对于已经训练完成的caffemodel,对于单个的图片预测,用python接口来调用是一件非常方便的事情,下面就来讲述如何用python调用已经训练完成的caffemodel,以及prototxt,网上关于这一方面的教程已经是比较多的了,但是我想针对我做的过程发现的一些问题做一个总结
,先给出几个用python调用caffemodel的链接,链接1,链接2,链接3,主要是参考链接1的内容,整体代码如下,
1 #coding=utf-8 2 import sys 3 import numpy as np 4 import cv2 5 from glob import glob 6 from tqdm import tqdm 7 caffe_root = '/usr/local/caffe/' 8 sys.path.insert(0, caffe_root + 'python') 9 import caffe 10 import multiprocessing 11 12 model_file = '/home/ying/data2/shiyongjie/mpc/res50/acc/resnet_50_deploy.prototxt' # deploy文件 13 pretrained = '/home/ying/data2/shiyongjie/mpc/res50/acc/model_iter_280000.caffemodel' # 训练的caffemodel 14 image_file = '/home/ying/data2/shiyongjie/mpc/coal_data/0/output/0_ffff4083-a13a-4e62-9870-59cd70709f7c.JPEG' 15 mean_file = '/home/ying/data2/shiyongjie/mpc/coal_data/mean_train.npy' 16 net = caffe.Net(model_file, pretrained, caffe.TEST) #加载model和network 17 18 #图片预处理设置 19 transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式(1,3,28,28) 20 transformer.set_transpose('data', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28) 21 transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) #减去均值,前面训练模型时没有减均值,这儿就不用 22 transformer.set_raw_scale('data', 255) # 缩放到【0,255】之间 23 transformer.set_channel_swap('data', (2,1,0)) #交换通道,将图片由RGB变为BGR 24 25 print('#$%^&#@*!') 