算法概述
初始化权重,一般初始化是均分布,构造弱分类器,进行分类,然后给这个分类器一个权重。
改变数据集的权值分布,将分类错误的数据集分更大的权重,分类正确的数据分较小的权重,使用弱分类器进行分类,给这个训练好的弱分类器一个权重。
重复执行上述过程,预测时,根据训练好的多个弱分类器及其权值,决定要预测测试样本的标签。
算法原理
adaboost是一种加法模型,先讲下加法模型的损失函数:
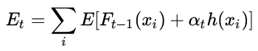
这里的Ft-1(xi)是前面训练好的提升分类器,h(xi)是新添加的若分类器,αt是弱分类器的权值,也叫学习的步长。E就是经过弱分类器h(xi)提升的强分类器在数据集上的错误率,即损失函数。
接着我们开始介绍adaboost算法:
假设经过m-1次迭代已经得到m-1个弱分类器的线性组合:
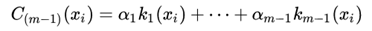
我们想通过下次迭代产生一个弱分类器,将其原分类器扩展为更好的提升分类器:
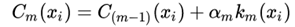
定义损失函数如下:
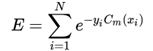
我们假定yi取-1和+1,那么当分类正确时:
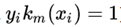
因此对损失函数改写为:
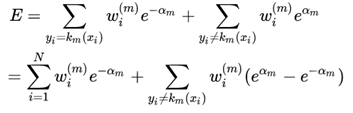
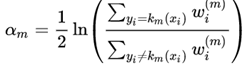
将损失函数对αm求导,并使等式为0,可以求解αm
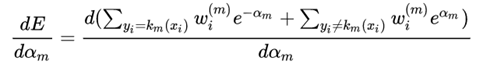
定义加权误差率:
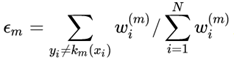
所以:
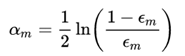
设训练数据集T={(x1,y1), (x2,y2)…(xN,yN)}
初始化训练数据的权值分布:
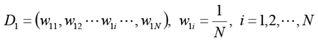
使用具有权值分布Dm的训练数据集学习,得到基本分类器
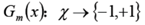
计算Gm(x)在训练数据集上的分类误差率
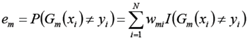
计算Gm(x)的系数(该分类器的权值)
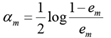
更新训练数据集的权值分布
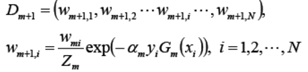
这里,Zm是规范化因子, 它的目的仅仅是使Dm+1成为一个概率分布
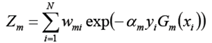
构建基本分类器的线性组合
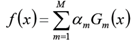
得到最终分类器
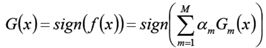
调参
from sklearn.ensemble import AdaBoostClassifier
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
1)弱学习器的数量由参数 n_estimators 来控制。 learning_rate 参数用来控制每个弱学习器对 最终的结果的贡献程度(其实应该就是控制每个弱学习器的权重修改速率,这里不太记得了,不确定)。
2) 弱学习器默认使用决策树。不同的弱学习器可以通过参数 base_estimator 来指定。 获取一个好的预测结果主要需要调整的参数是 n_estimators 和 base_estimator的复杂度 (例如:对于弱学习器为决策树的情况,树的深度 max_depth 或叶子节点的最小样本数 min_samples_leaf 等都是控制树的复杂度的参数)