHealthCheckFailedException(t)) {
LOG.warn("Service health check failed for " + targetToMonitor
+ ": " + t.getMessage());
//进入服务不健康State
enterState(State.SERVICE_UNHEALTHY);
} else {
LOG.warn("Transport-level exception trying to monitor health of " +
targetToMonitor + ": " + t.getCause() + " " + t.getLocalizedMessage());
RPC.stopProxy(proxy);
proxy = null;
//进入服务无响应state
enterState(State.SERVICE_NOT_RESPONDING);
Thread.sleep(sleepAfterDisconnectMillis);
return;
}
}
if (status != null) {
setLastServiceStatus(status);
}
if (healthy) {
//如果正常,进入健康state
enterState(State.SERVICE_HEALTHY);
}
//线程睡眠一段时间,间隔为ha.health-monitor.check-interval.ms中设置的时间
Thread.sleep(checkIntervalMillis);
}
}
描述服务状态使用枚举类型表示,分为5种,常见的就是中间三种,分别为未响应、健康和不健康。
public enum State {
/**
* The health monitor is still starting up.
*/
INITIALIZING,
/**
* The service is not responding to health check RPCs.
*/
SERVICE_NOT_RESPONDING,
/**
* The service is connected and healthy.
*/
SERVICE_HEALTHY,
/**
* The service is running but unhealthy.
*/
SERVICE_UNHEALTHY,
/**
* The health monitor itself failed unrecoverably and can
* no longer provide accurate information.
*/
HEALTH_MONITOR_FAILED;