26 image_file_list = glob('/home/ying/data2/shiyongjie/mpc/coal_data/0/output/*JPEG') # 列出目录下的所有jpeg图片 27 image_file_list.sort() 28 image_file_list = image_file_list[:len(image_file_list)/2] # 速度预测非常慢,将list拆分 29 # pool = multiprocessing.Pool(processes = 4) 30 results = [] 31 for image_file in tqdm(image_file_list): # tqdm显示进度条 32 im = caffe.io.load_image(image_file) 33 net.blobs['data'].data[...] = transformer.preprocess('data', im) #执行上面设置的图片预处理操作,并将图片载入到blob中 34 out = net.forward() 35 top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1] 36 results.append(top_k[0]) # 将预测的结果保存到results中 37 # print(top_k[0]) 38 # for i in np.arange(top_k.size): 39 # print top_k[i] 40 acc0 = float(results.count(0))/float(len(image_file_list)) # 计算预测四类结果的概率 41 acc1 = float(results.count(1))/float(len(image_file_list)) 42 acc2 = float(results.count(2))/float(len(image_file_list)) 43 acc3 = float(results.count(3))/float(len(image_file_list)) 44 print(acc0, acc1, acc2, acc3)
这里其实有很多细节的问题,先给自己挖个坑,主要有,deploy文件与一般的train_val.prototxt文件有些许不同,看上面第三个链接,他们加载prototxt的是lenet.prototxt,去caffe/example/mnist/lenet.prototxt查看这个文件,如下

实际上左边是deploy的,右边是train_val的,可以看出左右的区别就是地一层,右边train和test都是data层,左边是input层,其余全都一样,所以deploy也是很有讲究的,mnist是在训练的时候就没有减去均值,测试的时候加载均值文件在python内部写,见上述代码
实际上,我测试用的deploy与mnist又有些许不同,如下
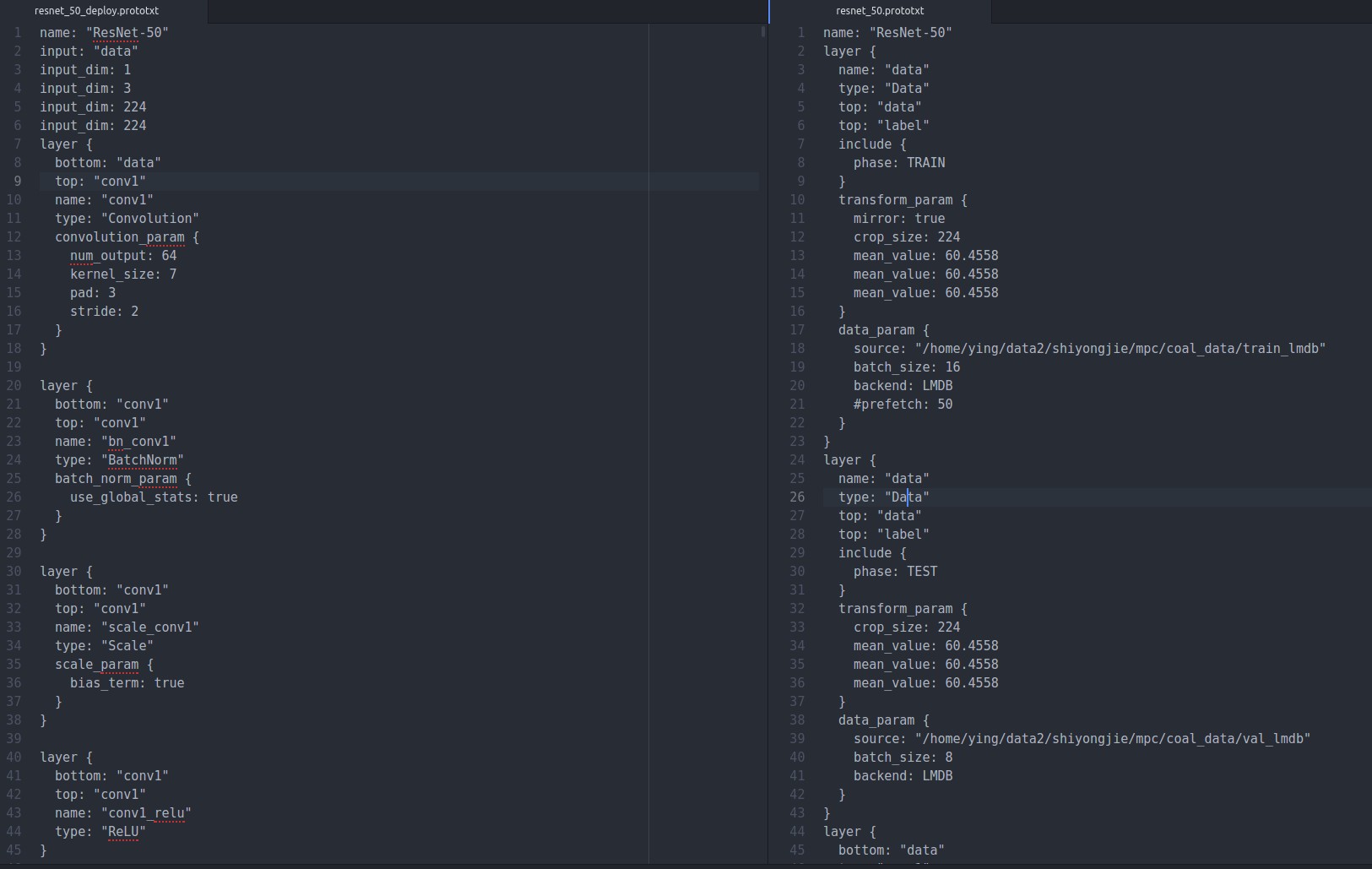
同时修改最后一行
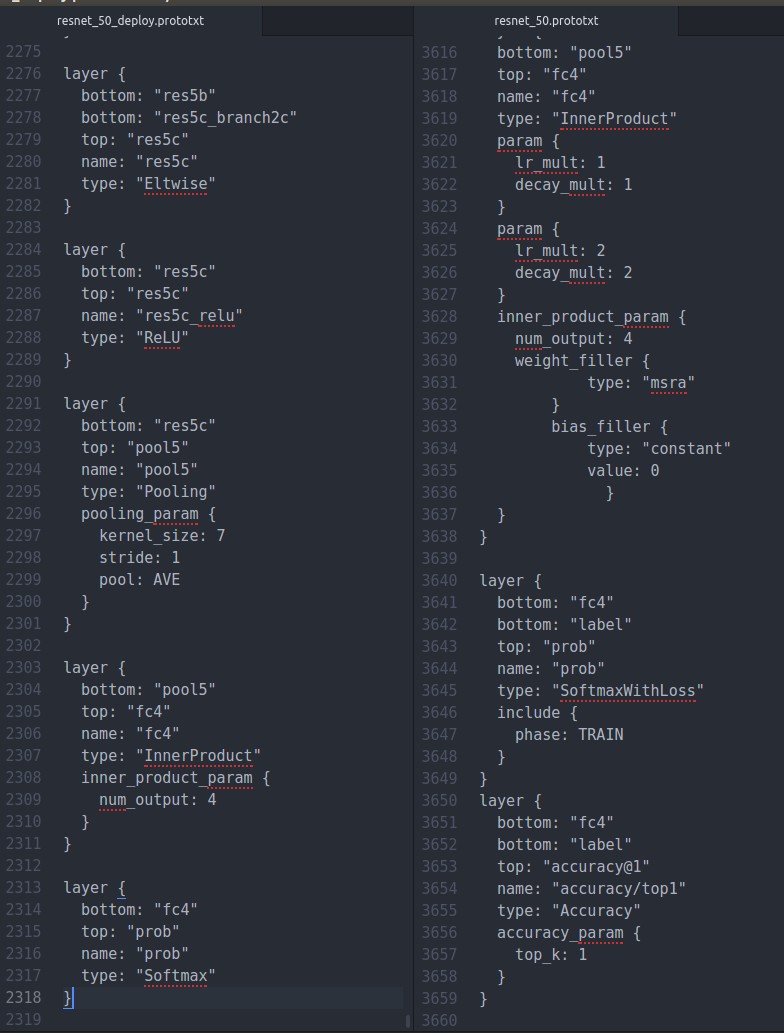
我用的resnet基本上lr以及权重初始化的参数都已经取消了,最后一个name用prob,测试的时候输出的是预测为每一类的概率,在python最后的输出net.blobs['prob']也能够看出,感觉是个字典,给自己挖个坑
可以看出,deploy文件与train_val文件是有很大的不同的,这种不同可能与平台无关,在python是这样,在c++也可能是这样
但是用python调用速度非常慢,这样说吧,5w张图片要6个小时,速度相当慢,我一个同学,用c++调用同样的caffemodel200张图片,0.4s,5w张图片100s就搞定