一、单机部分
1、redis优点
1.1 redis为什么这么快?
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞 I/O 多路复用机制
1.2 线程模型

Redis-client 在操作的时候,会产生具有不同事件类型的 Socket。在服务端,有一段 I/O 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
2. 基本数据类型
String
最常规的 set/get 操作,Value 可以是 String 也可以是数字。一般做一些复杂的计数功能的缓存。
List
使用 List 的数据结构,可以做简单的消息队列的功能。另外,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。
Hash
采用hash存储key-value pair
Set
Set 堆放的是一堆不重复值的集合。Set是一个特殊的value为null的Hash
Sorted Set
Sorted Set 多了一个权重参数 Score,集合中的元素能够按 Score 进行排列,Sorted Set的数据结构是一种跳表,即SkipList
对应的内部编码:
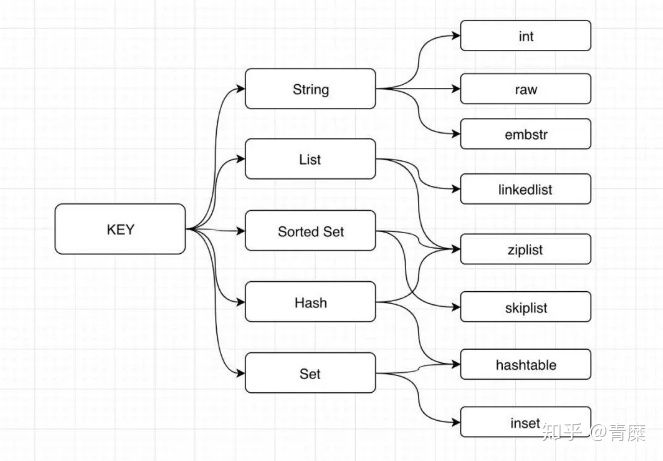
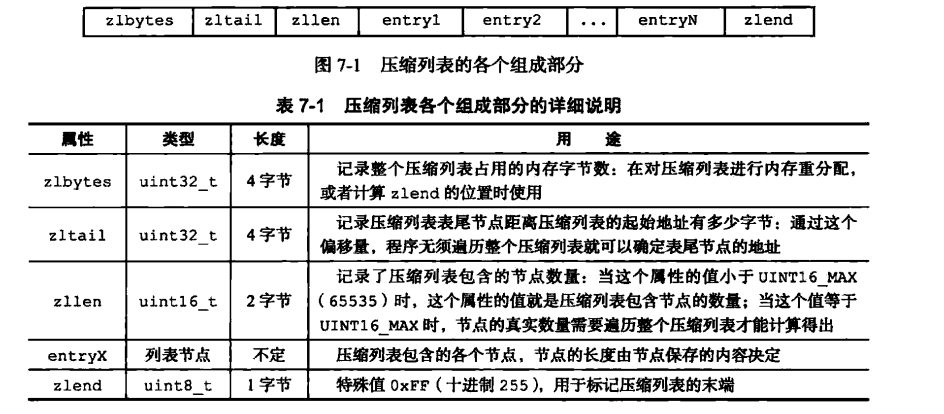
其中ziplist结构:
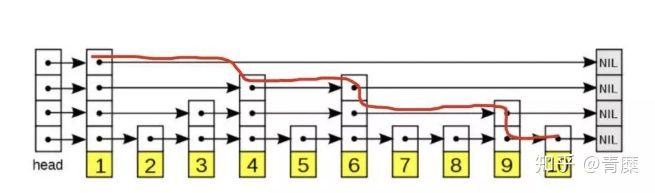
skiplist结构:
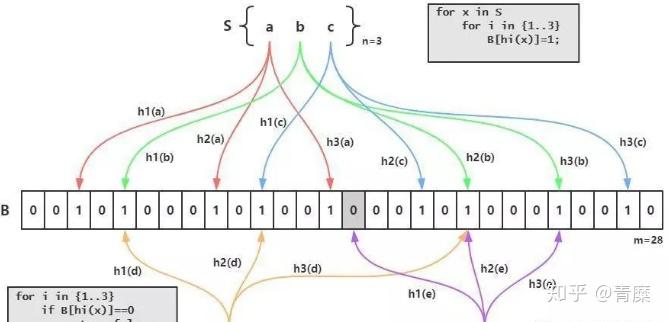
高级数据结构: bitmap
这个就是Redis实现的BloomFilter,BloomFilter非常简单,如下图所示,假设已经有3个元素a、b和c,分别通过3个hash算法h1()、h2()和h2()计算然后对一个bit进行赋值,接下来假设需要判断d是否已经存在,那么也需要使用3个hash算法h1()、h2()和h2()对d进行计算,然后得到3个bit的值,恰好这3个bit的值为1,这就能够说明:d可能存在集合中。再判断e,由于h1(e)算出来的bit之前的值是0,那么说明:e一定不存在集合中:
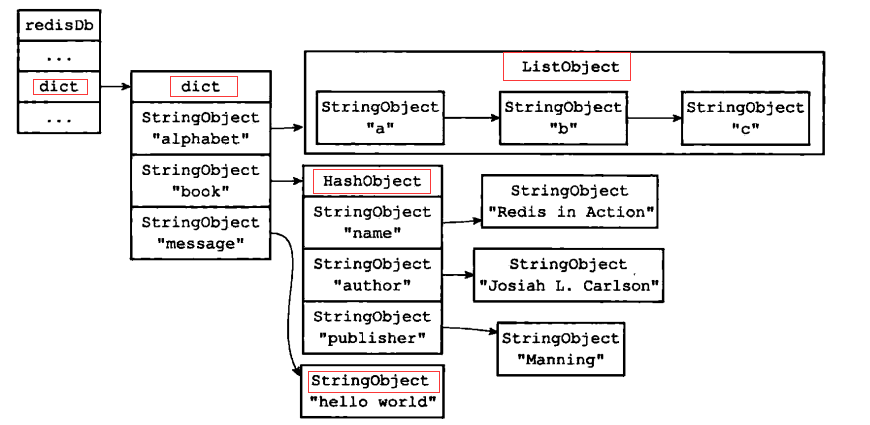
3. redis数据库键值空间
Redis是一个key-value数据库,redisDb中的dict字典元素存储了DB中的所有key-value pair,这个字典dict即为数据库的键空间。
键空间的键即为数据库的键,每个键是一个字符串对象
键空间的值即为数据库的值,每个值可以是字符串对象、hash对象、列表对象等。
一个典型的键空间如下:
2.1 数据库增删查改
1、增加键
直接调用SET <key> <value>。
2、删除键
调用DEL <key>
3、更新键
