在网上观摩了一些大佬关于线程池的实现后,我决定也亲手写一下简单线程池,首先先解释一下什么是线程池,简单的来说,就是预先创建一些线程,使它们处于睡眠状态,当任务来临时,唤醒线程让它们去执行。使用线程池的好处有很多,比如,1.线程的创建和销毁的开销,无论从时间还是空间上来说是巨大的,而通过线程池的重用大大减少了这些不必要的开销,当然既然少了这么多消费内存的开销,其线程执行速度也是得到提升,2.还有有效的控制线程的并发数,控制线程的并发数可以有效的避免大量的线程争夺CPU资源而造成堵塞。
关于设计这个线程池,从概念出发,预先创建一些线程(创建线程,其后必须也伴随着销毁线程),使它们处于睡眠状态(挂起或者阻塞态),当任务来临时(设计一个队列专门装任务),唤醒线程并执行(线程函数所完成),同时再设计一个具体描述任务的父类并设置成纯虚函数,用户在使用此线程池的时候,只需要重写父类就可以了,所以大致需要实现的功能如下图所示: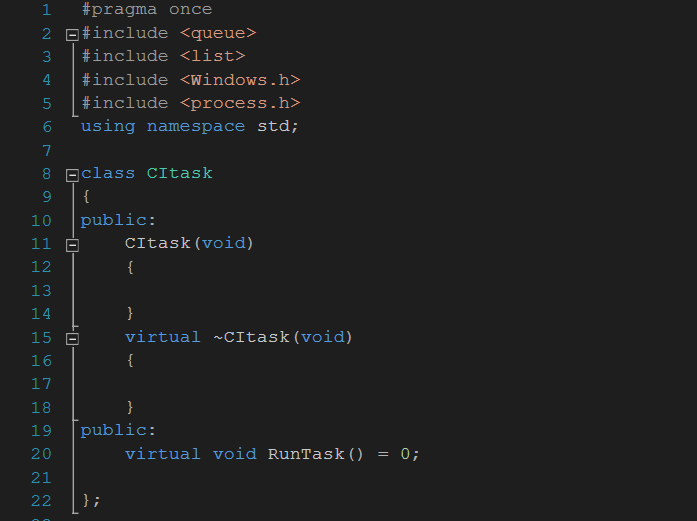

接下来按每个功能进行讲述:
1.创建线程

1 //先检查参数正确性 2 if(ThreadNUM_MIN < 0 || ThreadNUM_MAX < ThreadNUM_MIN) 3 return false; 4 //创建信号量(在创建线程前创建信号量,防止线程空转) 5 m_hSemphore = CreateSemaphore(NULL,0,ThreadNUM_MAX,0); 6 //创建指定个数线程 7 for(int i = 0;i < ThreadNUM_MIN;i++) 8 { 9 HANDLE handle = (HANDLE)_beginthreadex(NULL,0,&ThreadFunction,this,0,0); 10 if(handle) 11 { 12 m_lHandle.push_back(handle); 13 } 14 } 15 return true;
首先值得说的有两点,第一点,在这里创建线程我使用的是_beginthreadex(安全属性,线程栈大小,线程函数地址,线程函数参数,线程初始态,线程标识符),而不是用CreateThread(),这是因为如果在代码中有使用标准C运行库中的函数时,尽量使用_beginthreadex()来代替CreateThread()(这个函数解决的应该是一个历史遗留问题,标准C运行库在1970年被实现了,由于当时没任何一个操作系统提供对多线程的支持。因此编写标准C运行库的程序员根本没考虑多线程程序使用标准C运行库的情况)比如标准C运行库的全局变量errno。很多运行库中的函数在出错时会将错误代号赋值给这个全局变量,这样可以方便调试。但如果有这样的一个代码片段:
1 if (system("notepad.exe readme.txt") == -1) 2 { 3 switch(errno) 4 { 5 ...//错误处理代码 6 }
假设某个线程A在执行上面的代码,该线程在调用system()之后且尚未调用switch()语句时另外一个线程B启动了,这个线程B也调用了标准C运行库的函数,不幸的是这个函数执行出错了并将错误代号写入全局变量errno中。这样线程A一旦开始执行switch()语句时,它将访问一个被B线程改动了的errno。这种情况必须要加以避免!因为不单单是这一个变量会出问题,其它像strerror()、strtok()、tmpnam()、gmtime()、asctime()等函数也会遇到这种由多个线程访问修改导致的数据覆盖问题,通过查看源码可知,_beginthreadex()是先创建了一个内存块,再调用CreateThread(),这个内存块中用来存放一些需要线程独享的数据。事实上新线程运行时会首先将内存块与自己进一步关联起来。然后新线程调用标准C运行库函数如strtok()时就会先取得内存块的地址再将需要保护的数据存入内存块中。这样每个线程就只会访问和修改自己的数据而不会去篡改其它线程的数据了。
第二点,在设计线程睡眠状态时,有很多种方法 挂起(恢复指定线程),阻塞中有关键段/临界区(无安全属性,不适用),事件(无法唤醒指定线程,不适用),互斥量(同事件),所以我选择的是信号量用来阻塞线程和恢复线程,因为就如同停车场一样,我只是开放了车位,至于哪辆车(线程)停进来由系统随机分配。
2.销毁线程
1 m_bFlagExit = false; 2 list<HANDLE>::iterator ite = m_lHandle.begin(); 4 while(ite != m_lHandle.end()) 5 { 6 if(WaitForSingleObject(*ite,100) == WAIT_TIMEOUT) 7 TerminateThread(*ite,-1); 8 CloseHandle(*ite); 9 *ite = 0; 10 ite++; 11 } 12 m_lHandle.clear();14 CloseHandle(m_hSemphore); 15 m_hSemphore = 0;
能自然退出就自然退出,若遇到线程无法关闭的情况,即(等待线程中内核对象的信号量100ms内为无信号时),强制退出
3.线程函数
CMyThreadPool *pThis = (CMyThreadPool *)lpvoid; CItask *pItask = NULL; while(pThis->m_bFlagExit) { if(!pThis->m_qItask.empty()) { pItask = pThis->m_qItask.front(); pThis->m_qItask.pop(); pItask->RunTask(); delete pItask; pItask = NULL; }} </span><span style="color: #0000ff;">return</span> <span style="color: #800080;">0</span>;</pre>
目的很简单,在无退出标记的情况下,从队列中取出一个任务,来一个线程去执行
4.投递任务
if(itask == NULL) return false; m_qItask.push(itask); //释放一个信号量 ReleaseSemaphore(m_hSemphore,1,0);
将一个任务投入队列中,并且释放一个信号量
5.代码优化
1》在重写任务类后,尝试创建了两个线程去执行 从1加到10000000000的任务,不出意外的崩了,原因是 队列迭代器失效,在经过一顿查阅后发现,是因为在C++中STL不支持线程安全,队列的push和pop同时进行会崩掉,一般说来,STL对于多线程的支持仅限于下列两点:(Effective STL中有描述)
1.多个读取者是安全的。即多个线程可以同时读取一个容器中的内容。 即此时多个线程调用 容器的不涉及到写的接口都可以 eg find, begin, end 等.
