目录
8.1 索引工作方式... 1
8.2 Oracle中的索引... 1
8.3 索引什么时候有用... 4
8.4 索引开销... 7
8.4.1 插入行怎样影响索引... 7
8.4.2 更新和删除行如何影响索引... 13
8.4.3 DML和索引... 18
8.5 联接... 18
8.5.1 B树索引的键压缩... 19
8.5.2 索引的跳跃搜索... 20
8.6 索引和约束... 25
8.7 反转键索引... 27
8.8 基于函数的索引... 29
8.9 位图索引... 32
8.10 位图联接索引... 35
8.11 小结... 36
正确地使用索引可以将缓慢而顽固的应用调整为响应迅速而产生率高的业务工具。遗憾的是,相反的情况也会发生。在应用中使用没有经过仔细考虑的不恰当的索引,可以将应用调整为对任何人都没有太多用处的行动缓慢的庞然大物。判断索引是否合适以及怎样在适当的时候恰当地建立它,是非常需要技巧的工作——这就是本章将要帮助用户获得的技巧。
- 什么是索引
- Oracle中的索引
- 了解索引价值和开销
- 索引多个列,键压缩、跳跃搜索、反转键索引
- 一些特别的索引
- 基于函数的索引
- 位图和位图连接索引
8.1 索引工作方式
当用户急于在本书中找到一些有关Oracle特定内容的信息时,可以使用2种方法。用户可以或多或少地按照次序翻阅各页,也许可以碰到正确的主题。或者,如果用户有一些常识的话,也可以使用本书中由印刷商提供的索引。当然,索引本身实际上不会告诉用户任何有关主题的内容,但是它可以为用户提供主题标题以及可以在书中的主体部分找到有关主题完整细节的页面引用。
采用这种方式,利用索引定位特定信息通常要比顺序翻阅各页快得多。
8.2 Oracle中的索引
存储在常规表中的行没有采用特定的次序存储,因此可以满足关系数据库理论的根本原则。当第一次插入行的时候,用户不会控制Oracle选择控制它们的物理位置。这意味着从表中获取特定的行需要Oracle顺序扫描所有可能的行,直到遇到正确的行为止。即使Oracle十分幸运,非常早地找到了与搜索条件相匹配的行,它也只能够在到达了表的逻辑末尾之后才可以停止搜索。这是因为尽管它找到了匹配行,但是这也不意味着这是唯一匹配。
这样的搜索信息方式称为全表搜索(full table scan)。
然而,如果Oracle知道在表的一部分(或者多个部分)上有索引,那么搜索就不必按照顺序,或者实际没有效率的方式进行。一个简单的示例帮助解释Oracle处理这种情况的方式。
考虑表8-1.
表8-1 简单示例表
|
EMPNO |
NAME |
DEPT |
SAL |
Etc… |
|
70 |
Bob |
10 |
450 |
… |
|
10 |
Frank |
10 |
550 |
… |
|
30 |
Ed |
30 |
575 |
… |
|
20 |
Adam |
20 |
345 |
… |
|
40 |
David |
10 |
550 |
… |
|
60 |
Graham |
30 |
625 |
… |
|
50 |
Charles |
20 |
330 |
… |
|
… |
… |
… |
… |
… |
在这里,我们可以看到存储在表中的雇员没有特定的次序。假如我们希望找到Frank的薪金细节。在没有索引的情况下,我们就必须搜索所有7行,然后进行处理,因为即使我们在第2行中找到了Frank,也不能够保证在表中只有唯一的Frank。只有当我们到达了表的高水平标记,通知我们不再有其它的行时,我们才能够停止搜索。
然而这时,我们能够使用如下的SQL语句:
Create index emp_name_idx On emp(name);
这将建立一个索引(特意命名为EMP_NAME_IDX,以便我们只通过查看它的名称,就可以知道这是一个构建在EMP表的NAME列上的索引),这意味着Oracle将会执行一次全表搜索,获取各个记录的名称字段,并将它们进行升序字母排序。这个排序会在第一个实例的内存执行,但是如果证实没有足够的空间可以容纳整个排序,它们也会交换到临时表空间中。Oracle还会将所获取的各个名字与它所在行的rowd进行关联(rowid是表中行的物理地址,可以告诉我们对象的来源,它所处的文件,以及文件中的特定数据块)。在处理之后,我们就会拥有新的索引段。如图8-1所示。
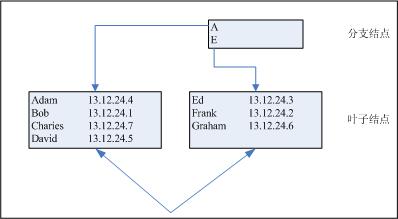
图8-1 索引段图示
出于清晰的考虑,我们已经简化了这个图示,并且确定了与索引有关的专门规则,也就是数据块不能够包含超过4个表项。在现实处理中,用户很明显应该在一个数据块中容纳更多的表项,但是这只是原理。数据块只能够容纳有限数量的表项。
这个索引就是B树索引,我们感兴趣的数据都位于基于索引的所谓叶子结点中。如果在索引中有多个叶子结点,Oracle就会构建指向它们的分支结点(Branch Nodes)。在各个叶子结点中,我们可以看到构建索引的关键数据(key data),以及源表中父行的rowid。
顺便提及,“B树索引”中的B不代表经常被认为的“二进制(binary)“,而是代表“平衡(balanced)”。这种情况下的平衡意味着Oracle可以保证用户在到达叶子结点表项之前,在树的一侧不会比另一侧需要穿越更多的索引层次。Oracle采用这种方式维护的结构,可以确保无论索引表项位于何处,都只需花费相同的I/O就可以获取它。
最后要注意,叶子的结点会在2个方向上彼此相连。搜索多行需要扫描多人叶子结点,它不需要不断访问索引结构的顶部。处理完一个叶子结点之后,它就能够直接移动到下一个结点。
使用这个索引搜索Frank意味着我们必须首先访问分支结点。我们将会从这个结点中发现为Frank提供的表项一定处于第二个叶子结点中(因为它的值比“E”大)。因此,我们必须执行第二次数据块读取,读取第二个叶子结点,在那里我们可以开始搜索它的内容。由于提供了一个字段(包含在索引定义中的字段),所以这个搜索会比搜索主表的表项快很多。当我们遇到作为叶子结点中第二个表项的Frank的时候,我们还不能够停止搜索(因为可能还有其它的Frank)。然而,只要我们遇到了“不是Frank”的表项,我们就可以知道(因为具有次序的排序)在索引中没有其它的Franks。所以,在发现实际只有一个Frank之后,我们就可以读取它的rowid,并且执行最后的数据块读取(在这个例子中,要从文件12中读取数据块24),从实际的表中获取他的薪金细节。
到目前为止,我们一共进行了三次数据块才获得了相关的表数据(一次用于分支节点,一次用于叶子结点,一次用于表的相关数据块)。与在上执行完全搜索可能需要进行的几十次读取相比,用户可以看到,使用索引获取数据通常要更快。
首先访问分支结点->读取叶子结点->表搜索表表项
试验:构建和使用索引
(1) 我们首先要确保SCOTT能够建立可以使用的并且能够访问从这个表进行选择的时候所涉及的开销:
创建PLAN_TABLE(c:\oracle\ora92\rdbms\admin\utlxpla.sql)
SQL> connect system/zyf; 已连接。 SQL> grant dba to scott; 授权成功。 SQL> connect scott/tiger; 已连接。 SQL> @?\rdbms\admin\utlxpla 表已创建。
(2) 现在,我们已经作为SCOTT进行了连接,我们要复制一个数据词典视图到我们自己的表中。DBA_OBJECTS非常适于使用,因为它非常大。在这个例子中,我们将会限制可能的所有者,以最小化我们处理不同版本的数据库时可能遇到的差异。
SQL> create table indextest as select * from dba_objects 2 where owner in ('OUTLN','PUBLIC','SCOTT','SYS','SYSTEM'); 表已创建。
(3) 如果我们打算能够访问选择语句的开销,我们就需要计算机新表上的统计数据。由于我们的新表中有大量的行,所以确保SQL*Plus只显示我们查询的开销,而不显示结果(庞大的页数)是个很好的想法。
SQL> analyze table indextest compute statistics; 表已分析。 SQL> set autotrace trace explain
(4) 现在,我们开始选择。我们要试着从我们的表中获取一行:
SQL> select owner,object_name from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=2 Bytes=58) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=2 Bytes=5 8)
(5) 我们现在在OBJECT_NAME列上建立一个索引,并且分析它使我们的查询开销有何不同:
SQL> create index indextest_objectname_idx 2 on indextest(object_name); 索引已创建。 SQL> select owner,object_name from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=2 Bytes=58) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=2 Card= 2 Bytes=58) 2 1 INDEX (RANGE SCAN) OF 'INDEXTEST_OBJECTNAME_IDX' (NON-UN IQUE) (Cost=1 Card=2)
工作原理
我们第一次从表中选取了一行,而且没有可以使用的索引,所以优化器要强制扫描整个的表。它在执行方案中展示如下:
TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=2 Bytes=5)
这里的开销是相对开销,所以它所显示的绝对值不是特别有意义。它只是Oracle解析查询必须要使用的CPU数量和I/O工作指标。关键是我们再次完成相同的查询时开销的变化,这一次要使用索引帮助搜索:
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=2 Card= 2 Bytes=58) 2 1 INDEX (RANGE SCAN) OF 'INDEXTEST_OBJECTNAME_IDX' (NON-UN IQUE) (Cost=1 Card=2)
这一次访问开销是“2”,它要比前一次小5倍。这个执行方案也表明了我们首先要搜索索引,以获取表中存储的整行的ROWID,然后再访问表本身。可以注意到,这次要通过ROWID访问表,而不是进行FULL(完全搜索)。换句话说,在访问了索引之后,我们现在就知道了我们要寻找记录的rowid,并且可以直接跳到表中的正确位置。
8.3 索引什么时候有用
如果索引这么好,为什么不在所有表的所有列上都使用索引,并且利用它进行操作呢?
