一、预计用时:
(1)明确作业要求:20min;
(2)遍历文件夹中所有符合格式要求的文件:1h;
(3)从文件内容中提取出合法的单词:1.5h;
(4)Simple mode 词频统计:1h;
(5)extend mode 词频统计:1h;
(6)“单词:词频” 排序输出,预计用时1h;
(7)测试与调试:4h;
(8)程序优化:2h;
预计花费总时间:11~12h
二、实际用时:
(1)遍历文件夹中所有符合格式要求的文件:并不像想象中的那么简单,在网上找了一些资料,用时2h;
参考:http://wenku.baidu.com/view/62c6a4d0240c844769eaeea2.html
http://www.cnblogs.com/linckle/archive/2007/09/29/911208.html
(2)从文件内容中提取出合法的单词:刚开始试图自己写函数,写到脑子散掉也写不好,后来在同学的推荐下使用正则表达式,用时2.5h;
(3)词频统计:使用List做容器,共计用时2h
(4)“单词:词频” 排序与输出:用时30min;
(5)测试与调试:1h;
(6)程序优化:首先想到将排序改为冒泡排序,但是发现作用不大。后来意识到可能是容器的问题,故将容器改为两个Dictionary同步处理单词和词频的形式,大大优化了速度,用时1.5h;
共用时:9.5h (不包括看书学习与休息玩耍时间)
三、程序性能分析与优化
刚开始很天真的拿自己编辑的文本去测试,发现由于单词数太少什么都看不出来,后来在同学的提醒下用英文小说去进行性能分析测试。
两部英文txt小说的路径与大小如下:
性能分析结果如下:
simple mode:

extend mode:
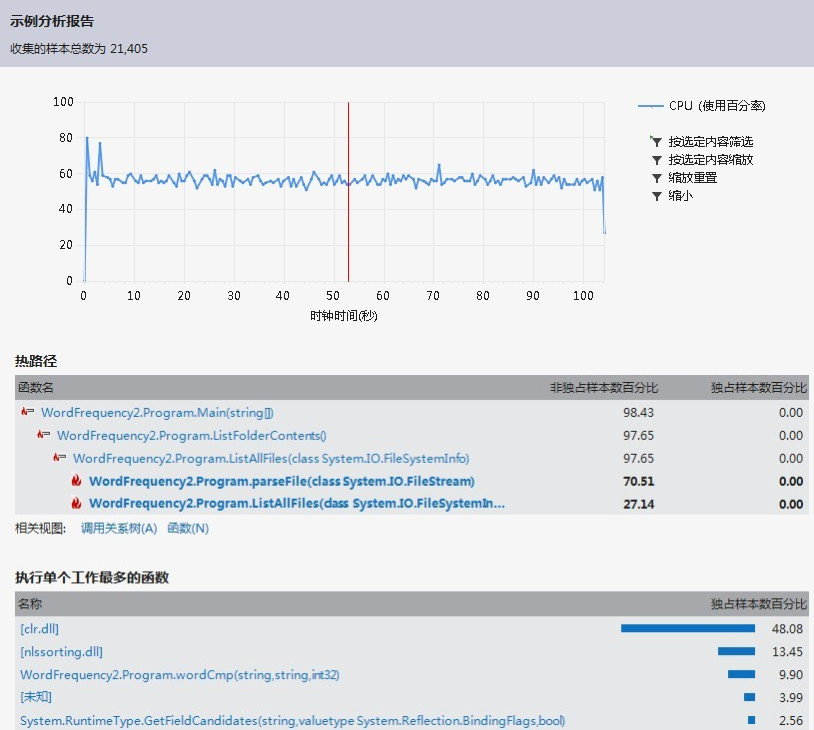
这个结果真的让我非常郁闷。可以看到程序的性能瓶颈为parseFile()这么一个过渡用的函数,令我一开始无从下手优化。
parseFile()的代码如下(可以忽略不看):
private void parseFile(FileStream file) {
try {
StreamReader streamReader = new StreamReader(file);
string content = streamReader.ReadToEnd();
if (content != null) {
//对文件中的内容进行处理
parseContent(content);
}
streamReader.Close();
}
catch (System.Exception ex) {
Console.Write(ex.Message);
}
return;
}
第一次优化(失败)
于是我想到能不能去优化一下排序看看。
冒泡排序的代码(可以忽略不看):
void bubbleSort()
{
int listLen = wordList.Count;
resultList = new word[listLen];
for (int i = 0; i < listLen; i++)
{
resultList[i] = wordList[i];
}
for(int i = 0; i < listLen - 1; i++)
for(int j = 0; j < listLen-i-1; j++)
if(resultList[j+1].num > resultList[j].num)
{
word tmp = resultList[j+1];
resultList[j+1] = resultList[j];
resultList[j] = tmp;
}
else if(resultList[j+1].num == resultList[j].num)
{
if (string.CompareOrdinal(resultList[j+1].value, resultList[j].value) < 0)
{
word tmp = resultList[j+1];
resultList[j+1] = resultList[j];
resultList[j] = tmp;
}
}
}
修改后的性能分析结果没有什么变化:

第二次优化(成功)
后来我想到可能是因为parseFile()中的parseContent()函数中使用到的List的关系。由于List无法直接修改元素的值,每次更新元素信息都得删除旧元素再增加 新元素,导致性能变差。
然后我了解到C#中有Dictionary<K, V>这种键/值对类型的集合。我想到可以用两个Key相同的Dictionary集合,一个的值为单词的最小字典序形式,另一个值 为单词的频数(如下所示):
wordValue = new Dictionary<string, string>();
wordNum = new Dictionary<string, int>();
具体代码如下:
private void parseContent(string content)
{
//构造“分隔符+单词”形式的正则表达式,为了杜绝将形如“123word”的字符串当作单词匹配进来。
string pattern = "[^A-Za-z0-9][A-Za-z]{4}[A-Za-z0-9]*";
Regex rgx = new Regex(pattern);
//为了配合上述的正则表达式,在文本的开头加一个分隔符,防止漏掉以单词开头的情况。
content = " " + content;
//将所有匹配的字符串提取出来放到集合中
MatchCollection fakeWordsClct = rgx.Matches(content);
for (int i = 0; i < fakeWordsClct.Count; i++)
{
bool flag = false;
string legalWord = fakeWordsClct[i].ToString().Substring(1); // 去掉首位的分隔符
foreach (var item in wordValue)
{
string existWord = item.Value;
//如果新单词在列表中已存在
if (wordCmp(existWord, legalWord, mode) == 0)
{
wordNum[item.Key]++;
//维护:取字典序小的值
if (string.CompareOrdinal(existWord, legalWord) < 0)
wordValue[item.Key] = existWord;
else
wordValue[item.Key] = legalWord;
flag = true;
break;
}
}
//如果新单词在列表中不存在
if (!flag)
{
wordValue[legalWord] = legalWord;
wordNum[legalWord] = 1;
}
}
}
修改后的性能分析结果:
simple mode:
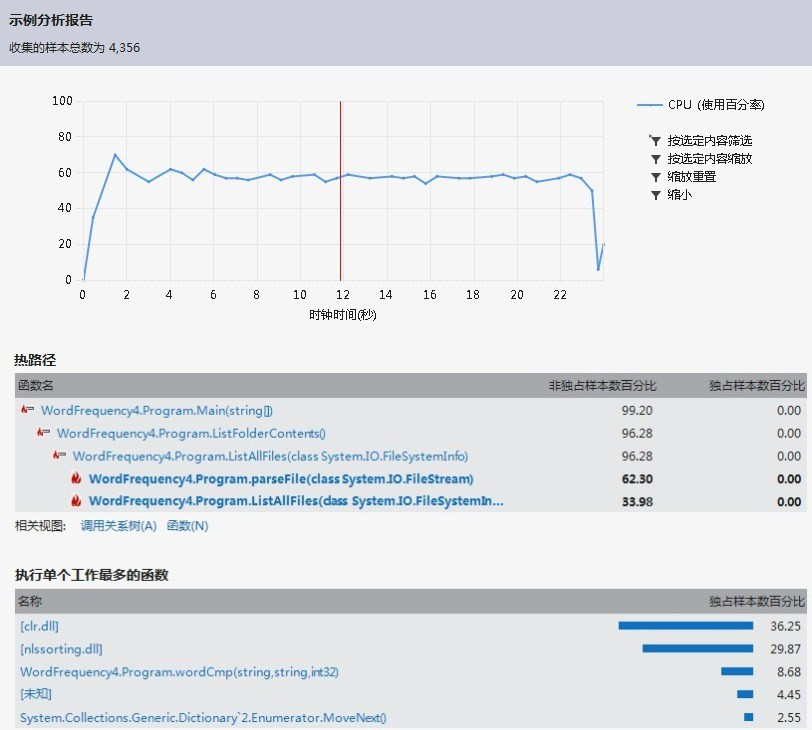
extend mode:

虽然性能瓶颈依然是parseFile(),但可以看到时间从原来的90多s变为20多s。
四、测试用例
1、路径为空文件夹
2、路径下有多个文件夹
3、不同格式的文件
4、空文本测试
5、简单模式下含有大小写不同的“相同单词”,如file, File, FILE
6、不合法单词测试,如数字开头文件、含有少于四个字符开头的字符串的文件
7、测试extend模式下后缀不同数字的情况:如window32, window98, window32a
8、测试特殊字符对分词的影响
9、字典序测试
10、测试较大规模文本文件,观察程序运行情况
五、收获与感想
对于这次作业说来甚是惭愧,作为班长这学期干的第一件事竟然就是带领大家不写作业。。。。。不过也确实是因为第一周形势所迫,所以还请老师见谅。
其实我一直蛮欣赏这种“目标驱动”的学习方式,暑期在实验室里实习的时候也是在毫无Python基础的情况下怒看一个星期Python然后完成了博士哥哥给我布置的数据处理任务。但是相对于拥有大把时间的暑假来说,这次作业的第一次deadline确实是太着急了,导致大部分同学一开始就采取了放弃的态度,只有极个别大神完成了作业。
在作业的提交时间调整之后,我决定利用中秋假期好好完成这次作业。为了提高效率,我决定采取看书与借鉴同学思路相结合的方式。于是我很快就掌握了这次项目的重点,并进入编程实现阶段。对于C#的陌生还是让我走了许多弯路,期间不得不厚着脸皮去问已经完成的同学的实现方法,确实有很多收获,比方说List和Regex。程序的优化可以说是一个意外的收获,完全是因为我无意中发现了Dictionary这种类型并且大胆的尝试了一番。
总的来说收获还是很多的,既加深了我对C#和visual studio的了解,也培养了我短时间内的突击能力,锻炼了我的意志品质。不过说实话。。。。。。我还是希望下次的作业能合理一点,尽量考虑绝大多数同学的水平。