}
ActiveStandbyElector
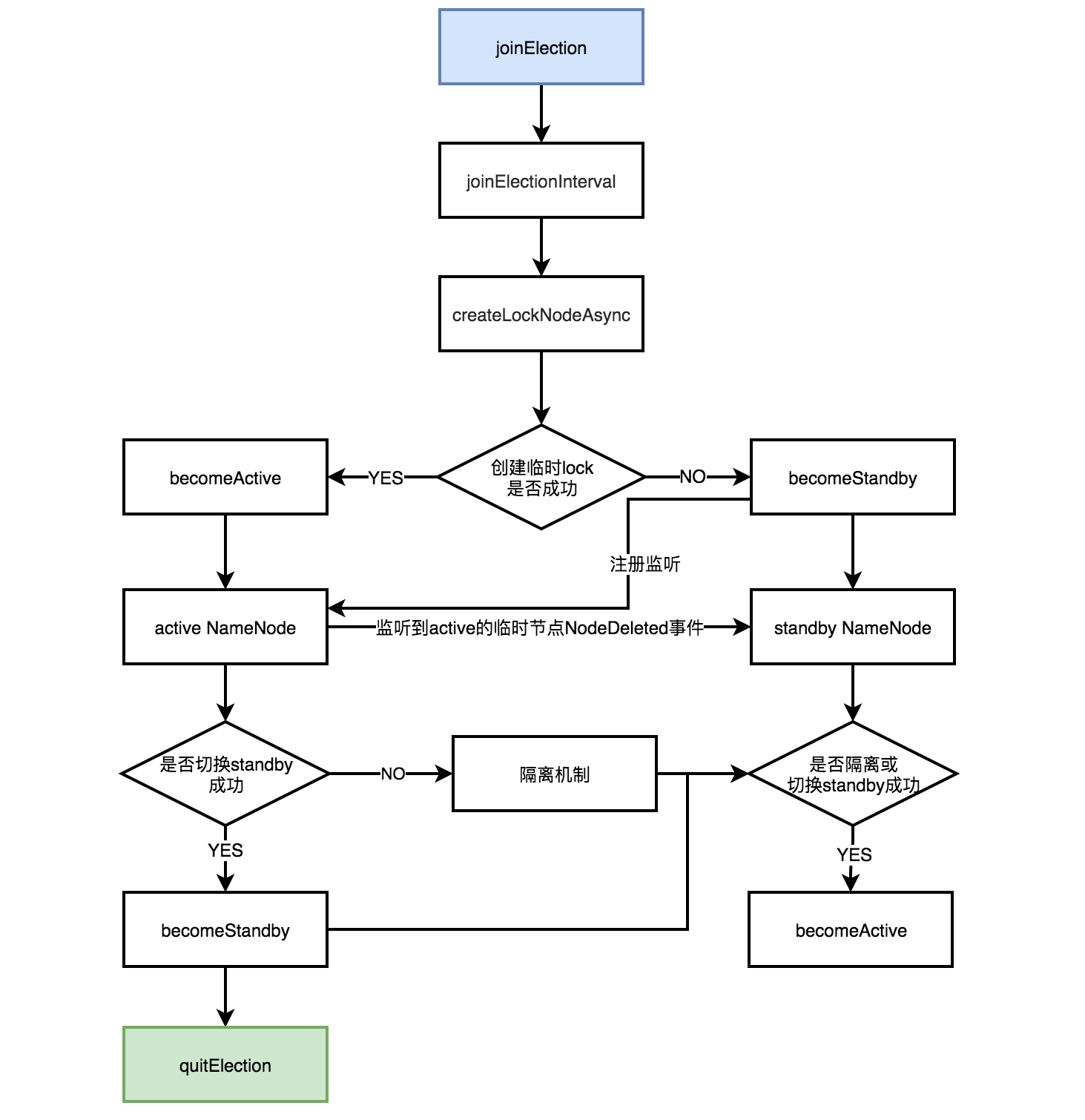
通过ActiveStandbyElector,可以实现对NameNode的主备选举,当发起一次主备选举时,在Zookeeper上会尝试创建临时节点/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,Zookeeper的写一致性保证最终只会有一个znode创建成功。其中dfs.nameservices是自定义的HA服务名,它是逻辑上的服务名,用户不需要关心具体提供的namenode是哪个,只需要连接它就可以享受服务。
如下图所示,就创建了临时znode,其中ns是HA服务名,可以在hdfs-site.xml中定义。除了ActiveStandbyElectorLock,还有另外一个znode,这个节点是持久节点,主要为隔离提供判断依据,防止脑裂,后面会说明。

创建上述临时znode成功所对应的NameNode,就会成为active,即主机名为hadoop01上的NameNode会成为active,而创建失败的则会成为standby。如下图显示hadoop01的状态即为active,说明选主成功。
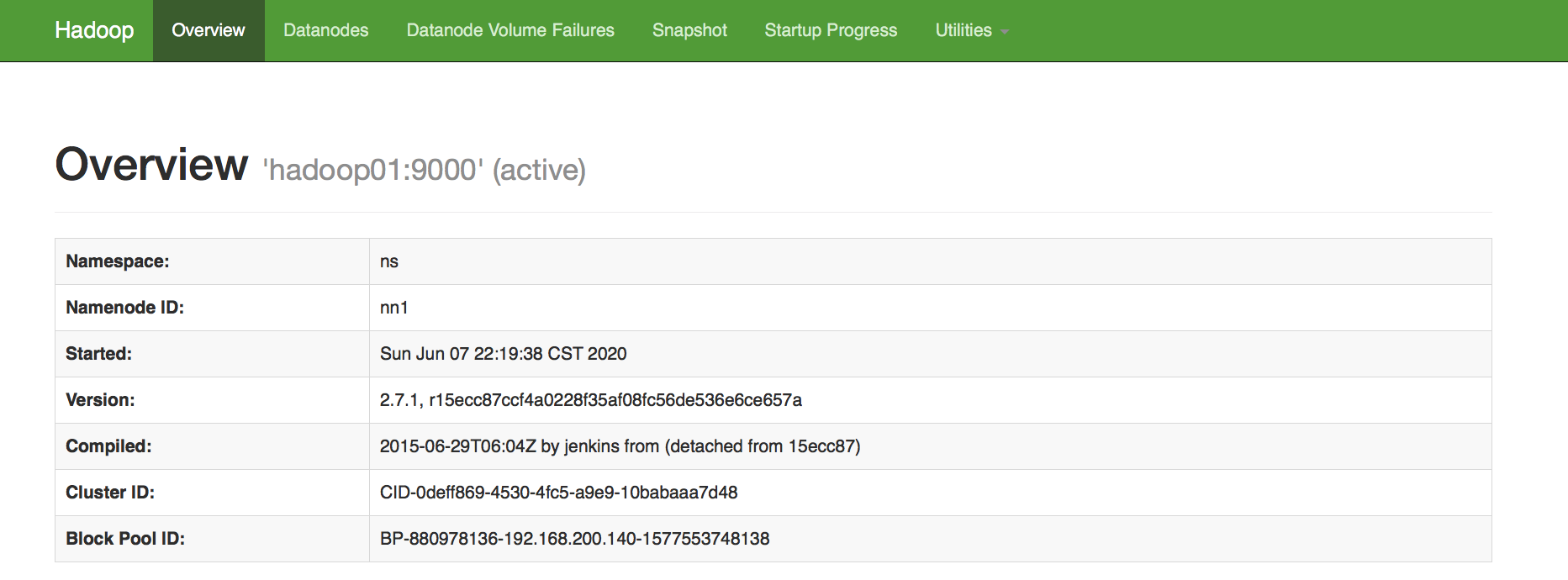
不管选举成功与否,所有ActiveStandbyElector都会在Zookeeper注册一个Watcher来监听这个临时节点的状态变化,如果active NameNode对应的HealthMonitor检测到NameNode状态异常时,会删除在Zookeeper上创建的临时节点ActiveStandbyElectorLock。然后standby NameNode的ActiveStandbyElector注册的Watcher就会收到这个节点的NodeDeleted事件,并会再次创建ActiveStandbyElectorLock,如果成功,则standby NameNode将被选举为active。
以上过程主要通过ActiveStandbyElector的如下几个关键方法实现的,具体方法内容不再记录,可根据此图提示进行查看理解,但是本人水平有限不一定理解准确。
ZKFailoverController
ZKFailoverController类在org.apache.hadoop.ha包下,启动后会初始化HealthMonitor和ActiveStandbyElector对象。
从源码可以看出,ZKFailoverController有两个重要的内部类,一个是ElectorCallbacks,一个是HealthCallbacks,分别负责active节点选举和NameNode的健康监控用。