同样使用SET 命令,覆盖之前的value。
4 获取键内容
GET <key>
2.2 键的超时时间
通过EXPIRE <key> <ttl>可以设置键的生存时间,经过指定的秒数以后,服务器会自动删除超过生存时间的键。
redisDb中的expires字典保存数据库中所有键的过期时间,记为过期字典。
过期字典中的键是一个指针,指向键空间dict中的某个对象。
过期字典的值是一个long long类型的整数,保存过期字典键指向的数据库对象的过期时间。
过期删除策略包括:
- 定时删除
- 惰性删除
- 定期删除
、Redis采用的过期策略
惰性删除+定期删除
- 惰性删除流程(实现在db.c/expireIfNeed)
- 在进行get或setnx等操作时,先检查key是否过期,
- 若过期,删除key,然后执行相应操作;
- 若没过期,直接执行相应操作
- 定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key,实现在redis.c/activeExpireCycle)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
- 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
- 判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
采用定期删除+惰性删除就没其他问题了么?
如果定期删除没删除掉 Key。并且你也没及时去请求 Key,也就是说惰性删除也没生效。这样,Redis 的内存会越来越高。那么就应该采用内存淘汰机制。
内存淘汰策略
1. noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
2. allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
3. volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
4. allkeys-random:加入键的时候如果过限,从所有key随机删除
5. volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
6. volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
7. volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
8. allkeys-lfu:从所有键中驱逐使用频率最少的键
该配置就是配内存淘汰策略的: LRU, Random, LFU等
4. redis持久化
4.1 RDB:
rdb是Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数

