以MapReduce为例,提交一个MapReduce application的大致流程如下,其中Resource Manager简写为RM,Node Manager简写为NM,Application Master简写为AM。
提交application大致流程
(1)首先client里执行一个MapReduce程序,这个程序运行在client端的JVM里,在main方法中最后有一个job.waitForCompletion(true)方法,当执行这个方法后会触发job.submitJob方法,准备向RM提交一个application。
(2)RM接受到请求后,会为这个application生成一个application +id编号,并且client会检查输出路径是否已存在,输入输出路径信息是否齐全。不管检查有问题与否,RM都会给client端返回信息,其包括运行这个job所需要的资源,如运行在哪个NM上,需要的container信息。
一个简单的MapReduce程序中application+id编号示例,测试发现需要hadoop jar运行才显示:

(3)如果返回的信息提示路径已存在,或者job运行的参数不够,会退出程序,否则可以继续执行这个job,这个时候client端会将程序的jar包,以及运行所需配置信息,以及分片信息发送到HDFS(这些文件保存的上级目录即前面生成的application+id编号,默认会拷贝10份,如果只有3个节点则多余的7份会删除),让jar包和配置信息等保存在各个datanode上,这对分布式集群计算拉取资源来说是有利的,比直接从client端拉取资源会更加高效。
(4)前面准备没问题后,client端向RM提交这个application。RM收到提交后,调度器scheduler将会为它分配container资源,application manager将创建application master。
(5)RM在接受到application提交后,根据资源调度算法计算的结果(包括运行job所在的节点在哪,运行所需要的资源container是多少),会先在计算得到的某个NM上启动一个container,用于启动AM,这个AM是运行MapReduce job前的准备,它启动后后续请求资源就在client端和AM之间进行了。
(6)在客户端执行一个MapReduce程序时,能看到Map和Reduce任务执行的进度百分比,这个是AM在执行initialize job后创建的薄记对象完成的,这个薄记对象会收集运行在分布式各个节点上任务的进度,汇总后定时发送给client。
(7)在执行MapReduce程序时,会先执行Map任务然后再执行Reduce任务(默认是执行Map任务5%后再执行Reduce任务),其中Map任务的个数是由分片数决定的,即通过InputFormat的getSplit方法得到的分片数,这个分片的信息需要从HDFS获取,里面保存的是指向实际分片信息的引用。而Reduce任务的个数则是程序中指定的,通过setNumReduces(num)来指定。
(8)MapReduce任务先执行Map task,先以Map task为例,后面Reduce task执行流程也可参考。当准备执行Map task时,AM会向RM继续发送请求,即resource-request请求,请求获取计算的NM和container信息。
(9)得到返回信息后,AM会给NM发送container-launch-specification信息(包含AM和NM交流所需要的资料),在NM上启动container,并准备执行task程序,container会将task运行的进度、状态等信息通过 application-specific协议发送给ApplicationMaster,也是通过application-specific协议client通过AM获取到了task运行的进度和状态信息。
(10)执行task程序部分,是在一个叫做Yarn Child的主类java application中进行的,这个类在执行task程序之前,会向HDFS获取jar包和配置信息。
(11)在获取到HDFS的jar包和配置信息后就开始运行task,如果是Map task则输出的key-value对会保存到各自的分区中去,如果是Reduce task则会从对应的map分区中拉取数据准备进行合并、排序和分组,最后执行reduce分组计算并输出到HDFS。不管是Map task还是Reduce Task其都会向AM上报执行情况。
(12)最后执行完MapReduce任务后,保存在分区中的Map输出信息将删除,此外保存在HDFS中的jar包信息、配置信息和分片信息也将删除。
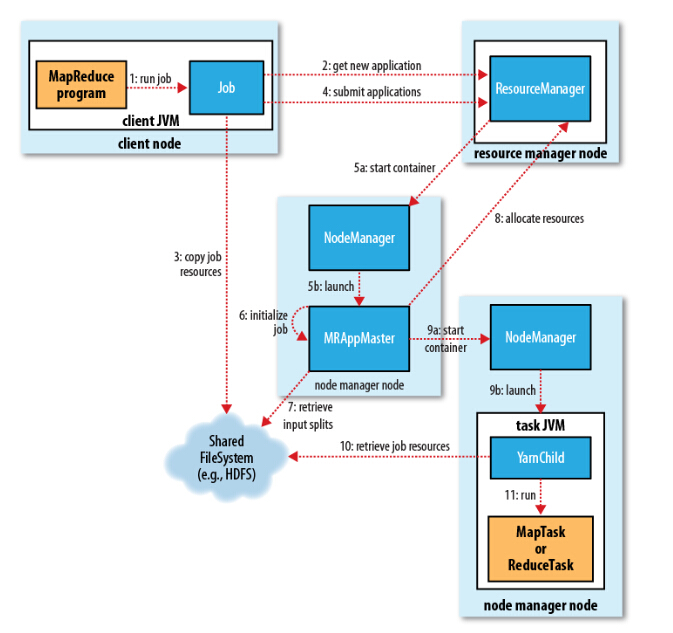
以上为MapReduce提交job到yarn的过程,后续再补充完善。
参考博文:
(1)《hadoop核心权威指南第四版》