在回答这个问题的使用需要考虑2点。首先,Oracle能够尽可能简洁而有效地对表进行值班表搜索。当优化器决定进行值班表搜索的时候,它会批量读取数据块,而不是一次读取一个。这称为多数据块读取,这意味着扫描50个数据块构成的表实际上只需在硬盘上读取几次就可以完成,而不用进行50次分别读取。Oracle一次可以读取数据块的精确数量不仅依赖于运行它的硬件和操作系统,也依赖于用户正在处理的数据库的块大小。通常,用户可以发现磁盘能够在一次读取中读取64K或者128K的数据,这意味着如果用户拥有8K数据块的数据库,那么一次就可以读取8个或者16个数据块。我们50个数据块的表可以在7次或者4次搜索中读取。
由于我们的索引需要3次读取,而全表搜索需要4次,索引会更有用一些。然而,如果表只有(假如)25个数据块,那么全表搜索可能只需2次多数据块读取就可以完成。这时,索引实际上会减慢数据获取的速度!
这就是我们在决定索引是否有用的时候需要考虑的第二点:
- 如果Oracle有能力在一次扫描中读取多个数据块,那么它就会将考虑使用索引(如果有)的阈值设置得相当高。
- 如果Oracle认为用户的查询将要选取记录的2%到5%,或者更多,那么它就会执行全表搜索,而不考虑是否有索引可用。
从Oracle的角度来看,这样做的原因是一个索引表项只会指向一个单独的表数据块,而且一次只能够读取一个数据块。所以,如果用户使用向用户指出了许多数据块的索引,那么用户就要执行大量的单独数据块读取。这就会有大量的I/O,大量的I/O意味着不好的性能。因此为什么不不囫囵吞枣,开始就对表数据块进行完全搜索,完全搜索可以使用多数据块读取,可以最小化所涉及的I/O。
因此,这2个因素都说明好的索引是选择性索引,它只会引用全部数量中很少比例的记录。
试验:发现索引合适有用
(1) 我们首先要在我们的SQL*Plus会话中关闭AUTOTRACE,以便发现我们前面建立的INDEXTEST表的一些基本信息:
SQL> set autotrace off; SQL> select owner,count(*) from indextest 2 group by owner; OWNER COUNT(*) ------------------------------ ---------- OUTLN 7 PUBLIC 11540 SCOTT 11 SYS 13526 SYSTEM 416
(2) 我们将要在我们表的OWNER列上建立新的索引:
SQL> create index indextest_owner_idx 2 on indextest(owner); 索引已创建。
(3) 我们现在要打开AUTOTRACE,以便我们能够看到优化器在解决接下来的查询是否会觉得我们的新索引有用:
SQL> set autotrace trace explain SQL> select owner,object_name from indextest 2 where owner='SYS'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=5100 Bytes=1 47900) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=5100 Byte s=147900) SQL> select owner,object_name from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=5100 Bytes=1 47900) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=5100 Byte s=147900)
(4) 到目前为止,都没有使用我们的索引,我们将会试用如下内容:
SQL> analyze table indextest compute statistics for columns owner; 表已分析。 SQL> select owner,object_name from indextest 2 where owner='SYS'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=13526 Bytes= 392254) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=13526 Byt es=392254) SQL> select owner,object_name from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=11 Bytes=319) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=2 Card= 11 Bytes=319) 2 1 INDEX (RANGE SCAN) OF 'INDEXTEST_OWNER_IDX' (NON-UNIQUE) (Cost=1 Card=11)
工作原理
我们的第一个查询向我们展示了各个所有者所拥有的对象数量。当用户试用这个查询的时候,用户将要获取确切数量将会根据用户正在使用的数据库版本而所有变化,但是我们只关系它们的相对大小,而不是它们的绝对值。我们获得的结果看起来如下所示:
OWNER COUNT(*) ------------------------------ ---------- OUTLN 7 PUBLIC 11540 SCOTT 11 SYS 13526 SYSTEM 416
现在,用户可能会认为我们搜索SCOTT的对象(他只有5000多个记录中的4个记录,小于整个记录数量的1%),就会用到OWNER列上的索引。与些同时,用户可能会认为我们会在选择SYS对象的时候使用全表搜索,毕竟,这些对象代表了一半以上的记录。事实上,在建立了适当的索引之后,我们可以发现无论用户选择了什么,优化器都会拒绝使用
遗憾的是,这可能是因为用户在考虑选择性的时候需要像优化器一样思考。对于优化器,我们只有5个可能的所有者,所以(基于我们早先为表计算的统计类型),无论我们选择什么,我们都好像在向优化器要求可用记录的20%。就如用户所见,20%没有足够的选择性可以劝服优化器使用可用索引。
为了让优化器意识到尽管只有5个可能的所有者,但是它们中间的一个拥有相对大量的行,而它们中的另一个只有少量的行,所以我们要在OWNER列上建立直方图(histogram)。这就是如下命令为我们做的:
SQL> analyze table indextest compute statistics for columns owner;
直方图是解释频率属性的工具,当优化器为我们表中的所有者使用直方图的时候,它就可以发现大多数记录由SYS所有,而只有少量记录由SCOTT所有。就是这种对我们数据不对称本质的新的了解,可以让Oracle更加智能化地决定是否使用列上的索引,这就是我们执行第二组查询时所看到的情况。这时,我们是否选取SYS或者SCOTT的记录就会带来是否使用索引的差异。
8.4 索引开销
我们的索引可以使搜索Frank的薪金细节更有效率,以上讨论表明具有高度选择性的索引总是比全表搜索更有效地从表中获取数据。
向表中插入新行还必须要向这个表的索引中插入相应的表项。这就有2次插入,而不是一次,这意味着由于索引的出现,会降低插入的速度。
另外,不仅插入会产生影响,而且更新和删除也必须要对索引进行更新。因此,一般认为索引会降低DML的性能(另一个很好的不到处放置不必要索引的原因)。
8.4.1 插入行怎样影响索引
我们假定已经向表中插入了另外的15个行。因此,表的NAME列上的索引最终会如图8-2所示。
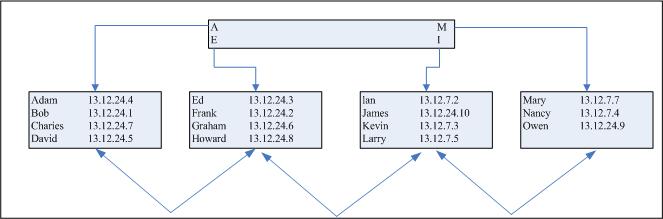
图8-2 NAME列上的索引
而且,我们还可以看出索引已经密集填充(我们的4个叶子节点中有3个拥有了每个数据块最大可能拥有的4个表项),因此会很有效率。但是,这只是因为我们已经认真地将雇员按照名称的字母升序进行了组织!如果我们没雇佣一个叫做Bill的人(就像现实生活中一样)会发生什么呢?