RDB持久化是将当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),保存的文件后缀是rdb;当Redis重新启动时,可以读取快照文件恢复数据。 那么RDB持久化的过程,相当于在执行bgsave命令。该命令执行过程如下图所示
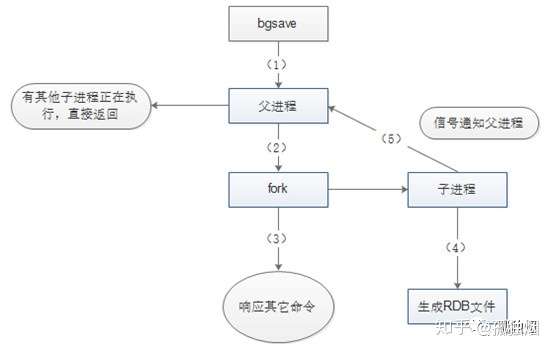
如图所示,主线程需要调用系统函数fork(),构建出一个子进程进行持久化!很不幸的是,在构建子进程的过程中,父进程就会阻塞,无法响应客户端的请求!
4.2 AOF
Aof是Append-only file缩写,作用类似于CDP(持久数据保护)

AOF原理: 服务器在处理写命令时,将写命令追加到aof_buf缓存中,服务器每结束一次事件循环,会调用flushAppendOnlyFile,考虑是否将aof_buf中数据写入AOF文件


如果突然机器掉电会怎样?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
5. table rehash
渐进式rehash:

二、集群
1. Redis 架构模式及特点
单机版

特点:简单
问题:
1、内存容量有限 2、处理能力有限 3、无法高可用。
主从复制

Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
原理:
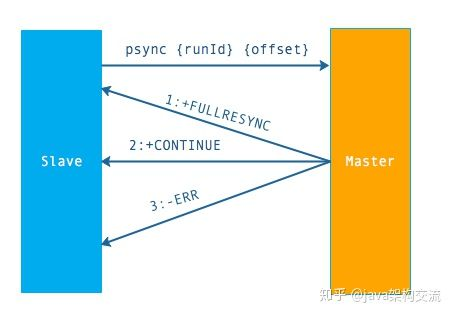
流程说明:从节点发送 psync 命令给主节点,runId 就是目标主节点的 ID,如果没有默认为 -1,offset 是从节点保存的复制偏移量,如果是第一次复制则为 -1.
主节点会根据 runid 和 offset 决定返回结果:
- 如果回复 +FULLRESYNC {runId} {offset} ,那么从节点将触发全量复制流程。
- 如果回复 +CONTINUE,从节点将触发部分复制。
- 如果回复 +ERR,说明主节点不支持 2.8 的 psync 命令,将使用 sync 执行全量复制。
优点:降低 master 读压力在转交从库
问题:
无法保证高可用
没有解决 master 写的压力
哨兵

Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:主从模式,切换需要时间丢数据
没有解决 master 写的压力
集群(proxy 型):

Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点:1、多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
缺点:增加了新的 proxy,需要维护其高可用。
Redis cluster
为什么集群? 通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。 Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事 儿,在这种情况下,如何正确架构Redis呢? 首先,无论我们是使用自己的物理主机,还是使用云服务主机,内存资源往往是有限制的,scale up不是一个好办法,我们需要scale out横向可伸缩扩展,这需要由多台主机协同提供服务,即分布 式多个Redis实例协同运行。 其次,目前硬件资源成本降低,多核CPU,几十G内存的主机很普遍,对于主进程是单线程工作的 Redis,只运行一个实例就显得有些浪费。同时,管理一个巨大内存不如管理相对较小的内存高效。 因此,实际使用中,通常一台机器上同时跑多个Redis实例。
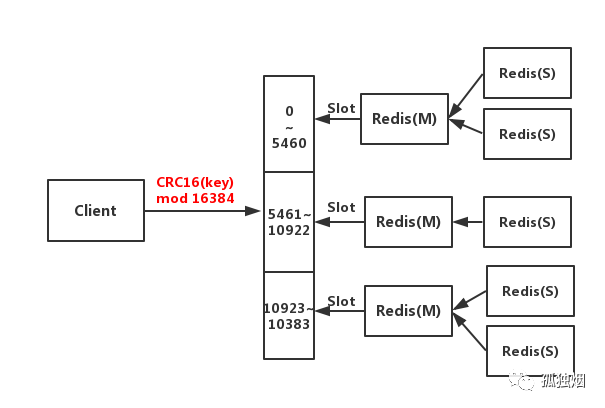
工作原理如下
- 客户端与Redis节点直连,不需要中间Proxy层,直接连接任意一个Master节点
- 根据公式
HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作
具有如下优点:
(1)无需Sentinel哨兵监控,如果Master挂了,Redis Cluster内部自动将Slave切换Master
(2)可以进行水平扩容
(3)支持自动化迁移,当出现某个Slave宕机了,那么就只有Master了,这时候的高可用性就无法很好的保证了,万一master也宕机了,咋办呢? 针对这种情况,如果说其他Master有多余的Slave ,集群自动把多余的Slave迁移到没有Slave的Master 中。
方案
1.Redis官方集群方案 Redis Cluster Redis Cluster是一种服务器Sharding技术,3.0版本开始正式提供。 Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类pre sharding 思路。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使 用的hash算法也比较简单,就是CRC16后16384取模。
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一 个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也 要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入。
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的 slots也就失效,整个集群将不能工作。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n 个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上 升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务 器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。 Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它 nodes进行通信,这被称为集群总线(cluster bus)。
它们使用特殊的端口号,即对外服务端口号加 10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes 之间的通信采用特殊的二进制协议。 对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操 作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向 正确的node,这有点儿像浏览器页面的302 redirect跳转。
2. redis缓存
2.1 缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
Solution:
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 Key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
- 查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存
2.2 缓存雪崩
缓存雪崩,即缓存同一时间大面积的失效或者缓存故障导致缓存不可用, 这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
缓存雪崩的事前事中事后的解决方案如下:
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
用户发送一个请求,系统 A 收到请求后,先查本地 ehcache 缓存,如果没查到再查 redis。如果 ehcache 和 redis 都没有,再查数据库,将数据库中的结果,写入 ehcache 和 redis 中。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空白的值。
好处: - 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。 - 只要数据库不死,就是说,对用户来说,2/5 的请求都是可以被处理的。 - 只要有 2/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 使用互斥锁,但是该方案吞吐量明显下降了。
3. Redis 和 DB 数据一致
Cache Aside Pattern
这是最常用最常用的pattern了。其具体逻辑如下:
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。为什么不是写完数据库后更新缓存?主要是怕两个并发的写操作导致脏数据。
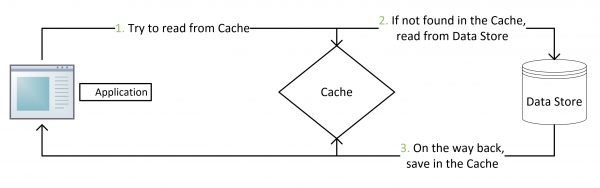
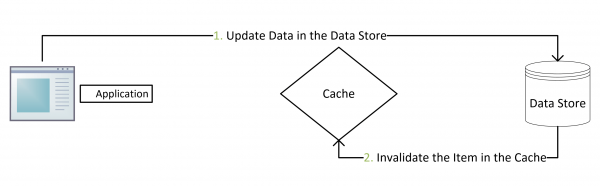
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
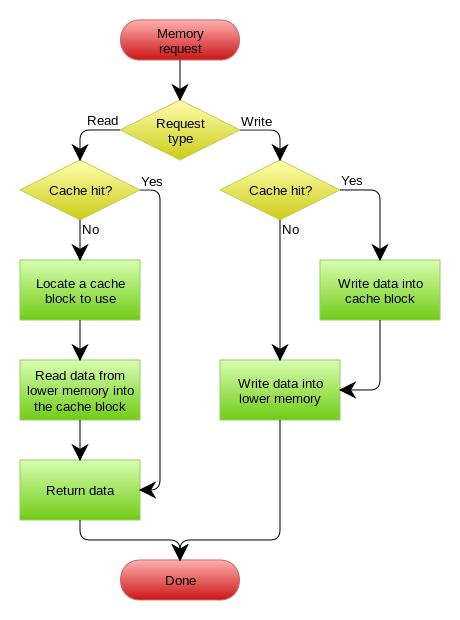
Read/Write Through Pattern
我们可以看到,在上面的Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
下图自来Wikipedia的Cache词条。其中的Memory你可以理解为就是我们例子里的数据库。
Write Behind Caching Pattern
Write Behind 又叫 Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。