正则化是为了防止过拟合,因为正则化能降低权重
caffe默认L2正则化
代码讲解的地址:http://alanse7en.github.io/caffedai-ma-jie-xi-4/
重要的一个回答:https://stats.stackexchange.com/questions/29130/difference-between-neural-net-weight-decay-and-learning-rate
按照这个答主的说法,正则化损失函数,正则化之后的损失函数如下:

这个损失函数求偏导就变成了:加号前面是原始损失函数求偏导,加号后面就变成了 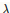 *w,这样梯度更新就变了下式:
*w,这样梯度更新就变了下式:
wi←wi−η
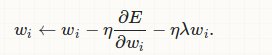
L2正则化的梯度更新公式,与没有加regulization正则化相比,每个参数更新的时候多剪了正则化的值,相当于让每个参数多剪了weight_decay*w原本的值
根据caffe中的代码也可以推断出L1正则化的公式:
把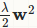 替换成
替换成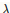 *w的绝对值
*w的绝对值
所以求偏导的时候就变成了,当w大于0为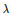 ,当w小于0为-
,当w小于0为-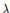
void SGDSolver<Dtype>::Regularize(int param_id) { const vector<shared_ptr<Blob<Dtype> > >& net_params = this->net_->params(); const vector<float>& net_params_weight_decay = this->net_->params_weight_decay(); Dtype weight_decay = this->param_.weight_decay(); string regularization_type = this->param_.regularization_type(); Dtype local_decay = weight_decay * net_params_weight_decay[param_id]; switch (Caffe::mode()) { case Caffe::CPU: { if (local_decay) { if (regularization_type == "L2") { // add weight decay caffe_axpy(net_params[param_id]->count(), local_decay, net_params[param_id]->cpu_data(), net_params[param_id]->mutable_cpu_diff()); } else if (regularization_type == "L1") { caffe_cpu_sign(net_params[param_id]->count(), net_params[param_id]->cpu_data(), temp_[param_id]->mutable_cpu_data()); caffe_axpy(net_params[param_id]->count(), local_decay, temp_[param_id]->cpu_data(), net_params[param_id]->mutable_cpu_diff()); } else { LOG(FATAL) << "Unknown regularization type: " << regularization_type; } } break; }
caffe_axpy的实现在util下的math_functions.cpp里,实现的功能是y = a*x + y,也就是相当于把梯度更新值和weight_decay*w加起来了
caffe_sign的实现在util下的math_functions.hpp里,通过一个宏定义生成了caffe_cpu_sign这个函数,函数实现的功能是当value>0返回1,<0返回-1