基本表中的表项没有问题:Bill的新记录会放置在有空余空间的表数据块中(它的记录中的精确位置无关紧要)。然而很明显,如果索引要保持意义或者功能,就只有一个可能的地方来插入Bill的索引表项,这就是数据块1。这里的问题是数据块1已经填满了它所允许的4个记录。
显而易见,我们必须要重新组织空间,以便可以将Bill的索引表项插入到适当的位置。因此就会出现这样的情况。我们要对第一个叶子结点进行分割,并且对它已有的表项重新分配,进而为新表项腾出空间。通常的规则是,Oracle会将平均50%的表项放到分割后的第一部分中,而将另外50%放到其它的部分中。要注意,精确的分割严重依赖于数据的性质,要由Oracle决定,我们根本不能对其进行控制。在我们的例子中,我们可能看到我们的索引会如图8-3所示。
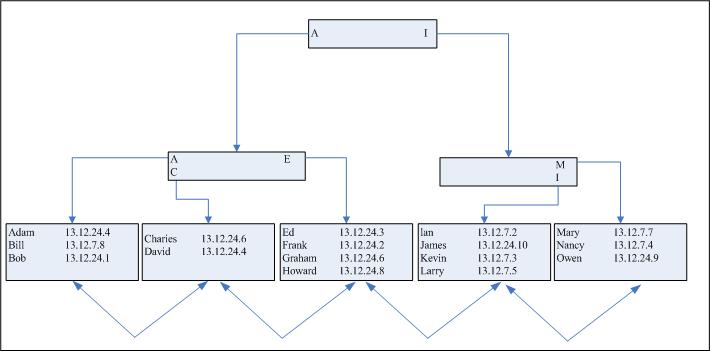
图8-3 插入Bill后的索引
要注意,“Adam-Bob-Charles-David”数据块如何被分割。“Adam-Bob”现在牌一个数据块中,而“Charles-David”处于另一个数据块中。这意味着在第一个数据块中已经有空间可以容纳Bill的新表项。
但是这个分割意味着分支数据已经拥有了超过它所容许的4个表项,所以我们实际上必须要获取另外的分支数据块,并且重新分配它的表项,以便让2个分支数据块来引用所有的叶子结点。对于这2个可能的分支结点,我们必须要在树的顶端建立一个新的单独分支结点,来指向其它分支。单独的分支节点称为索引的根结点。
因此,当向表中加入数据,需要在索引的已有表项之间插入新表项的时候,就要进行数据块的分割。对表进行这样的插入会迫使索引结构进行重新组织,而且可能会导致重新组织活动在树层次结构中不断“向上”传递,而增加索引的高度,降低性能。然而这应该说,Oracle为正在执行的DML自动重新平衡索引还是足够有效率的,很少会出现超过3层的高度。因此,索引高度不是在索引中出现插入活动时的主要开销。与此相反,开销主要是由于重新组织活动本身,以及获取额外的数据块(特别是,如果我们已经用完了已有区域中的所有数据块时,还要分配额外的区域),这将导致我们的插入要花很长时间来完成。
现在,如果用户进一步的插入能够利用叶子节点的空间,那么由于数据块分割所导致的叶子结点中的空间就一定会被重新使用。例如,在我们的例子中,如果我们现在插入雇员Daniel的记录,那么就会用去“Charles-David”结点中当前可用空余空间的50%。除非使用了这些新的表项(并且在适当的位置),否则由数据块分割所产生的空间就会成为被浪费的空间。在海量硬盘已经如此贴近我们的时代,这看起来可能是个小问题,但是用户必须要考虑到,有的时候Oracle需要基于索引扫描来解决查询。由于很多空叶子结点构成的索引与经过了良好压缩的索引相比,需要更多的I/O才可以完全扫描。这将导致查询获得更慢的性能。
我们有什么办法可以防止数据块分割呢?好,我们会进行尝试。在建立索引的时候可以(也应该规定)PCTFREE属性。在第一次建立索引的时候设置PCTFREE,也就可以在关闭叶子结点之前只对其进行部分填充,以用于将来的表项。这样就可以确保在每个叶子节点都有一些空余空间可以用于新的插入(在最初的索引建立之后),它可能要插入到已有的索引之间。
当然,让索引中有空余空间并不能够让我们更加有效地使用磁盘空间,它意味着我们对索引的扫描会比将PCTFREE设置为0的时候花费更长时间。然而,它也意味着本来要在嵌入索引之前需要进行数据块分割的插入能够不用经过特别的努力就可以找到一些合适的空间。因此,这样的插入就可以比那么必须要分割数据块的插入处理得更快。作为常见的情况,我们需要有效地在空间和速度之间进行权衡,在这个特殊的例子中,要对插入的速度与可能的索引扫描速度进行权衡。
遗憾的是,这里没有什么保障。也就是说,如果用户将PCTFREE设置为10%(就如表一样,这是默认值),那么一切都会运转正常。这会一直到用户使用新的一批插入填充到10%。这时,叶子结点就会被填满,所以向节点中进一步地单独插入仍然会导致数据块分割。
简而言之,如果插入需要嵌入到已有的索引表项之间,那么由大量新的插入在表上建立的索引将会不断降低他们的存储使用率以及性能效率。这种性能的逐渐降低能够得到改善(通过有规律的重新构建索引),但是这是一个开销很大的维护选项,它本身也会影响数据库的性能和可访问性。我们可以在建立索引的语句中使用PCTFREE设置,浪费一些叶子节点中的空间,来预防重新构建索引的需求。然而,这也不能够保证最终不会出现数据块分割和性能降低,而且这也意味着在我们开始之前,索引就有大量的自由空间。
试验:索引和插入
(1) 如果用户已经进行了早先的“试验”,那么用户的INDEXTEST表就可能已经在最初建立之后进行了修改。为了确保我们可以在统一层次的领域中操作,我们将要在这里重新建立表和索引。这一次我们将要注意确保尽可能满地填充所有叶子结点。
SQL> set autotrace off SQL> drop table indextest; 表已丢弃。 SQL> create table indextest as select * from dba_objects 2 where owner in('OUTLN','PUBLIC','SCOTT','SYS','SYSTEM'); 表已创建。 SQL> create index indextest_objname_idx 2 on indextest(object_name) 3 pctfree 0; 索引已创建。 SQL> analyze table indextest compute statistics; 表已分析。
(2) 在我们继续破坏我们的索引之前,我们来看看目前它的大小:
SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 113 100
(3) 现在,我们将会在附属表中插入一个必须要放置到第一个可用叶子结点(即使它已100%填满)中的新记录:
SQL> insert into indextest(owner,object_name) 2 values('AAAAAAAAAA','AAAAAAAAAAAAAAAAAAAAA'); 已创建 1 行。 SQL> commit; 提交完成。
(4) 现在,我们来看看我们的索引发生了什么。为了做到这一点,我们要重新设计我们的统计数据,来分析变化的结果:
SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 114 99
(5) 最后,我们要向附属表中增加一个能够放置到索引末尾的新记录,并且查看这个操作对我们索引统计的影响:
SQL> insert into indextest(owner,object_name) 2 values('ZZZZZ','_ZZZZZZZZZZZ'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 115 98
(6) 现在,我们来重复以上步骤,只是这一次我们将要重新建立索引,设置更合适的PCTFREE值,在每个叶子结点中都预留一些空余空间:
SQL> alter index indextest_objname_idx rebuild pctfree 10; 索引已更改。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 126 90
(7) 我们现在来为以前相同的插入重新分析统计结果:
SQL> insert into indextest(owner,object_name) 2 values('AAAAAAAAAA','AAAAAAAAAAAAAAAAAAAAA'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 126 90 SQL> insert into indextest(owner,object_name) 2 values('ZZZZZ','_ZZZZZZZZZZZ'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_blks,pct_used 2 from index_stats; NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 126 90
工作原理
第一次我们进行插入的时候,叶子已经完全填满。所以,当我们向表中第一次插入的时候,我们就必须进行数据块分割腾出空间,以便在索引的开始放置索引表项。我们可以比较2个数字:LF_BLKS(叶子块)和PCT_USED来查看所发生的情况:
在插入之前,INDEX_STATS视图如下所示:
NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 113 100
这就是说,我们有13个叶子结点,使用了100%的索引。(我们曾经说过,叶子结点都应该100%填满,如果在表中没有足够的行去填充最后的节点,这里不一定是100%)
在插入之后,会显示相同的报告:
NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 114 99
所以,我们已经明显地获得了新的叶子结点(因为第一个数据块必须要分割成2个,来为新的表项腾出空间)。另外,由于最初分割的结点,以及接受了一些旧有节点表项的新结点都没有完全填满,所以PCT_USED会明显下降。现在不只是在索引的末尾,在索引的开始也有了一些空余空间。
接下来,使用等于10的PCTFREE参数重新构建索引,INDEX_STATS视图会向我们显示如下内容:
NAME HEIGHT LF_BLKS PCT_USED ------------------------------ ---------- ---------- ---------- INDEXTEST_OBJNAME_IDX 2 126 90
所以,尽管进行了全新构建,然而因为每个结点目前都有10%空余空间,所以这个索引还是比最初的索引多占用了2个数据块。而且,用户可能希望PCT_USED列向我们显示100,而不是90,但是只有行的数量刚好将最后的叶子结点填充到90%的标准时,才会出现这样的情况。
8.4.2 更新和删除行如何影响索引
更新和删除会怎么样呢?它们会产生与插入相同的空间效果么?
假如Bob最近刚刚提升到执行经理的级别,他希望今后被称为Robert。这样就可以毫无问题地使用如下语句对表进行更新,来反映这种改变:
alter table emp set name=’Robert’ where name=’Bob’.
但是,对索引进行相似的改变会产生什么情况呢?我们的第一个叶子结点最终将会如图8-4所示。

图8-4 更新后的第一个叶子结点
可以预料到,在显示用于“A-B”的叶子结点中显然不能够接受属于“R”的表项。
所以,对表进行更新不能够只是对索引进行更新,因为叶子结点表项最终可能会出现位置错误。与此相反,我们必须要将最初的叶子表项标记为死亡,在位置恰当的叶子结点中插入全新的表项。当然,如果新的插入需要空间,它可能会最终导致数据块分割。在我们简单的救命中,我们是幸运的。我们最终会得到如下结果,见图8-5.
