关于autoencoder的内容简介可以参考这一篇博客,可以说写的是十分详细了https://sherlockliao.github.io/2017/06/24/vae/
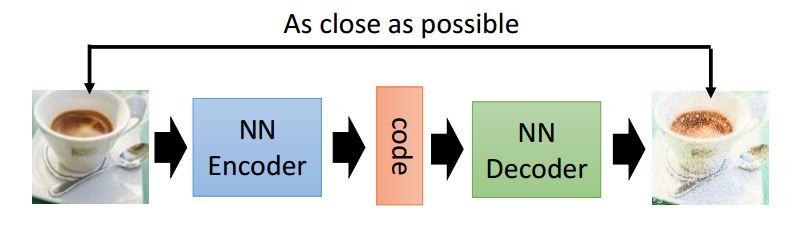
盗图一张,自动编码器讲述的是对于一副输入的图像,或者是其他的信号,经过一系列操作,比如卷积,或者linear变换,变换得到一个向量,这个向量就叫做对这个图像的编码,这个过程就叫做encoder,对于一个特定的编码,经过一系列反卷积或者是线性变换,得到一副图像,这个过程叫做decoder,即解码。
然而自动编码器有什么用,看到上面的博客所写
所以现在自动编码器主要应用有两个方面,第一是数据去噪,第二是进行可视化降维。然而自动编码器还有着一个功能就是生成数据。
然而现在还没有用过这方面的应用,在这里需要着重说明一点的是autoencoder并不是聚类,因为虽然对于每一副图像都没有对应的label,但是autoencoder的任务并不是对图像进行分类啊。
就事论事,下面来分析一下一个大神写的关于autoencoder的代码,这里先给出github链接
先奉上代码


1 # -*-coding: utf-8-*- 2 __author__ = 'SherlockLiao' 3 4 import torch 5 import torchvision 6 from torch import nn 7 from torch.autograd import Variable 8 from torch.utils.data import DataLoader 9 from torchvision import transforms 10 from torchvision.utils import save_image 11 from torchvision.datasets import MNIST 12 import os 13 14 if not os.path.exists('./dc_img'): 15 os.mkdir('./dc_img') 16 17 18 def to_img(x): # 将vector转换成矩阵 19 x = 0.5 * (x + 1) 20 x = x.clamp(0, 1) 21 x = x.view(x.size(0), 1, 28, 28) 22 return x 23 24 25 num_epochs = 100 26 batch_size = 128 27 learning_rate = 1e-3 28 29 img_transform = transforms.Compose([ 30 transforms.ToTensor(), 31 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) 32 ]) 33 34 dataset = MNIST('./data', transform=img_transform) 35 dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) 36 37 38 class autoencoder(nn.Module): 39 def __init__(self): 40 super(autoencoder, self).__init__() 41 self.encoder = nn.Sequential( 42 nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10 43 nn.ReLU(True), 44 nn.MaxPool2d(2, stride=2), # b, 16, 5, 5 45 nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3 46 nn.ReLU(True), 47 nn.MaxPool2d(2, stride=1) # b, 8, 2, 2 48 ) 49 self.decoder = nn.Sequential( 50 nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5 51 nn.ReLU(True), 52 nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15 53 nn.ReLU(True), 54 nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28 55 nn.Tanh() # 将输出值映射到-1~1之间 56 ) 57 58 def forward(self, x): 59 x = self.encoder(x) 60 x = self.decoder(x) 61 return x 62 63 64 model = autoencoder().cuda() 65 criterion = nn.MSELoss() 66 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, 67 weight_decay=1e-5) 68 69 for epoch in range(num_epochs): 70 for data in dataloader: 71 img, _ = data # img是一个b*channel*width*height的矩阵 72 img = Variable(img).cuda() 73 # ===================forward===================== 74 output = model(img) 75 a = img.data.cpu().numpy() 76 b = output.data.cpu().numpy() 77 loss = criterion(output, img) 78 # ===================backward==================== 79 optimizer.zero_grad() 80 loss.backward() 81 optimizer.step() 82 # ===================log======================== 83 print('epoch [{}/{}], loss:{:.4f}' 84 .format(epoch+1, num_epochs, loss.data[0])) 85 if epoch % 10 == 0: 86 pic = to_img(output.cpu().data) # 将decoder的输出保存成图像 87 save_image(pic, './dc_img/image_{}.png'.format(epoch)) 88 89 torch.save(model.state_dict(), './conv_autoencoder.pth')
可以说是写的相当清晰了,卷积,pooling,卷积,pooling,最后encoder输出的是一个向量,这个向量的尺寸是8*2*2,一共是32个元素,然后对这个8*2*2的元素进行反卷积操作,pytorch关于反卷积的操作的尺寸计算可以看这里
大概就这样开始训练,save_image是util中的一个函数,给定某一个batchsize的图像,将这个图像保存成8列,特定行的操作。
训练的loss如下
输出的图像如下,从左到右,从上往下,依次为epoch递增的情况










其实还是可以发现,随着epoch的增加,经过decoder生成的图像越来越接近真实图片