目录
1 概述
1 概述
Hashtable是一个比较古老的Map实现类,从它的名称就可以看得出来,因为没有遵循Java的语言规范。它和HashMap很像,同属于散列表,有以下特性:
- 首先就是线程安全,这也估计算是唯一一个优于HashMap的特性了吧;
- Hashtable不允许key或者value为null;
- 自从JDK1.2开始,Hashtable实现了Map接口,成为了Map容器中的一员。看样子最开始是不属于Map容器的。
- 不建议使用,以后说不定哪天就废掉了。连官方文档也说了,如果在非线程安全的情况下使用,建议使用HashMap替换,如果在线程安全的情况下使用,建议使用ConcurrentHashMap替换。
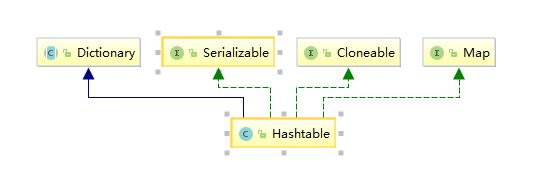
Hashtable是继承自古老的Dictionary类,而Dictionary类,顾名思义,就是字典类,算是早期的Map,不过该类基本上已经废弃了。为什么废弃呢,大致看下Dictionary的源码就知道了。除了常规的get,put请求外,还提供了一些遍历的方法,返回的是Enumeration类型。而Enumeration接口其实算是被Iterator替换了,因为Iterator提供的功能更多,更方便。所以,就目前而言,Dictionary存在的意义恐怕就只是为了兼容原来继承它的一些类了吧。
2 源码分析
2.1 成员变量
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { // Hashtable保存数据的数组 private transient Entry<?,?>[] table; // hashtable的容量 private transient int count; // 阈值 private int threshold; // 负载因子 private float loadFactor; // 结构性修改 private transient int modCount = 0; }
2.2 核心方法
- Hashtable底层是通过数组加链表来实现的。
- Hashtable并没有太多的常量,比如默认容量大小都是直接写在代码中,而没使用常量。
- 从它的构造函数我们可以知道,Hashtable默认capacity是11,默认负载因子是0.75.。
2.2.1 put方法
// put是synchronized方法 public synchronized V put(K key, V value) { // 首先就是确保value不能为空 if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); // 计算数组的index int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; // 如果index处已经有值,并且通过比较hash和equals方法之后,如果有相同key的替换,返回旧值 for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } // 添加数组 addEntry(hash, key, value, index); return null; }
private void addEntry(int hash, K key, V value, int index) { modCount++; Entry<?,?> tab[] = table; // 如果容量大于了阈值,扩容 if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>) tab[index]; // 在数组索引index位置保存 tab[index] = new Entry<>(hash, key, value, e); count++; }
- 通过
tab[index] = new Entry<>(hash, key, value, e);这一行代码,并且根据Entry的构造方法,我们可以知道,Hashtable是在链表的头部添加元素的,而HashMap是尾部添加的,这点可以注意下。 - Hashtable计算数组index的方式和HashMap有点不同,
int index = (hash & 0x7FFFFFFF) % tab.length;0x7FFFFFFF也就是Integer.MAX_VALUE,也就是2的32次方-1,二进制的话也就是11111111...,那么(hash&0x7FFFFFFF)的含义看来看去好像只有对符号位有效了,就是负数的时候,应该是为了过滤负数,而后面的取模就很简单了,把index的取值限制在数组的长度之内。
protected void rehash() { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; // 扩容为原来的2倍加1 int newCapacity = (oldCapacity << 1) + 1; // 扩容后的数量校验 if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) // Keep running with MAX_ARRAY_SIZE buckets return; newCapacity = MAX_ARRAY_SIZE; } // 新数组 Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++; // 阈值计算 threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); table = newMap; // 双层循环,将原数组中数据复制到新数组中 for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; // 重新根据hash计算index int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
get方法
public synchronized V get(Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); // 计算数组index int index = (hash & 0x7FFFFFFF) % tab.length; // 比较返回 for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } } return null; }
总结
- 首先,Hashtable底层是通过数组加链表实现的,这点和JDK1.8之前的HashMap差不多。
- 其次,Hashtable是不允许key或者value为null的。
- 并且,Hashtable的计算索引方法,默认容量大小,扩容方法都与HashMap不太一样。
- 其实我们可以看到,Hashtable之所以线程安全,大部分方法都是使用了synchronized关键字,虽然JDK优化了synchronized,但在方法上使用该关键字,无疑仍旧是效率低下的操作。就这方面来说,ConcurrentHashMap无疑比Hashtable好多了,后续会有专门文章介绍ConcurrentHashMap,这里就不多说了。
总之呢,Hashtable无疑算是废掉了,说不定过不了多久,它就消失在Map框架中了呢。
0