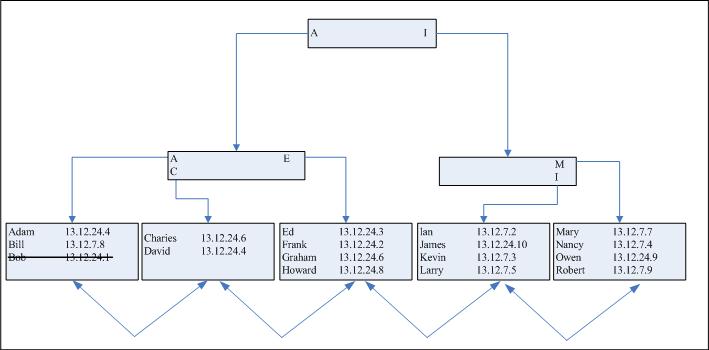
图8-5 索引调整后的结果
所以在这个例子中,由于在第5个叶子结点中有空间可以容纳“Robert”的新表项,所以我们可以设法避免数据块分割。然而,尽管我们的第一个叶子结点使用了75%的空间,但是由于有一个表项已经被标注为已删除叶子行,所以现在只有50%的有效表项。用户可能会怀疑为什么要采用标注表项的方式来进行删除,是不是实际删除它们。这只是因为执行实际的删除要花费更多的时间。我们要尽量减少DML性能的影响,而不是加重它。
从基表中删除行也会采用相似的方法。正在被删除的行的索引只是被标记为删除,但是在叶子结点中所战胜的空间不会释放。
因此,在表项上进行的更新和删除会进一步增加我们索引的麻烦,因为我们会留下废弃的表项,战胜叶子结点的空间。当然,我们在表上执行的其它DML也可以利用当前由我们的废弃表项所占据的空间。例如,如果我们要为Brian或者Barry插入新记录,那么它们的索引表项就可以嵌入到我们的第一个叶子结点中。它们就可以重用以前由Bob的表项所占用的空间。
当叶子结点中的所有表项都被废弃之后,Oracle就要面临删除废弃表项的问题。在进行这个操作之前,数据块仍然会被认为具有位置意义。例如,如果我们不仅删除了Bob的记录,而且删除了Bill的记录,而仍然将“Adam”作为合法表项留在第一个结点中,那么这个结点就只能能够接受对这个结点有意义的新表项。“Bruce”可以在这里找到位置,“Adriana”也可以,但是即使结点的大部分都是(有效的)空余空间,“William”表项也不能够放在这里。然而,如果我们将这个结点中的所有表项都标记为删除,那么很明显这个数据块就没有了位置意义。只要我们清除了所有废弃表项,“William”表项就可以完全利用它。
用户还可以发现已删除表项会在另一种条件下被清除。例如,如果新进的插入活动正在包含已删除表项(可以被活动重新使用的表项)的数据块中进行,Oracle就有机会从数据块中清除所有已删除表项。这就是Oracle在其它的数据管理工作中避免索引维护活动的方法,它可以避免对数据块进行不必要的重要访问。
这与表的操作完全不同,无论表中插入的数据值是什么,只要数据块已经清除到了为表所设置的PCTUSED以下,那么表的数据块中的空间可以被任何新的插入所重用。而就如我们早先提到的,索引数据块被新的表项重用之前,需要完全清空,也就是说“William”暗指索引的PCTUSED隐式为0——(不能设置为0以外的其它数值)。试图在索引建立的规定用户自己的PCTUSED将会产生一个错误。
试验:使用索引进行更新和删除
(1) 就如以前,我们要重新建立INDEXTEST表,以确保我们可以从头开始。然后,我们要重新计算OBJECT_NAME索引上的统计数据,执行简单的更新以便查看效果:
SQL> drop table INDEXTEST; 表已丢弃。 SQL> create table indextest as select * from dba_objects 2 where owner in('OUTLN','PUBLIC','SCOTT','SYS','SYSTEM'); 表已创建。 SQL> create index indextest_objname_idx 2 on indextest(object_name) pctfree 10; 索引已创建。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats; NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25504 0 90 SQL> update indextest set object_name='DBA_INDEXES2' where object_name='DBA_INDEXES'; 已更新2行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats; NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25506 2 90
(2) 现在,我们要执行一个删除操作(再次计算新的统计数据来查看效果):
SQL> delete from indextest where object_name like 'ALL_T%'; 已删除36行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25506 38 90
(3) 现在,我们要在表中执行新的插入,查看其对索引的影响:
SQL> insert into indextest(owner,object_name) 2 values('ZZZZ','ZZZ_INSERT'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats; NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25507 38 90
再进行最后一两个插入,查看是否已经发生了变化:
SQL> insert into indextest(owner,object_name) 2 values('ZZZZ','ALL_TESTINSERT'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats; NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25472 2 89 SQL> insert into indextest(owner,object_name) 2 values('ZZZZ','DBA_INDEX'); 已创建 1 行。 SQL> commit; 提交完成。 SQL> analyze index indextest_objname_idx validate structure; 索引已分析 SQL> select name,height,lf_rows,del_lf_rows,pct_used 2 from index_stats; NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25471 0 89
工作原理
我们在INDEX_STATS表上更新后进行的第一个SELECT会产生如下结果:
SQL> update indextest set object_name='DBA_INDEXES2' where object_name='DBA_INDEXES'; 已更新2行。 NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25506 2 90 DELETE后产生的结果 SQL> delete from indextest where object_name like 'ALL_T%'; 已删除36行。 NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25506 38 90
可以注意到,索引中的叶子行的整体数量根本没有改变。这表明了从表中进行的删除不会实际删除我们索引中的相应表项。另一方面,已经删除叶子行的数量已经上升到了38。其中36行是这次标记的废弃表项,还有2个来自于前一次更新的结果。
进行“ZZZ”插入
SQL> insert into indextest(owner,object_name) 2 values('ZZZZ','ZZZ_INSERT'); 已创建 1 行。 NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25507 38 90
插入之后生成的INDEX_STATS报告向我们展示在索引中仍然有38个已删除叶子行。很明显,插入没有重用由我们早先的DML活动产生的空间。
令人吃惊的是,我们所插入的第一个新ALL_TESTINSERT对象就会将被以前指删除标记为已删除叶子行的36个插槽清除出索引:
SQL> insert into indextest(owner,object_name) 2 values('ZZZZ','ALL_TESTINSERT'); 已创建 1 行。 NAME HEIGHT LF_ROWS DEL_LF_ROWS PCT_USED ------------------------------ ---------- ---------- ----------- ---------- INDEXTEST_OBJNAME_IDX 2 25472 2 89
通过指出我们想要重新使用旧有的ALL_T的插槽,Oracle就有机会整理完整的数据块。因此,所有36个已删除表项都会被清除,这就减少了索引内的叶子行的整体数量,将我们已删除叶子行的数量降低为2。
然而,通常还是要提出敬告。这种有效的回收只是因为我们的新插入能够利用空间才会发生。因为我们第一个插入的位置不适合完成这项工作,所以它就不能进行回收,如果随后的插入仍具有相同的性质,或者两者之前位置不对,那么已删除的表项就还会阻碍我们的索引。
8.4.3 DML和索引
用户(或者,通常是DBA)可以不必等待进一步的DML有效利用由以前的DML生成的空间,可以选择重新构建索引。这时,所有废弃的表项都会被删除,所有数据块都会被有效地重新压缩(有效地反转数据块分割的影响)。然而,索引重构是开销相当大的做法(甚至对新的8i和9i的“在线重构”特性也是如此),需要相当多的自由磁盘空间,而且表锁定的程度也会导致不便,大量的I/O也会影响同时使用数据库的所有用户。而且只要重构完成,整个数据块分割和建立废弃表项的过程又会再次开始,所以这是一个艰难的斗争。
对于不知道是否要在执行了DML的表的特定列上放置索引的开发者来讲,重要的是要权衡索引的开销(空间使用、空间浪费、附加I/O,因为表和索引段需要维护而降低DML性能)与可能的收益(在选择性相当高的时候更快地获取数据)。在权衡选择因素的时候,用户还应该考虑是否要建立索引,什么时候需要索引,以及什么时候不再需要它们而将其删除。例如,有一个需要产生月末报告的会计应用,那么建立索引毫无疑问可以加速报告的生成。然而,由于只在月末生成这些报告,那么让这些索引永久存在,而降低一个月剩余30天的DML活动速度明智么?用户应该经常留意在应用内是否有机会根据用户需要动态建立索引,而不是让它们永久降低DML性能。
8.5 联接
目前,用户应该已经明白使用索引不一定就是好主意!它们具有开发者经常会忘记或者忽略的很高的开销,随意建立索引确实是个坏主意。由于这些原因,最好是最小化需要在表上建立的索引数量。
用户可以用来获得特定目标的主要工具之一就是使用联接B树(concatenated B-Tree)索引。这是可以在一组列上构建,而不是在一个列上构建的索引。
作为联接的简单示例(尽管有些不切实际),我们可以使用如下命令:
Create index emp_name_no_idx On emp(name,empno) Pctfree 25;
我们的叶子结点将会如图8-6所示。

图8-6 联接B树索引
当用户查看以这方式构建的索引时,可以明显地发现对EMPNO为30的雇员进行搜索根本不能有效利用索引。雇员编号散布在索引中,没有特定的次序,这是因为NAME字段具有排序的优先权。换句话说,联接索引中的字段次序相当重要,会极大地影响Oracle优化器随后利用(或者不用)索引的方式。
在这个例子中,搜索特定雇员编号可能会实际利用索引,我们必须扫描整个索引,但是这样仍然可能会快于扫描整个表。如果索引是几个大型列的联接,那么它们就会代表较高比例的整行,优化器选择遍历索引的机会就会相当小。
Oracle 9i会更智能化一些,它有能力在索引中时进行“跳跃搜索”,而不是从头到尾搜索所有的内容。我们将会在随后讨论这一点。
如下索引中会包含与以前相同的信息,但是会采用不同的次序:
Create index emp_name_no_idx On emp(empno, name) Pctfree 25;
8.5.1 B树索引的键压缩
键压缩是Oracle 8i的新特性,工作方式如下所示。假如一个表包含了公园和公共场所的细节,各个地方需要实现的风景特点,以及这些工作的细节。
例如:
Britten Pack,Rose Bed 1,Prune Britten Pack,Rose Bed 1,Mulch Britten Pack,Rose Bed 1,Spray Britten Pack,Shrub Bed 1,Mulch Britten Pack,Shrub Bed 1,Weed Britten Pack,Shrub Bed 1,Hoe
