先上总结
Unicode 是一个符号集, 规定了所有符号的二进制编号.
UTF8 是unicode的一种编码方式(存储, 传输方式)
参考: http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
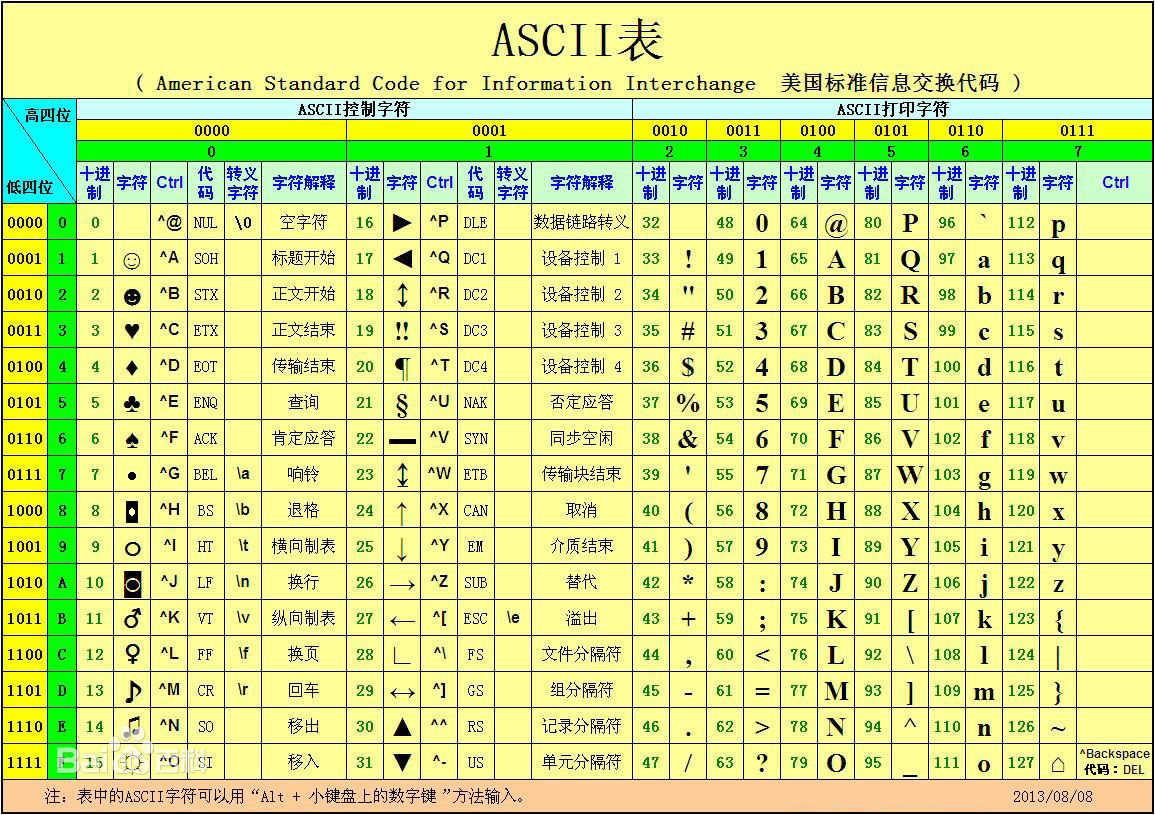
ASCII
ascii码范围: 1~128, 只需要1个字节, 最前面的一位固定为 0
unicode 编码占用3个字节, 它包含了所有的字符
Unicode 只是一个符号集,它只规定了符号的二进制代码,没有规定这个二进制代码如何存储。
存储Unicode的编码方式的常用方式:
-
utf-8 变长编码, 长度从 1个字节~6个字节不等
-
utf-16 占用2个字节
-
utf-32 占用4个字节
utf-8 编码规则
- 对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 - 对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
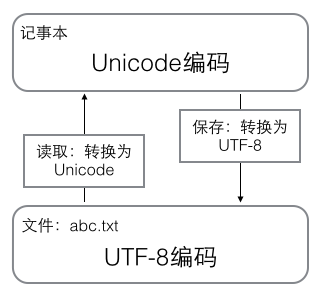
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
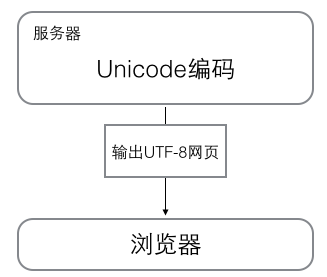
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
作者:Deft_MKJing宓珂璟
来源:CSDN
原文:https://blog.csdn.net/Deft_MKJing/article/details/79460485
版权声明:本文为博主原创文章,转载请附上博文链接!
UTF-16
字节顺序标记(Byte Order Mark, BOM), 位于文档开头的前2个字节, 用于标记存储的字节序, 是按 "大端"还是"小端"顺序存储.
借个图(UTF8你 的utf8编码存储文件内容):

feff 表示内容是按大端序存储: 高位字节放在内存的低地址,低位字节放在内存的高地址
fffe表示内容是按小端序存储:低位字节放在内存的低地址,高位字节放在内存的高地址。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF
U 的UTF16编码是 0055, 但按照小端序存储时是 5500
注意, utf8并没有这个烦恼, 不要搞乱.
在UTF16下,存储的字节值和unicode是一一对应的。但是UTF16显示英文(asni)就浪费一个字节。
其他
英文字符编码 ANSI
简体中文 GB2312
繁体中文 Big5