1、概述
该算法的理论基础是运用矩阵分解,把用户评分矩阵R分解为两个低维矩阵,然后用这两个低维矩阵去估计目标用户对项目的评分。
传统的协同过滤算法是利用用户的历史行为,来预测用户对目标用户的评分。需要在整个用户空间上去寻找最近邻居。随着电子商务的不断发展,用户数量和物品的数量都呈指数型增长,这样传统的算法就不能够满足推荐的实时需求。同时,传统的协同过滤算法只是考虑了用户的历史行为,而没有考虑物品之间的关系。针对这些问题,本文提出了一种融合隐语义模型的聚类协同过滤算法,区别于传统的基于项目聚类的协同过滤[5],本文算法没有直接在用户评分矩阵上进行聚类,而是先将评分矩阵进行分解,将得到的矩阵再进行聚类,这样聚类的维度降低,同时还考虑了物品类别信息,提高了推荐系统实时响应速度。
CF简单直接可解释性强,但隐语义模型能更好地挖掘用户和item关联中的隐藏因子。
2、SVD
隐语义模型涉及矩阵分解, 但是SVD的时间复杂度是O(m 3 ), 并且实际情况下,原矩阵大多数是缺失的,而我们对这些确实值默认给为0,SVD不太适合做推荐。
SVD是如何做推荐的呢?
A=UΣVT
U是“用户-主题”相似矩阵;奇异值矩阵的对角元素是每一个主题的强度;V是“电影-主题”相似矩阵
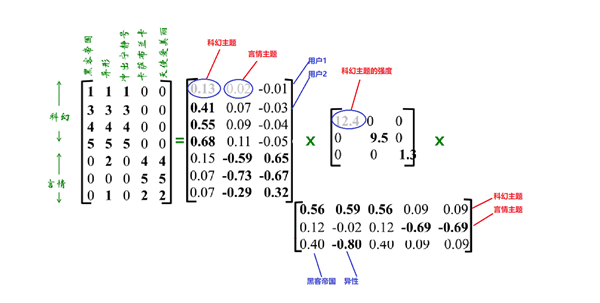
降维:
奇异值矩阵中,奇异值很小的值,说明主题的强度很小,可以忽略

如何衡量降维后的精确度?

保留多少奇异值?
奇异值的平方和一般在80%-90%
给用户推荐电影:
d,q是用户给电影的打分,V是“电影-主题”近似矩阵。
相乘得到的1×2维的矩阵的值代表用户对每个主题的喜欢程度。
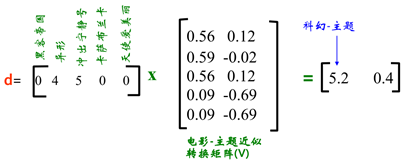

我们可以发现用户d, q都对相同主题的电影感兴趣,因此我们就可以互相推荐各自喜欢的电影。
3、矩阵分解
直接对原矩阵进行分解
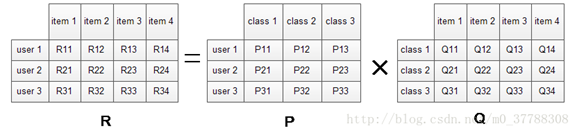
其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表
如何计算矩阵P和矩阵Q中的参数值。一般做法就是使用梯度下降法优化损失函数来求参数。
损失函数如下所示:
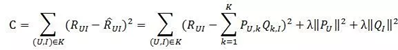
上式中的
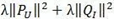
是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。
损失函数的优化使用随机梯度下降算法:
1)对两组未知数求偏导数
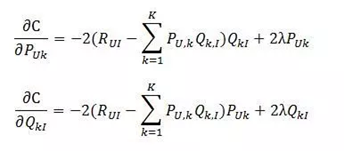
2)根据随机梯度下降法得到递推公式
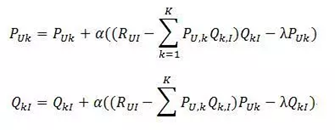
隐语义模型在实际使用中有一个困难,那就是它很难实现实时推荐。经典的隐语义模型每次训练时都需要扫描所有的用户行为记录,这样才能计算出用户对于 每个隐分类的喜爱程度矩阵P和每个物品与每个隐分类的匹配程度矩阵Q。而且隐语义模型的训练需要在用户行为记录上反复迭代才能获得比较好的性能,因此 LFM的每次训练都很耗时,一般在实际应用中只能每天训练一次,并且计算出所有用户的推荐结果。从而隐语义模型不能因为用户行为的变化实时地调整推荐结果 来满足用户最近的行为。
4、加bias的隐语义模型
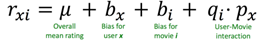
需要最小化