……等。对于传统的B树索引,叶子结点应该包含如下所示的表项:
BRITPK,RB1,PRUNE
BRITPK,RB1,MULCH
BRITPK,RB1,SPRAY
BRITPK,SB1,MULCH
然而,如果要使用新的压缩特性建立索引,我们就可以使用如下命令:
Create index landscp_job_idx On landscp(site,feature,job) Compression 2;
那么,叶子结点表项的构成就会相当不同。前2列(由于COMPRESSION 2子句)会被放置到结点的特殊“前缀”区域,而剩下的列会作为主叶子结点表项保留,如下所示:
Prefix 0:BRITPK,RB1 3 Prefix 1:BRITPK,RB1 3 PRUNE 0 MULCH 0 SPRAY 0 MULCH 1 WEED 1 HOE 1
就如用户所见,非选择性数据以及链接各个前缀的表项引用数量(在这个例子中,各个前缀都有三个表项)只在结点的前缀区域中列出了一次。然后,在叶子结点的“主体”中,各个结点都与它的父前缀进行了链接。
这里的关键优势是重复性(换句话说,非选择性,很少改变的)键值可以只在叶子结点中存储一次(在前缀区域中),而不用为每个表项存储一次。这样可以潜在节省大量的空间,用户可以保存比以前更多的叶子表项。
首先,索引越小就意味着优化器越有可能利用它们,甚至用户代码没有提示也会如此;其次,当进行读取的时候,读取索引所需的I/O也会减少,所以索引读取的性能也会提高,由于服务器为了利用索引,必须要在内在中对其进行解压缩,所以CPU的使用也会提高。
另外,用户应该意识到压缩不是只能用于联接索引。只要用户在选择性相对较低的数据上具有非唯一索引(即使在单独的字段上),就可以考虑使用压缩的好处。
对于唯一索引,单独列的压缩就毫无意义:整个索引都会构建在前缀区域中,根本不会有其它的东西留存叶子结点中。
8.5.2 索引的跳跃搜索
索引的跳跃搜索(Skip scanning)是随Oracle 9i引入的新特性。它的出现意味着用户不需要再像以前那样担心联接索引的字段次序,即使用户查询正在选取的字段不是索引的起始列,优化器也可以智能化地搜索索引。
假如我们拥有LANGUAGE和COUNTRY这2个字段的联接索引。可以注意到,语言要比可能的国家少(例如,在几十个国家都要说英语)。因此,可以使用最小选择性的列作为起始键来建立索引,我们可能会拥有具有如下排序的索引,见图8-7。
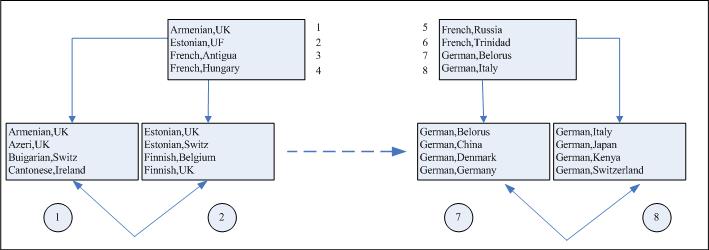
图8-7 跳跃搜索示例图
我们考虑如果使用了如下的语句时,将会怎样在索引中搜索:
Select * from table where country=’Swizerland’
例如,我们知道分支结点的第1个结点起始于“Armenian,UK”,第2个结点起始于“Estonian,UK”。“Armenian”和“Estonian”之间包含“Switzerland”的可能性(“Bulgarian,Switzerland”)。它可能会包含用于Switzerland的表项。
采用相同的方式跳过第3、4个结点。
然而,结点5位于“French,Russia”和“French,Trinidad”之间,能够包含用于Switzerland的表项。所以我们必须读取结点5。
这里得到的结果是,在8个结点的索引中,我们只需在磁盘上读取其中的5个(结点1、2、5、6和8),但是可以完全地跳过其中的3个(结点3、4、和7)。这节省了与这个索引相关联的一半I/O。
因此,从有关B树索引的联接、压缩及跳跃搜索的讨论中所得到的结论是,联接可以通过减少不必要的单键索引得到很大的益处,但是列的次序会导致差异。同时,索引的起始列应该对应于应用最常用于它的查询谓词的列。
试验:索引的联接、压缩和跳跃搜索
(1) 首先要确保我们的测试表最新建立,脱离以前的示例所产生的修改的影响。
SQL> drop table indextest; 表已丢弃。 SQL> create table indextest as select * from dba_objects 2 where owner in('OUTLN','PUBLIC','SCOTT','SYS','SYSTEM'); 表已创建。
(2) 我们首先需要找到我们的测试表的一些内容(要记住,用户的结果会根据用户正在运行的数据库版本有所变化):
SQL> select distinct owner from indextest group by owner; OWNER ------------------------------ OUTLN PUBLIC SCOTT SYS SYSTEM SQL> select count(object_name) from indextest order by object_name; COUNT(OBJECT_NAME) ------------------ 25504
(3) 现在,我们要建立联接索引,并且分析优化器怎样(是否)利用它。用户可能还记得,在早先的试验中,因为数据的基数太低,所以让优化器使用OWNER列上的索引根本不可行,我们要计算列上的直方图来进行帮助:
SQL> create index indxtest_owner_object_name_idx on indextest(owner,object_name); 索引已创建。 SQL> set autotrace trace explain; SQL> analyze table indextest compute statistics; 表已分析。 SQL> analyze table indextest compute statistics for columns owner; 表已分析。 SQL> select owner,object_type from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=15 Bytes=195) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=3 Card= 15 Bytes=195) 2 1 INDEX (RANGE SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' ( NON-UNIQUE) (Cost=2 Card=15) SQL> select owner,object_type from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=7 Card=2 Bytes=74) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=7 Card= 2 Bytes=74) 2 1 INDEX (SKIP SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' (N ON-UNIQUE) (Cost=6 Card=1)
(4) 现在,我们来重新建立索引,这一次将列的次序倒转,并且看看它是否会对我们的查询产生影响:
SQL> drop index indxtest_owner_object_name_idx; 索引已丢弃。 SQL> create index indxtest_owner_object_name_idx on indextest(object_name,owner); 索引已创建。 SQL> select owner,object_type from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=15 Bytes=195 ) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=15 Bytes= 195) SQL> select owner,object_type from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=2 Bytes=74) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=3 Card= 2 Bytes=74) 2 1 INDEX (RANGE SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' ( NON-UNIQUE) (Cost=2 Card=2)
(5) 这一次,我们将要分析当我们使用各种方式压缩索引的时候发生什么情况。我们将要首先获取我们当前索引的物理大小,以便可以将其与我们已经压缩的索引进行比较:
SQL> set autotrace off SQL> analyze index indxtest_owner_object_name_idx validate structure; 索引已分析 SQL> select name,lf_blks,pct_used from index_stats; NAME LF_BLKS PCT_USED ------------------------------ ---------- ---------- INDXTEST_OWNER_OBJECT_NAME_IDX 146 89 SQL> alter index indxtest_owner_object_name_idx rebuild compress 1; 索引已更改。 SQL> analyze index indxtest_owner_object_name_idx validate structure; 索引已分析 SQL> select name,lf_blks,pct_used from index_stats; NAME LF_BLKS PCT_USED ------------------------------ ---------- ---------- INDXTEST_OWNER_OBJECT_NAME_IDX 123 89
(6) 现在,我们要分析新的压缩程度是否会影响优化器对索引的使用:
SQL> set autotrace trace explain SQL> select owner,object_type from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=24 Card=15 Bytes=195 ) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=24 Card=15 Bytes= 195) SQL> select owner,object_type from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=2 Bytes=74) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=3 Card= 2 Bytes=74) 2 1 INDEX (RANGE SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' ( NON-UNIQUE) (Cost=2 Card=2)
(7) 因为发现使用OBJECT_NAME作为起始列的索引不能够很好地压缩,也不能够对我们的查询起很大的帮助,所以我们要删除索引,并且使用OWNER作为起始列重新建立它,另外,我们将会压缩它,并且在查询中使用它之前检查它的重要统计数据:
