记录下和kafka相关的语义、不重复消息、不丢失数据、分区有序的内容,文中很多理解参考文末博文、书籍还有某前辈。
kafka语义
kafka中有三种语义,它对理解下面的不重复消费有帮助。
最多一次(at most once):消息最多被处理一次,可能有消息丢失的风险。
至少一次(at least once):这种语义下消息可能被处理多次,可以保证消息不丢失,但是可能导致重复消息。
精确一次(exactly once):消息只会被处理一次,at least once+幂等性,可以实现精确一次语义。
重复消费
这是一个很常见的问题,如果保证消费者不重复消费数据,博客上有很多的方法,简单罗列几条如下。
(1)给每条消息加一个独一无二的key,如uuid,消费数据的时候同时记录这些key,下次消费数据时需要检查消息的key,是否已经被消费过了,这样是可以避免重复消费的。
(2)at least once+幂等性,也可以实现,在保证至少一次的语义下,有多种方式实现幂等性,如在关系型数据库如Oracle、MySQL表中设置唯一约束、将数据存储到redis的set、使用set [NX]存储数据到redis,都是一种实现方式。
- 使用主键约束,当插入数据到关系型数据库的时候,第一次插入成功后,下次再次消费数据后插入数据到数据库,会由于主键的唯一约束导致插入失败,这就保证了幂等性。
- redis的set,可以不断的set数据到里面,重复消费和一次消费的效果一样,这也可以保证幂等性。
# 添加set数据 football
127.0.0.1:6379> sadd likes football
(integer) 1
# 查看有一个football
127.0.0.1:6379> smembers likes
1) "football"
# 多次添加football,相当于多次消费到football,进行处理
127.0.0.1:6379> sadd likes football football football
(integer) 0
# 结果依然只有一个,多次sadd,和一次sadd的效果一样,实现幂等
127.0.0.1:6379> smembers likes
1) "football"
- redis可以使用set+[NX]也可以实现幂等,NX选项只容许没有这个数据时才能添加,有就不能添加。
# 添加key=name,value='clyang'成功
127.0.0.1:6379> set name clyang NX
OK
127.0.0.1:6379> get name
"clyang"
# 再次添加,失败,实现幂等
127.0.0.1:6379> set name clyang NX
(nil)
以上的例子可以看出,不仅仅关系型数据库,nosql也可以实现,只要能实现"INSERT IF NOT EXISTS"语义的存储系统都可以实现幂等效果。
(3)在消费数据之前,设置一个前提条件,并且消费完数据之后,需要修改前提条件的状态,这样也可以避免重复消费。
- 比如给用户转账,必须满足余额等于100,余额加100元才能执行,消息里需要带上余额信息,当消息里余额信息和数据库里的余额不相等时,就不会再执行修改余额的操作。当第一次有类似{'余额':100,'加金额':100}的消息要处理时,由于满足条件会执行余额更新的操作变成200,但后面的重复消息,因为消息里的余额不等于数据库里的余额(上一次更新为200了),导致修改失败,这样也保证了幂等性。
