要弄懂JVM的垃圾回收,首先要知道我们要回收什么,在哪回收,什么时候回收。
一、JVM内存模型
java虚拟机把内存模型分为了这么几部分
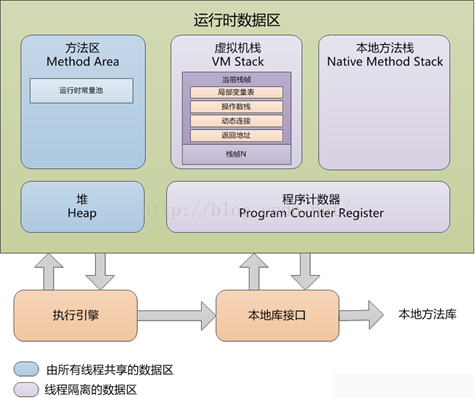
(1)程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。
(2)Java虚拟机栈
用于存放局部变量表、操作数栈、动态链接、返回地址等。
局部变量表存放了编译期间可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)。
返回地址指向了一条字节码指令的地址。
(3)本地方法栈
为Native方法服务。
(4)Java堆
Java堆是JVM最大的一部分。主要存放对象实例的。
(5)方法区
它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
非线程共享的区域有程序计数器,java虚拟机栈,本地方法栈。即内存随自身的线程生而生,随线程的死亡而死亡。
线程共享的区域有Java堆,方法区,即内存的分配与回收是动态的。
垃圾回收主要也集中在线程共享区域。
二、常见的垃圾回收算法
1、引用计数法
引用计数算法是垃圾回收的早起策略,这种方法中堆中每个对象实例都有1个计数器,当任何其它变量被赋值为这个对象引用时,计数加1。
缺点:
无法检测循环引用,引用计数算法无法检测出来,被循环引用的对象就成了无法回收的内存。从而引起内存泄漏。
class A{public B b;} class B{public A a;} public class Main{ public static void main(String [] args){ A a = new A(); B b = new B(); a.b = b; b.a = a; } }
2、可达性分析算法
从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完之后,剩余的没有被引用的节点会被判定为可回收对象。
可作为GC ROOT的对象包括下面几种:
(1)虚拟机栈中引用的对象
(2)方法区中静态类属性引用的对象
(3)方法区中常量引用的对象
3、标记清除算法
从根进行扫描,对存活的对象进行标记,标记完毕后,再扫描整个空间中未被标记的空间。在存活对象较多的情况下极为高效。由于标记清除直接回收不存活的对象,会造成内存碎片。
4、复制算法
复制算法的提出是为了克服内存碎片和句柄开销问题的。开始的时候把堆分为一个对象面和多个空闲空间,然后把对象面的对象移动到空闲面,这样空闲面变成了对象面,原来的对象面变成了空闲面。
5、标记整理算法
采用标记清除算法一样的方式进行标记。在回收不存活的对象占用的空间后,会将所有的存活对象往左端空闲空间移动,并更新对应的指针。标记整理算法是在标记清除算法的基础上,又进行了对象的移动,因此成本搞,但是却解决了内存碎片的问题。
6、分代算法
分代收集算法是目前大部分JVM的垃圾收集器采用的算法。它的核心思想是根据对象存活的生命周期将内存划分为不同的区域,一般情况下将堆区域划分为老年代和新生代,在堆区之外还有一个代就是永久代。老年代的特点是每次垃圾收集时只有少量被回收,而新生代的特点是每次垃圾回收有大量的对象都被回收。
(1)年轻代的回收算法
- 所有新生成的对象都是放在年轻代的,年轻代的目标就是尽可能快速的收集那些生命周期短的对象。
- 年轻代的内存按8:1的比例分为1个eden区和两个survivor区。大部分对象在eden区生成,回收时先将eden区存活的对象复制到1个survivor区,然后清空eden,当survivor0满了,将eden区和survivor0区存放的对象复制到survivor1中,然后清空eden和这个survivor0。此时survivor0区是空的,然后将survivor0区和survivor1交换。即保持survivor1是空的,如此往复。
- 当survivor1区不足以存放eden和survivor0的存活对象时,就将存活直接存放到老年代,若是老年代也满了就触发一次full gc
- 年轻代的GC也叫Minor GC,Minor GC发生的频率比较高(不一定等EDEN区满了才触发)
(2)老年代
在年轻代经历了N次垃圾回收后仍然存活的对象,就会被放到老年代中,因此,可以认为年老代存放的都是一些生命周期较长的对象。
三、常见的垃圾收集器
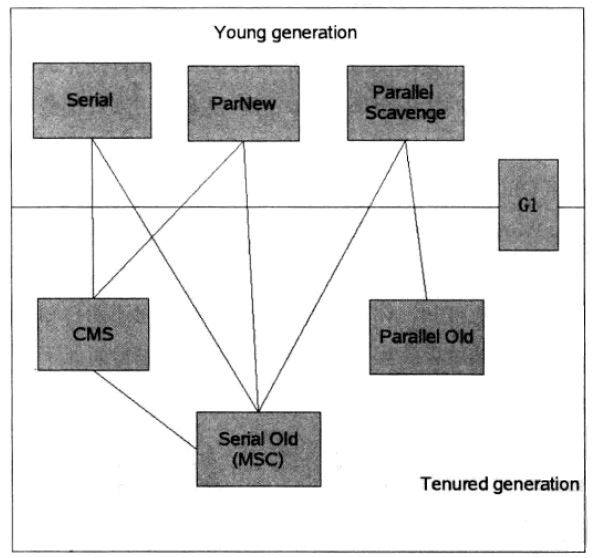
1、Serival收集器(复制算法)
新生代单线程收集器,标记和清理都是单线程的
2、Serival Old收集器
老年代单线程收集器,Serial收集器的老年代版本
3、ParNew收集器(停止-复制算法)
Serial的多线程版本
4、Parallel Scavenge收集器(停止-复制算法)
并行收集器,追求高吞吐量,高效利用CPU
5、Parallel Old收集器(老年代的停止复制算法)
6、CMS收集器(标记-清理算法)
高并发、低停顿、追求最短GC回收停顿时间,CPU占用比较高响应时间
7、G1 GC
G1的设计原则是"首先收集尽可能多的垃圾(Garbage First)"。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小.
G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。
三、垃圾回收的时间
由于对垃圾进行了分代,因此不同代的垃圾回收时间也不一样。垃圾回收分为两类,Scavenge GC和Full GC。
1、Scavenge GC
一般情况下,当在Eden区申请空间失败时,就会触发Scavenge GC。
2、Full GC
对年轻代和老年代的垃圾都进行回收。Full GC时间长,因此尽量减少Full GC次数。
当老年代被写满的时候会触发Full GC, 当持久代被写满,显示调用System.gc()。