SQL> drop index indxtest_owner_object_name_idx; 索引已丢弃。 SQL> create index indxtest_owner_object_name_idx on indextest(owner,object_name) compress 1; 索引已创建。 SQL> set autotrace off SQL> select name,lf_blks,pct_used from index_stats; 未选定行 SQL> analyze index indxtest_owner_object_name_idx validate structure; 索引已分析 SQL> select name,lf_blks,pct_used from index_stats; NAME LF_BLKS PCT_USED ------------------------------ ---------- ---------- INDXTEST_OWNER_OBJECT_NAME_IDX 127 89 SQL> set autotrace trace explain SQL> select owner,object_type from indextest 2 where owner='SCOTT'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=15 Bytes=195) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=3 Card= 15 Bytes=195) 2 1 INDEX (RANGE SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' ( NON-UNIQUE) (Cost=2 Card=15) SQL> select owner,object_type from indextest 2 where object_name='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=7 Card=2 Bytes=74) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=7 Card= 2 Bytes=74) 2 1 INDEX (SKIP SCAN) OF 'INDXTEST_OWNER_OBJECT_NAME_IDX' (N ON-UNIQUE) (Cost=6 Card=1)
工作原理
压缩的存在不足以劝说优化器使用采用了新方法的索引,但是对SCOTT对象的选择所展示的开销为3,这表明在这种情况下压缩不会实际降低我们的性能。
8.6 索引和约束
Oracle在建立(或者修改)表的时候,可能会(有的时候不合时宜)声明特定的约束,这会隐式导致Oracle在约束列上建立索引。主要问题出在唯一和主键约束。考虑如下代码:
create table inventory( partno number(4) constraint invent_partno_pk primary key, partdesc varchar2(35) constraint invent_partdesc_uq unique );
无论用户是否喜欢,这些代码都将为这个表建立2个索引,每个列上建立一个。这些索引的名称将会与约束的名称相同,这也是用户需要正确命名约束的一个原因。如果用户没有命名约束,那么Oracle就会使用非常不直观的名称,例如SYS_C00013。
当我们考虑禁用约束时(处于某种原因)用于强制约束的索引所出现的变化,问题就会显现。规则是,如果使用唯一索引强制约束,那么当禁用约束的时候,就不会进行任何警告而立即删除索引。然而,如果使用非唯一索引进行强制,那么无论用户对约束进行何种操作,索引都会得到保留。
在用户考虑重新启用约束会导致以前所删除的索引被重新建立以前,这好像并不是一个特别的问题。就如我们以前提到的,建立索引是一个开销非常大的过程,因为它会涉及大量的I/O,以及相当严重的表锁定,这会在初始构建索引期间阻止在表上进行DML操作。
幸运的是,还可以控制约束,使用不会消失的非唯一索引对其进行强制。这个技巧要利用Oracle8.0中引入的可延迟(deferrable)约束的思想。为了完成这个工作,我们要重写以前的CREATE TABLE语句,如下所示:
create table inventory( partno number(4) constraint partno_pk primary key deferrable initially immediate, partdesc varchar2(35) constraint partdesc_uq unique deferrable initially immediate );
延迟约束是直到事务处理进行提交的时候才会实际进行检查的约束。因此,在那个时刻以前,Oracle必须允许执行可能会违背为表设计的约束的DML。也就是说,用户可以批量载入可能违背主键规则的10,000个数据行,而且直到用户提交插入,我们并不允许将这些记录放入表中(这时,就会拒绝这些行,将其清除出表,以确保只是暂时违背约束)。如果要在表中放置违规的记录,我们就不能够在后台使用唯一索引,因为表如果意识到我们的唯一性已经被违反,就会拒绝所插入的记录。换句话说,延迟的主键和唯一性约束必须使用非唯一索引来强制执行。
顺便提及,用户可能会认为使用非唯一索引强制主键或者唯一性约束需要付出一些代价。当执行新的DML的时候,Oracle一定要扫描更多的索引才能够进行唯一性检查么?事实上,这里没有任何的性能影响,这是因为优化器已经足够聪明,可以知道如果在表的层次将列声明为具有唯一性(或者主键),那么索引的目录就一定是唯一的。毕竟,即使是在最后检查延迟约束(在提交的时候),也绝对不可能向表中插入非唯一的行(以及索引),索引也一定是唯一的。因此,优化器可以将索引看作是唯一的,来从列中搜索数据,性能会像第一次就将列声明为唯一的情况一样好。
当用户开始声明主键或者唯一性约束的时候,还有一个最后要考虑的问题。由于用户无论如何都会建立索引,所以用户需要考虑是否有机会将它们与其它列上建立的索引结合。这里需要注意的是,如果在为表实际声明约束的时候,能够用来强制约束的索引已经存在,那么Oracle就不会建立另外的索引(它会占用额外的空间,要求开销很大的构建进程),而是会简单使用已有的索引。
在构思这样的处理时需要考虑的唯一规则就是,用户自己的索引必须使用约束列作为它的主导键。例如,我们假如已经建立了如下的表:
create table inventory( partno number(4), partdesc varchar2(35), price number(8,2), warehouse varchar2(15) );
很明显,PARTNO列应该是这个表的主键(如同以前)。然而,我们的应用需要我们可以通过存储零件的位置来对它们进行搜索,也就是说WAREHOUSE列上的索引会很有用。为了免除建立2个分享索引的麻烦,我们可以使用如下命令:
Create index invent_part_loc_idx On inventory(partno,warehouse) Pctfree 10 Tablespace idx01;
然后,我们再向表增加如下约束:
Alter table inventory add( Constraint invent_partno_pk primary key(partno) Using index invent_part_loc_idx);
这时,Oracle将会检查它是否可以使用已经存在的索引,如果索引能够满足它,它就会使用这个索引。现在需要考虑的就是,我们以前说过的想要使用联合索引中非主导键的查询,这些查询可能会,也可能不会产生可以接受的性能。用户必须要仔细检查通过WAREHOUSE进行的搜索是否变得不可忍受地慢。但是,特别是使用9i的新的跳跃搜索能力时,很有可能要进行一些权衡。
8.7 反转键索引
主键索引还有另一个与它们相关联的主要性能问题。通常,用户会希望表的主键是一个自动增长的序列编号,它会在插入其它的行数据的时候由触发器生。这实际上就是我们以前的EMP表的EMPNO字段的情况,见表8-2。
表8-2 EMP表
|
EMPNO |
NAME |
DEPT |
SAL |
Etc… |
|
70 |
Bob |
10 |
450 |
… |
|
10 |
Frank |
10 |
550 |
… |
|
30 |
Ed |
30 |
575 |
… |
|
20 |
Adam |
20 |
345 |
… |
|
40 |
David |
10 |
550 |
… |
|
60 |
Graham |
30 |
625 |
… |
|
50 |
Charles |
20 |
330 |
… |
|
… |
… |
… |
… |
… |
因此,EMPNO列就是所谓的单调递增序列编号列,这样的字段上的索引有一个不适宜的特性,即不利于多用户应用。
为了分析原因,可以考虑常规的B树索引,见图8-8。
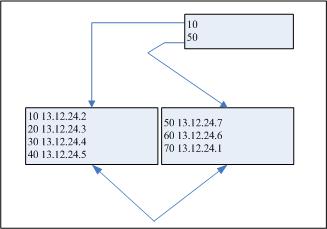
图8-8 常规B树索引
可以注意到,索引已经经过了很好的压缩,每个叶子结点都使用它最大许可数量的表项(我们在前面逻辑了4个表项的限制)进行了填充。现在,当我们雇佣新的员工,在表上执行新的插入的时候,我们很明显不现需要重新访问早先的叶子结点。
这种方法在某些方面具有优势,由于它不会在已有的表项之间嵌入新的表项,所以我们绝对不会经历叶子结点的数据块分割。因此,由于用于索引的PCTFREE设置是专为防止数据块分割而设计的,所以很明显,这里绝对没有任何理由将PCTFREE设置为0以外的其它内容。这意味着单调递增序列编号上的索引能够完全利用它的叶子结点,非常紧密地存放数据,是非常有效率的空间使用者。
然而,这种效率是需要付出代价的。每个新索引表项都总会占据最后的(最右)的叶子结点。随着表项填充了已有的结点,我们就必须获取附加的叶子结点,而所有的插入活动都会直接发生在最新获取的叶子结点中。删除也会导致相似的问题。通常,构建了这类索引的表会周期性地指删除最早的表项(例如,想像一个订货系统,用户在日期上放置索引,并且周期性地清除所有12个月以前产生的订单)。这将导致对索引中第一个(最左边)叶子结点的大量争用。
这意味着如果100个用户要同时在表中插入(或者删除)新记录,他们就会争用相同的叶子结点。当应用运行于并行服务器环境的时候,要特别关注,而且对于运行于多处理器上的单独实例也会出现这种问题。对单调递增序列编号上索引的最后叶子结点的争用可能会很可怕,能够导致访问这个结点的长时间等待。这将会直接表现为想要执行简单DML的用户的极端糟糕的响应时间。
所以,我们需要设计一个规则,用户不应该对单调递增序列编号进行索引,因为这样做可能会产生严重的性能问题。遗憾的是,用户可能无法进行这样的选择。就如我们已经看到的,序列编号通常要用作表的主键,每个主键都需要建立索引,如果用户没有首先建立,Order自己也会建立这样的索引。
我们所需要的是一种能够将我们的插入随机分散到索引中的机制。这种能力在具备反转键(Reverse Key)索引的Order8.0中引入。反转键索引的原理非常简单。在结构和格式方面,它就是常规的B树索引。然而,如果用户使用序列编号在表中输入新记录,例如789,我们就会将其作为1989进行索引。如果用户输入序列编号7892,就会将其作为2989进行索引。7901会作为1097进行索引,依此类推。
要注意,刚才提及的三个序列编号是递增的(升序),而索引表项不是。如果转换成叶子结点活动,就意味着索引上的插入会在所有可能的叶子结点中进行,而不只是最后一个。争用问题因而消失。
开销怎么样呢?用户现在正在将用户的新插入来回分散到索引中。这意味着用户会在已有的表项之间插入新的叶子结点表项,可能会再次出现数据块分割,以及所有它们可能带来的性能下降和存储空间问题。当然,为了防止这一点,用户可以在第一次建立索引的时候,将PCTFREE设置为非零值,在用户开始生成内容之前,就引入无用的空间元素。因此,反转键索引要比非反转的对等索引更大、更空,这也可以解释为需要更多的I/O才能够获取指定的索引表项。因此,在选择进行反转之前,用户需要相当肯定争用问题已经非常严重(表现为叶子结点上“数据块忙等待”),以至于采用反转键索引的优点要大于其缺点。
从应用开发人员的视点来看,更糟糕的潜在问题是,现在不再可能使用索引进行值的范围搜索。在常规的索引中,以下的命令很容易执行:
select for employees with employee numbers between 5600 and 6120
所有这些编号都会在索引的组成部分中彼此相连的旋转,我们能够很容易地定位到第一个编号,然后继续进行增量扫描就可以到达最后一个编号。在反转索引中,那么相同的表项会分布到各处。5601会在索引的开始(1065),但是5609可能就会在末尾(9065),而5611又会在开始的地方(1165)。如果优化器要使用索引,它就要从头到尾进行完全扫描。然而,还有相当大的可能根本不会使用索引。
由于用户不可能总是要利用雇员编号选择一定范围的雇员,所以情况可能没有听起来的那么糟糕。在订单系统的例子中,很少会接收到与编号在7823和8109之间的所有订单有关的投诉。大部分的投诉都会针对于单独的订单编号,这意味着索引中范围搜索能力的缺失没有什么关系。
因此,反转键索引在使用之前要经过仔细的考虑。空间和数据块的问题很重要,引发的性能降低也是我们要考虑的问题。我们正在试图解决的争用问题是否坏到应该进行处理的程度。用户的应用也可能实际需要进行范围搜索,这样就不能使用反转键。权衡利弊的工作很麻烦!
如果用户选择使用反转键索引,那么只需在通常的索引语法的末尾句含一个单词reverse就可以建立它们。例如,在我们的EMP表示例中,我们可使用如下命令:
create index emp_empno_pk on emp(empno) reverse;
顺便提及,需要注意的是,键的反转对用户完全透明!当处理与订单编号23894有关的投诉时,用户不必花费脑力来提交对订单49832的查询。用户可以作用常规的方式查询数据,让优化器来处理反转。
8.8 基于函数的索引
用户使用Oracle时最常遇到的问题之一就是它对字符大小写敏感。如果在我们的EMP表中,我们将员工的名称存储为Fred和Bob,那么搜索FRED、BOB、fred或者bob就不会返回结果行。如果用户不能够确定使用者怎样输入数据,那么就是一个严重的问题。
当然,还有一个方法可以解决这个问题。用户可以使用类似于如下各行的选择语句:
Select name,salary,dept From emp Where upper(name)=’BOB’;
采用这种方法,用户输入数据的时候,无论他们所使用的大小写的组合如何,如果在表中在Bob,这个查询就可以找到它。
遗憾的是,在使用这样的查询时,用户会基于实际上没有在表中存储的值进行记录搜索。而且如果它不在表中,它就一定不会在索引中。所以,即使在NAME列上存在索引,Oracle也会被迫执行全表搜索,为所遇到的各个行计算UPPER函数。
用户现在可以选择直接在NAME列上建立所谓的基于函数(function-based)的索引。这只是常规的B树索引(因此,用来建立它的语法句用于常规索引的语法大体相同),但是它会基于一个应用于表数据的函数,而不是直接放在表数据本身上。
在我们的例子中,以下的命令足以完成任务:
Create index upper_name_idx On emp(upper(name));
除了内部的Order函数以外,用户还可以使用用户自己建立的函数,它们可以使用PL/SQL、JAVA或者C编写。然而,重要的是要记住,用户建立的函数有可能无效,这时所有依赖这个函数构建的基于函数的索引也都会变得失效,并被标记为禁用。用户交会发现过去只需几秒钟来完成(因为它们要转而进行全表搜索)。更糟糕的是那么要更新现在已经禁用的索引的DML,它们会返回ORA-30554 function based index name is disabled错误消息。
如果用户想要使用基于函数的索引,还需要记住一些要点。
- 首先,只有当用户被赋予了QUERY REWRITE系统特权的时候,用户才可以建立它们。
- 其次,如果用户想要在其它模式的表建立这样的索引,那么用户就需要GLOBAL QUERY REWRITE特权。
- 第三,即使用户已经建立了正确的索引,也只有在QUERY_REWRITE_ENABLED init.ora参数设置为TRUE的时候,优化器才会实际使用它们。
要注意,可以使用如下命令对最后的参数进行动态切换:
Alter session set query_rewrite_enabled=true
在设置了所有这些特权之后,用户还需要将init.ora参数QUERY_REWRITE_INTEGRITY设置为TRUSTED。这实际上非常不合时宜,因为这个参数还会决定数据库怎样使用物化视图。这意味着,从基于函数的索引的视角所得到的应用需求,与有效使用物化视力的应用需要之间存在潜在的冲突。
当用户在建立自己的基于函数的索引使用的函数时,必须将它们声明为确定性的(deterministic)。这意味着用户必须着重声明,在给定相同的输入时,这个函数是不可变的(也就是说,返回相同的结果)。
函数的基本语法如下所示:
create or replace function blah( parameters defined here return number [or char etc] deterministic as begin fuction code goes here end; /
优化器在考虑是否有可能使用基于函数的索引来解决查询时相当智能化。查询所提供的WHERE谓词不必与用来建立索引的谓词完全相同。
例如,考虑用户使用这个命令时的情况:
create index maths_idx on emp(sal+empno+sqrt(sal));
即使是对于where sqrt(sal)+sal+empno=456这样的查询,这里所建立的索引也会有用。换句话说,它可以考虑到算术交换的思想,能够看出这个索引可以解决这个查询,而不用顾忌在查询中所提供的函数各个部分的次序。
只对索引进行的搜索
这里有一种特殊类型的查询,它可以劝说优化器完全使用基于函数的索引。
例如,如果我们建立如下基于函数的索引:
Create index emp_funct_comm_idx On emp(sqrt(comm));
那么用户:
Select sqrt(comm.) from emp order by sqrt(comm.);
在Order8i中不能判别sqrt()里面的是否为NULL,即NULL不能够包含在索引中,故此查询还是会走全表搜索。
在Order9i中得到了修复。
试验:基于函数的索引
(1) 我们首先要重新建立INDEXTEST表,设置QUERY_REWRITE_ENABLED=TRUE,以便我们可以使用基于函数的索引。在OBJECT_NAME列上建立常规的B树索引,看看我们是否能够将其用于字符大小写不敏感的搜索:
SQL> alter session set QUERY_REWRITE_ENABLED=TRUE; 会话已更改。 SQL> set autotrace trace explain SQL> create table indextest as select * from dba_objects 2 where owner in('OUTLN','PUBLIC','SCOTT','SYS','SYSTEM'); 表已创建。 SQL> analyze table indextest compute statistics; 表已分析。 SQL> create index indxtst_objname_idx on indextest(object_name); 索引已创建。 SQL> select object_name,owner from indextest 2 where upper(object_name)='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=36 Card=250 Bytes=72 50) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=36 Card=250 Bytes =7250)
(2) 对于OBJECT_NAME列上的常规B树索引,很明显我们不走运。我们来删除这个索引,使用基于函数的索引对其进行替代:
SQL> drop index indxtst_objname_idx; 索引已丢弃。 SQL> create index indxtst_objname_idx on indextest(upper(object_name)); 索引已创建。 SQL> select object_name,owner from indextest 2 where upper(object_name)='DBA_INDEXES'; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=250 Bytes=725 0) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'INDEXTEST' (Cost=2 Card= 250 Bytes=7250) 2 1 INDEX (RANGE SCAN) OF 'INDXTST_OBJNAME_IDX' (NON-UNIQUE) (Cost=1 Card=100)
(3) 现在,我们要看看是否能够劝说优化器只在索引内解决查询。在理论上这很容易,只要我们不选择不在索引中的列就可以!
SQL> select upper(object_name) from indextest; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=36 Card=25035 Bytes= 600840) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=36 Card=25035 Byt es=600840)
(4) Oracle 8i中
SQL> alter table indextest modify object_name not null; 表已更改。 SQL> select upper(object_name) from indextest; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=36 Card=25035 Bytes= 600840) 1 0 TABLE ACCESS (FULL) OF 'INDEXTEST' (Cost=36 Card=25035 Byt es=600840)
(5) Oracle 9i中
SQL> alter table indextest modify object_name not null; 表已更改。 SQL> select upper(object_name) from indextest; Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=25035 Bytes=6 00840) 1 0 INDEX (FAST FULL SCAN) OF 'INDXTST_OBJNAME_IDX' (NON-UNIQU E) (Cost=4 Card=25035 Bytes=600840)
工作原理
在OBJECT_NAME列上建立常规的B树索引,对于优化器解决要求与UPPER(OBJECT_NAME)相匹配的查询没有任何用处。它还是必须执行值班表搜索。Oracle 8i和Oracle 9i中对基于函数的索引里的列值为NULL的处理不同。
8.9 位图索引
我们来考虑表8-3:
表8-3 位图索引示例表
|
ID |
MANAGER |
DEPT |
GENDER |
Etc… |
|
70 |
QS |
10 |
M |
… |
|
10 |
RW |
10 |
M |
… |
|
60 |
RW |
30 |
F |
… |
|
20 |
QS |
20 |
F |
… |
|
40 |
QS |
10 |
M |
… |
|
30 |
RW |
30 |
M |
… |
|
50 |
RW |
20 |
F |
… |
|
… |
… |
… |
… |
… |
我们来看看如果在GENDER列上建立常规的B树索引:
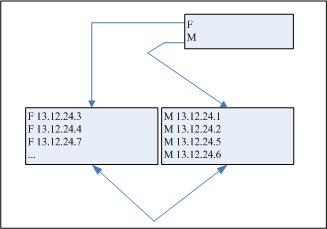
图8-9 GENDER列上的索引图示
我们拥有一个包含了2个可能值的分支数据块,还有一个包容“F”(“Female”)的叶子结点,随后还有一个包容“M”(“Male”)的结点。这不是具有高度选择性的索引!对列的任何选择都可能会返回将近一半数量的行。这时,用户可能会记起当查询搜索超过2到5%的行时,Order就不大可能触及索引。而且,这样的索引会消耗空间,并且必定会降低DML活动的性能,完全没有用处。
像这样具有非常少独特值的数据被认为具有低区分值(cardinality)。(区分值可以定义为“具有不同值的倾向”)。性别的区分值是2,以上所示的表中的MANAGER列也是如此。DEPARTMENT列的区分值为3。然而,作为单调递增序列编号的ID列的区分值潜在等于表中行的数量(每个值都与其它的值不同)。
这就意味着我们在选择低区分值的时候一定会执行全表搜索么?幸运的是,答案为否,因为我们可以为这样的列使用位图索引(Bitmap indexes)。语法:
create bitmap index emp_mgr_bmp on emp(manager);
一旦使用了这个命令,它就会在我们完成整个表的扫描期间,在整个表上放置一个DML锁定(在这个扫描期间绝对不允许DML活动)。当我们扫描表的时候,我们会为MANAGER列中遇到的各个值构建“真值表”。见表8-4.
表8-4 真值表
|
QS |
RW |
|
1 |
0 |
|
0 |
1 |
|
0 |
1 |
|
1 |
0 |
|
1 |
0 |
|
0 |
1 |
|
0 |
1 |
然后,这个真值表会在典型的B树格式中存储,每个叶子结点都会为所发现的一个值存储完整的位图(如果不能够在一个节点中容纳位图,我们就会继续请求附加的节点,来容纳多余的内容)。在我们的例子上,索引将会如图8-10所示。
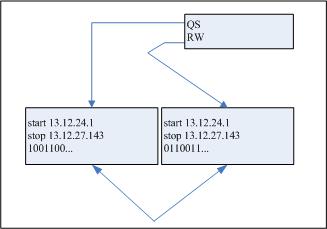
图8-10 位图索引
可以注意到,1和0自己不能作为指向行的指针,但是如果给定各个1和0的相对位置,那么所包含的关键起始和终止rowid就可以让我们推演出表中行的物理位置。
如果我们为我们表中剩余的2个列重复这一过程,为DEPARTMENT和GENDER列构建位图索引,那么我们就会生成如表8-5所示的真值表:
表8-5 DEPARTMENT和GENDER列的真值表
|
10 |
20 |
30 |
F |
M |
|
|
1 |
0 |
0 |
0 |
1 |
|
|
1 |
0 |
0 |
0 |
1 |
|
|
0 |
0 |
1 |
1 |
0 |
|
|
0 |
1 |
0 |
1 |
0 |
|
|
1 |
0 |
0 |
0 |
1 |
|
|
0 |
0 |
1 |
0 |
1 |
|
|
0 |
1 |
0 |
1 |
0 |
通过使用所有的三个索引,我们现在就可以快速地回答(通过索引)想要显示女性、由RW管理,在部门30工作的查询请求。
当面对这样的查询时,优化器就要从GENDER位图索引中获取FEMALE位图,从MANAGER位图索引中获取RW位图,从DEPARTMENT位图索引中获取30位图,然后再在它们上执行逻辑AND布尔运行,见表8-6。
表8-6 位图索引使用过程
|
F |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
|
RW |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
|
30 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
|
AND |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
因此,对于OR测试来讲,位图索引会比常规的B树索引更有效率。
总而言之,位图索引是在低区分值列上建立的压缩对象(因为存在存储能够代表上百万行的伴串也不会占用太多的空间):由于它们能够同AND操作一样有效地执行“OR”操作,所以它们能够非常快地测试许多行的多个条件。
当表上存在位图索引的时候,在附属表上的并发的DML活动就将很难实现。由于OLTP应用总是要进行并发DML,所以就得出了一个简单的规则:位图索引和OLTP系统不能够共存。
另一方面,在数据仓库的情况下,由于数据量巨大,而且查询多个低区分值属性的需求很高,并发的DML几乎不存在,所以使用位图索引就很理想。
我们需要澄清,只有表上并发的DML活动才是问题所在,而不是DML活动本身。即使是非并发的DML也不能够和位图索引非常融洽地共处。
8.10 位图联接索引
Oracle 9i引入了一种新功能,可以基于一些实际包含在完全不同的表中的值,在一个表上建立位图索引。这样的索引从结构上讲是另一种位图索引,它被称为位图联接索引(bitmap join index)。参见表8-7的2个表:
表8-7 位图联接索引示例表
SALES
|
ORDNO |
CUSTCODE |
VALUE |
|
101 |
A |
103.40 |
|
102 |
A |
123.90 |
|
103 |
B |
9832.90 |
|
104 |
D |
546.75 |
|
105 |
C |
798.34 |
CUSTOMERS
|
CUSTCODE |
NAME |
LOCATION |
|
A |
Acme Inc |
New York |
|
B |
Bretts plc |
London |
|
C |
Coals Pty |
Sydney |
|
D |
D’Allain |
Paris |
现在假定用户希望知道New York的销售总数。销售额可以从SALES表中获取,但是位置New York要从CUSTOMERS表中获取。这意味着用户必须要查询2个表,通过它们共有的CUSTCODE列对它们进行联接。
我们可以使用如下命令:
create bitmap index cust_location_bmj on sales(customers_location) from sales,customers where sales.custcode=customers.custcode;
所得到的位图索引将会如图8-11所示。
图8-11 位图联接索引示例
如果我们现在进行如下查询:
select sum(sales.value) from sales,customers where sales.custcode=customers.custcode and customers.location=’New York’;
…那么优化器就能够从索引中获取New York的位图来解决查询。这个位置会读取“11000…”,它会告诉我们SQLES表中的前2行与New York有关,我们现在就能够使用通常的方式从SALES表中进行选取,获取这些记录。
另一方面,用户需要记住,位图联接索引和任何类型的DML都不能相处得很好,所以这是严格的数据仓库解决方案。
- 除此之外,如果使用了位图联接索引,那么任何时候都只能更新所涉及的一个表。换句话说,如果另一个用户正在更新SALES表,那么直到他们提交或者回滚,都不能够更新CUSTOMERS表。我的事务处理要进行排除。
- 对于我们的SALES和CUSTOMERS表,我们不能有2个具有代码“A”的客户,一个在New York,一个在Paris。声明CUSTCODE列具有唯一性(或者更有可能将其声明为CUSTOMERS表的主键)。
8.11 小结
用好索引的原因有:
- 用户所建立的所有索引都会减缓DML。
- 用户所建立的所有索引都会消耗空间和其它数据库资源。
- 随着时间推移,索引退化会逐渐降低应用本该有的性能。
- 为恢复索引的效率,管理员必须相当频繁地对其进行重建,重建索引是开销相当大的操作,它可以影响性能和数据可获得性。
- 如果优化器认为索引在解决查询中没有帮助,就不会使用索引;那么用户就根本没有理由消耗空间、数据库资源,并且降低性能来建立索引。
然而在正确的环境中,仔细设计的索引能够显著加速数据获取。简述如下:
- 好的索引要建立在频繁用于查询或者表联接谓词的列上。
- 如果B树索引具有相当的选择性(记住2-5%规则),或者可以只通过引用索引就可以回答查询,那么优化器就认为其有用。
- 如果进行联接,那么应该仔细考虑列的次序,次序应该由利用这些次序的查询性质所决定。
- 所有索引都至少要考虑进行压缩。
- 基于函数的索引能够带来极大的性能和编程收益,但是要意识到,由于NULL没有排除在所请求的结果集合外,所以用户定义的函数可能会遇到无效和潜在的问题。
- 可以使用反转键,来防止索引上的“缓存忙等待”过分糟糕。
- 有效地利用位图索引需要其数量众多,以及很少或者没有DML。
文章根据自己理解浓缩,仅供参考。
摘自:《Oracle编程入门经典》 清华大学出版社 http://www.tup.com.cn
