JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。
但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
注意:在v6.0之前创建Buffer对象直接使用new Buffer()构造函数来创建对象实例,但是Buffer对内存的权限操作相比很大,可以直接捕获一些敏感信息,所以在v6.0以后,官方文档里面建议使用 Buffer.from() 接口去创建Buffer对象。
1.Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
示例代码(buffer.js):
const buf = Buffer.from('yctech', 'ascii');
// 输出 72756e6f6f62
console.log(buf.toString('hex'));
// 输出 cnVub29i
console.log(buf.toString('base64'));
运行输出结果为:

Node.js 目前支持的字符编码包括:
-
ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
-
utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
-
utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
-
ucs2 - utf16le 的别名。
-
base64 - Base64 编码。
-
latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
-
binary - latin1 的别名。
-
hex - 将每个字节编码为两个十六进制字符。
2.创建 Buffer 类
Buffer 提供了以下 API 来创建 Buffer 类:
- Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
- Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
- Buffer.allocUnsafeSlow(size)
- Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
- Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
- Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
- Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
test.js
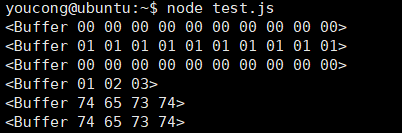
//创建一个长度为10,且用0填充的Buffer const buf1 = Buffer.alloc(10); //创建一个长度为10,且用0x1填充的Buffer const buf2 = Buffer.alloc(10,1); //创建一个长度为10,且未初始化的Buffer //这个方法比调用Buffer.alloc()更快 //但返回的Buffer实例可能包含旧数据 //因此需要使用fill()或者write()重写 const buf3 = Buffer.allocUnsafe(10); //创建一个包含[0x1,0x2,0x3]的Buffer const buf4 = Buffer.from([1,2,3]); //创建一个包含UTF-8字节[0x74,0xc3,0x73,0x74]的Buffer const buf5 = Buffer.from('test'); //创建一个包含Latin-1字节[0x74,0xe9,0x73,0x74]的Buffer const buf6 = Buffer.from('test','latin1') console.log(buf1); console.log(buf2); console.log(buf3); console.log(buf4); console.log(buf5); console.log(buf6);
运行结果为:
3.写入缓冲区
语法如下:
buf.write(string[, offset[, length]][, encoding])
参数
参数描述如下:
-
string - 写入缓冲区的字符串。
-
offset - 缓冲区开始写入的索引值,默认为 0 。
-
length - 写入的字节数,默认为 buffer.length
-
encoding - 使用的编码。默认为 'utf8' 。
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。 length 参数是写入的字节数。 如果 buf 没有足够的空间保存整个字符串,则只会写入 string 的一部分。 只部分解码的字符不会被写入。
返回值
返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
示例代码(test.js):
buf = Buffer.alloc(256); len = buf.write("www.youcongtech.com"); console.log("写入字节数:"+len);
运行后输出结果为:

4.缓冲区读取数据
语法如下:
buf.toString([encoding[, start[, end]]])
参数
参数描述如下:
-
encoding - 使用的编码。默认为 'utf8' 。
-
start - 指定开始读取的索引位置,默认为 0。
-
end - 结束位置,默认为缓冲区的末尾。
返回值
解码缓冲区数据并使用指定的编码返回字符串。
示例(test.js):
buf = Buffer.alloc(26); for (var i = 0;i < 26; i++){ buf[i] = i+97; } console.log(buf.toString('ascii')); console.log(buf.toString('ascii',0,5)); console.log(buf.toString('utf8',0,5)); console.log(buf.toString(undefined,0,5));
运行并输出结果:
