水平分片方案
唯一ID:分布式ID生成算法 snowflake
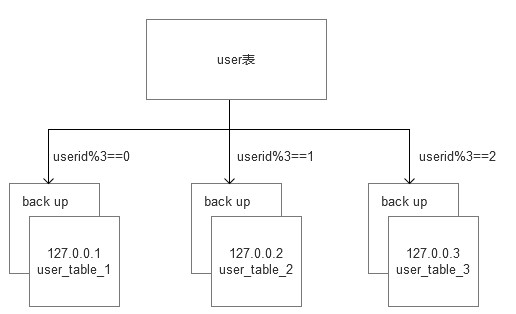
一般会将一张大表的唯一键作为 hash 的 key,比如我们想要水平拆分的是一张拥有3千万行数据的用户表,我们可以利用唯一的字段用户id作为拆分的依据,
这样就可以依据如下的方式,将用户表水平拆分成3张,下面是伪代码,将老的用户数据导入到新的3个被水平拆分的数据表中
if userId % 3 == 0: #insert data in user_table (user_table_0 databaseip: 127.0.0.1) elif userId % 3 == 1: #insert data in user_table (user_table_1 databaseip: 127.0.0.2) else: #insert data in user_table (user_table_2 databaseip: 127.0.0.3)
我们还会对拆分后的每一个sharding 表,做一个双主 master 的副本集备份,至于backup,我们则可以使用 percona的cluster来解决。它是比 mysql m/s 或者 m/m 更靠谱的方案。(percona : https://www.cnblogs.com/keme/p/10239838.html)
所以最后拆分的拓扑图大致如下:
随着我们的业务增长,数据涨到5千万了,慢慢的发现3个sharding不能满足我们的需求了,所以这时候BOSS打算再加2个sharding,以后会慢慢加到10个sharding。
所以我们得在之前的3台sharding服务器上分别执行导入数据代码,将数据根据新的hash规则导入到每台sharding服务器上。几乎5千万行数据每行都移动了一遍,如果服务器够牛逼,Mysql每秒的插入性能能高达 2000/s,即使这样整个操作,都要让服务暂停8个小时左右。这时候DBA的脸色已经不好看了,他应该是已经通宵在导数据了。
那有没有一种更好的办法,让添加或者删除 sharding 节点对整个分片系统的数据迁移量最小呢?
我们可以利用一致性哈希算法,把唯一ID散列到各个 sharding 节点,这样就可以保证添加和删除节点数据迁移影响较小。关于什么是一致性哈性算法,为什么它能做到数据迁移量最小?参考其算法实现
那么什么时候我们需要利用一致性哈希水平拆分数据库单表呢?
1、当我们拥有一个数据量非常大的单表,比如上亿条数据。
2、不仅数据量巨大,这个单表的访问读写也非常频繁,单机已经无法抗住 I/O 操作。
3、此表无事务性操作,如果涉及分布式事务是相当复杂的事情,在拆分此类表需要异常小心。
4、查询条件单一,对此表的查询更新条件常用的仅有1-2个字段,比如用户表中的用户id或用户名。
最后,这样的拆分也是会带来负面性的,当水平拆分了一个大表,不得不去修改应用程序或者开发db代理层中间件,这样会加大开发周期、难度和系统复杂性。