- 上面是数字类型的的情况,如果是非数字或其他复杂的情况,该如何处理,参考前人,通用的方法是给消息里的数据,增加一个版本号,消费消息更新数据前,需要检查数据里的版本号和消息里的版本号,如果不一样就不能更新,并且更新后数据里版本号+1,这样也可以实现幂等性。
# 第一次消费,数据里没有这条消息,可以消费,并且数据里版本号+1变成2
{'msg':'当光照进来的时候,你嘴角上扬的骄傲就是最大的回报',versionId=1}
# 再一次消费,由于消息版本号是1,数据里版本号是2,无法消费
{'msg':'当光照进来的时候,你嘴角上扬的骄傲就是最大的回报',versionId=1}
# 同上,无法消费
{'msg':'当光照进来的时候,你嘴角上扬的骄傲就是最大的回报',versionId=1}
丢失数据
如何规避数据不丢失,参考文末博文,需要从producer、consumer和broker三方面考虑。关于丢失数据问题,如果当一个学术问题来考虑,是一种情况,如果是实际生产环境,又是另外一种情况,需要注意区分。
producer
(1)acks
生产者可以设置acks=-1或者all,保证发送到broker的消息不丢失。这样设置是当消息发送到了leader副本,所有处于ISR列表中的follower副本都需要同步到这条数据,才可以。
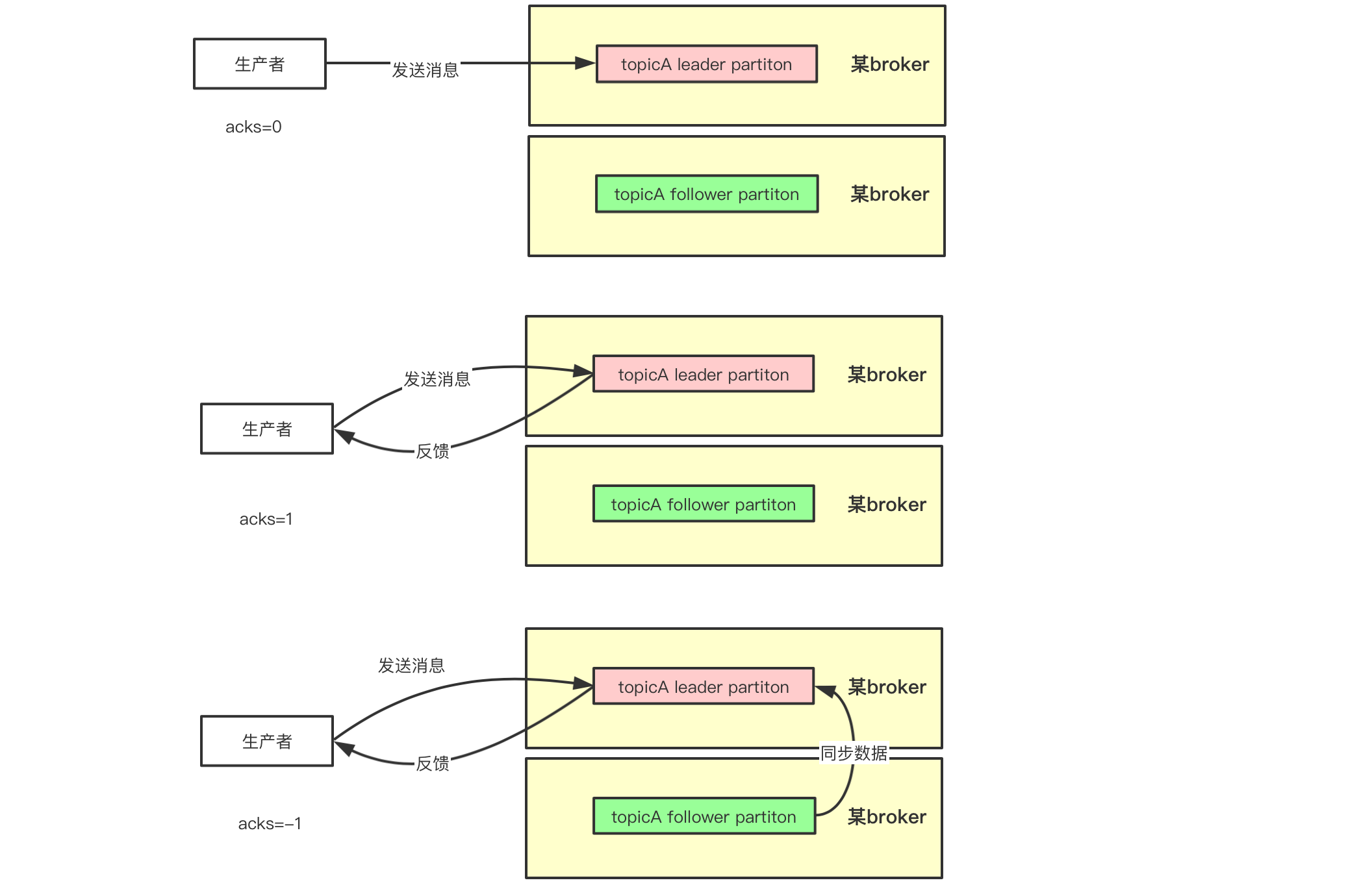
- acks=-1:代表所有处于ISR列表中的follower partition都会同步写入消息成功,才会返回ack到生产者
- acks=0:代表消息只要发送出去就行,其他不管,无需返回ack到生产者
- acks=1:代表发送消息到leader partition写入成功就返回ack到生产者
//注意代码中配置时,-1是字符串,不是数字
props.put("acks","-1");
(2)retry
在kafka中错误分为两种,一种是可恢复的,另一种是不可恢复的。生产时,使用带有回调的send方法,当遇到可以恢复的错误(如网络波动、leader选举中leader副本不可用的情况),设置retry次数和retry时间间隔后,在retry次数范围内都不会进入onCompletition方法,多次尝试(可以设置为Integer.MAX_VALUE)就会大概率成功发送。如果是不可以恢复的错误(如一条消息的最大大小超过max.request.size设置),最后肯定会进入下面的方法,可以做退而求其次的操作保证数据能保存,如将数据存储到redis。
//生产者部分代码
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("消息发送到分区成功");
}else{
System.out.println("消息发送失败");
//TODO 写入到redis
}
}
});
其他参考《Apache Kafka实战》 4.6.1。
broker
(1)unclean.leader.election.enable=false
这个参数设置是否允许从非ISR列表中选取副本为leader副本,默认值是false,如果设置为了true,意味着可以从ISR列表以外选举leader副本,这些ISR列表之外的副本,由于同步赶不上leader副本的更新进度,让它们变成leader副本,就会出现HW水位被截断的情况,导致数据丢失。
(2)replication.factor>=2