隔离机制
由于存在双NameNode,会存在两个NameNode都为active的可能,这种情况是不允许发生的,此时上文中提到的ActiveBreadCrumb永久节点就登场了。ActiveBreadCrumb是一个永久znode,如果active NameNode正常退出,这个永久节点和临时节点ActiveStandbyElectorLock都会被删除,但是很多时候情况不是那么乐观,这个永久节点会保留下来。当下个一新的候选NameNode在成功创建新的ActiveStandbyElectorLock后,不会马上切换成active,还需要通过ActiveBreadCrumb获取上一个active NameNode的信息,然后尝试调用老active NameNode的HAServiceProtocol RPC接口的transitionToStandby方法将其切换为standby。如果成功切换那候选NameNode才切换为新的active,否则就会进入Hadoop自带的隔离机制,有sshfence和shellfence两种。
- sshfence:通过ssh远程连接到上一个NameNode,然后执行kill -9命令将zkfc进程强制杀死。
- shellfence:运行一个shell命令将active NameNode隔离。
JournalNode集群
共享存储系统,负责存储HDFS的元数据,Active NameNode写入,Standby NameNode读出,实现元数据同步。在主备切换过程中,新的Active NameNode必须确保元数据和老Active NameNode同步完成,才能对外提供服务。
以上,理解不一定正确并且有限,学习就是一个不断认识和纠错的过程。
参考博文:
(1)https://segmentfault.com/a/1190000007239743 dfs.nameservices
(2)https://www.cnblogs.com/youngchaolin/p/12113127.html hadoop完全分布式
(3)https://blog.csdn.net/SmallCatBaby/article/details/89934380 ZKFC
(4)https://issues.apache.org/jira/browse/HDFS-2185 ZKFC design
(5)https://www.cnblogs.com/aigongsi/archive/2012/04/01/2429166.html volatile关键字