多副本是保证HA的前提,它使得某些broker即使宕机,依然可以对外提供服务,提高容错性能。上面数值设置为2代表需要设置多个副本,不是说2个就行,一般3-5个,太多也会提高网络开销。
(3)min.insync.replicas>=2
分区ISR中至少有多少个副本,它至少有一个,即leader副本,需要设置为大于1个。如果只有1个则leader副本挂掉则不能提供服务。它需要配合上面acks=-1来使用,代表所有IRS中的副本都数据同步,其中一个挂掉,只要能保证有一个能提供服务,就可以。
注意,上面replication.factor需要配置大于min.insync.replicas,代表容许一些副本可以'掉队',如果设置相等,则系统变脆了,即一个副本都不能落后,只要一个落后就会导致不能满足上面最后一个条件,可用性降低。
如下图所示,当配置replication.factor=3,min.insync.replicas=2,这样保证在ISR中至少有两个副本(图示为[0,1]),万一当前leader副本宕机了,ISR为1的broker上的副本将顶替成为leader副本,配合acks=-1的设置,数据不会丢失。当配置replication.factor=3,min.insync.replicas=1,则坏的情况是两个follower副本都跟不上leader副本的节奏,导致IRS中只有1个副本,这样万一这个副本宕机,其他的副本由于数据不同步,unclean.leader.election.enable设置为true就会被选举为leader副本就会出现数据丢失,这个时候设置acks=-1也显示没啥意义,该丢还是得丢。
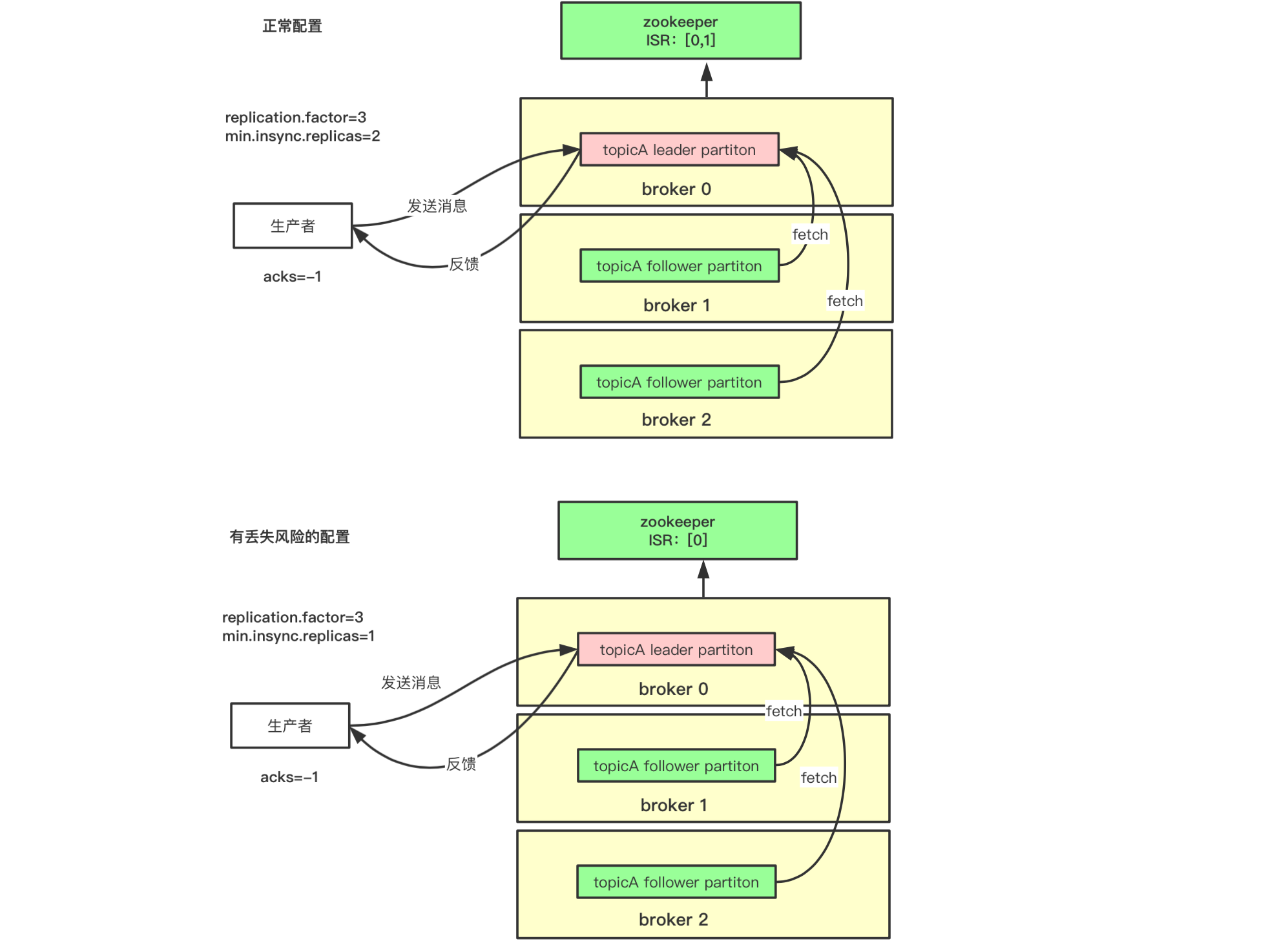
另外查看主题topicA的1号分区ISR列表[1,2,0],可以看出有三个,数字代表所在的broker id。
[zk: localhost:2181(CONNECTED) 14] get /brokers/topics/topicA/partitions/1/state
{"controller_epoch":242,"leader":1,"version":1,"leader_epoch":75,"isr":[1,2,0]}
cZxid = 0x7500000106
ctime = Fri Mar 20 20:29:52 CST 2020
mZxid = 0x9200000064
mtime = Fri Apr 10 19:44:54 CST 2020
pZxid = 0x7500000106
cversion = 0
dataVersion = 186
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 79
numChildren = 0
consumer
消费者部分,一般来说现在使用spark streaming或者flink来处理,很少单独写消费者代码,为了理解问题暂时按照普通的消费者代码来处理。
一般来说,消费者需要设置enable.auto.commit = false来关闭自动提交消费者offset,改为手动提交的方式,在正常处理完数据再提交,如果处理失败就保存上次处理成功的offset,这次的不提交,这样可以规避丢失数据。
enable.auto.commit默认是true的,并且设置true的情况下还需要通过auto.commit.interval.ms设置提交的时间间隔来一起使用,代表每隔多久自动提交一次。这样是有丢失风险的,假设消费者代码按照如下的设置,如果某一次消费了100条数据,过了1秒自动提交了消费者offset,但是消费者还没处理完,可能处理到了第80条,就不幸宕机了,再次重启消费,发现81-100这个区间的消息消费不到了,造成数据的丢失。
//设置自动提交offset
props.put("enable.auto.commit","true");//注意kafka版本
//多久自动提交offset
props.put("auto.commit.interval.ms",1000);
分区有序
同一个分区的数据,默认是有序的,因此有如下两种方案。
-
方案1:topic只设置一个分区,这样消息就是全局有序,但是consumer group中只有一个consumer能消费,不能多个线程同时消费数据,一定程度上降低了性能。
-
方案2:topic可能有多个分区,但是可以指定消息的key,使得需要保证顺序的消息都发送到同一个分区,这样消费数据时消息也是有序的。
但是以上两种情况存在一个坑,参考文末博文,当producer发送消息时因为某些原因如网络延迟导致retry时,消息有重新排列失去有序性的风险,具体需要修改max.in.flight.requests.per.connection参数的值为1(默认为5),以下是官网对这个参数的解释。
The maximum number of unacknowledged requests the client will send on a single connection before blocking. Note that if this setting is set to be greater than 1 and there are failed sends, there is a risk of message re-ordering due to retries (i.e., if retries are enabled).
翻译一下大概意思就是,在producer向broker发送消息时,在一个connection上不阻塞的前提下,可以存在未及时返回ack的请求的最大数量。如果这个数值超过了1,并且用户设置了retry功能,则在请求发送存在失败时将有消息重排的风险。
如下所示,假设上面参数设置为4,则一个连接中可以发送4个请求,如果正常发送到了broker,则消息按照正常的顺序保存在log文件,最后是买房->买车->彩礼->成家的顺序。如果消息1、2、3在发送中有retry,多次发送后才成功,则有可能导致最后消息在log文件中顺序是成家->买房->买车->彩礼的顺序,如果按照这个顺序消费,估计作为消费者的丈母娘是不能容忍的,所以上面的参数需要设置为1,这样将保证买房->买车->彩礼->结婚的顺序,即真正的分区有序,但是也是有代价的,会降低一点性能。

以上,理解不一定正确,学习就是一个不断认识和纠错的过程。
参考博文:
(1)《Apache Kafka实战》
(2)https://segmentfault.com/a/1190000015316545 retry消息重排风险
(3)https://www.cnblogs.com/youngchaolin/p/11972899.html#_label4_4
(4)https://www.cnblogs.com/MrRightZhao/p/11498952.html kafka数据不丢失