2.对不同容器的多个写入者是安全的。即多个线程对不同容器的同时写入合法。 但是对于同一容器当有线程写,有线程读时,如何保证正确? 需要程序员自己来控制,比如:线程A读容器某一项时,线程B正在移除该项。这会导致一下无法预知的错误。 通常的解决方式是用开销较小的临界区(CRITICAL_SECTION)来做同步。以下列方式同步基本上可以做到线程安全的容器(就是在有写操作的情况下仍能保证安全)。
但是在查阅后,我打算利用一个bool变量去标记队列中任务是否已经pop,来决定是否去push,还是崩了,原来多根线程也不允许同时push也不符合线程安全,那么将push加入互斥量解决了这个问题。
2》但是作为CPU来说,线程池是由任务的个数来创建线程数,这样才能最大利用的使用资源,这就像在餐馆里吃饭一样,CPU是老板,饭店里最多有5个服务员(实现创建的线程最大数),在店的有2个(创建的线程数),此时来了一个客人(任务),此时放走一个服务员去执行即可(释放信号量),此时来了4个客人,我把不在店的2个服务员给叫回来,此时来了10个客人,饭店里5个服务员都已经用完了,那么剩下5个就只能排队等待了,人数(任务)少时,服务员(线程)少,老板(CPU)就可以减少开支(资源分配)。那么这种方法作为代码就可以这样实现。
1 //1.是否有空闲线程 2 if(m_lRunThreadNum < m_lCreateThreadNum) 3 { 4 //释放一个信号量 5 ReleaseSemaphore(m_hSemphore,1,0); 6 } 7 //2.是否达到上限 8 else if(m_lCreateThreadNum < m_lMaxThreadNum) 9 { 10 //创建线程 并且释放一个信号量 11 HANDLE handle = (HANDLE)_beginthreadex(NULL,0,&ThreadFunction,this,0,0); 12 if(handle) 13 { 14 m_lHandle.push_back(handle); 15 } 16 m_lCreateThreadNum++; 17 ReleaseSemaphore(m_hSemphore,1,0); 18 } 19 //3.已达到上限 任务等待
3》在线程函数里,多个线程去执行任务时,难免会出现线程并发的情况,解决线程并发最常见的莫过于线程同步,也就是上锁,我列举一下常见的几种方式(如果有列举不当的,欢迎指出):
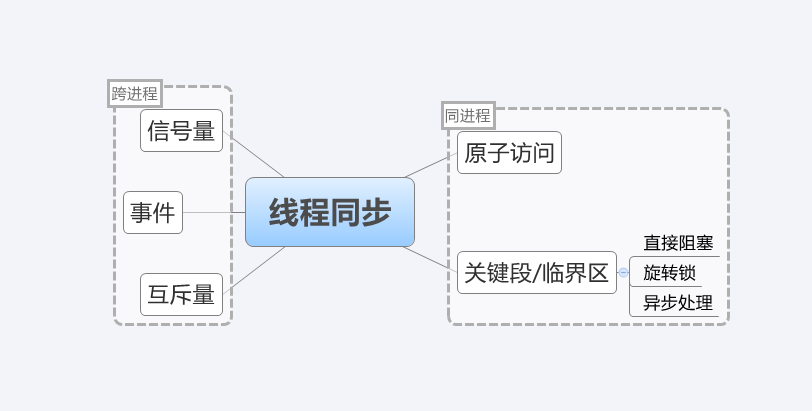
- 原子访问:同一时刻只允许一个线程访问资源,具体运用就是Interlocked...一系列函数,但是锁定范围小,一般就是一个变量,我认为它运用的主要核心就是Volatile关键字,因为CPU运算速度过快,需要一个Cache缓存来进行数据交换,而对于多线程来说,数据更改必须从内存中取用,而不是Cache,防止读内存不同步,比如变量a已经减1了,但此时两个线程中有一个线程读取的还是a,而不是内存中的a-1,这个关键字的作用就是防止编译优化,并且对于特殊地址的稳定访问。
- 关键段:同一个时刻只允许一个线程访问资源,举一个不雅观的例子,一群人上厕所,一个人进去后,将外面的牌子置为使用中,外面就有一群人在等待,当厕所里的人出来后,再将牌子置为未使用,在有一个人进入,这样就控制每一只有一个人(线程),上厕所(访问资源)了,而根据外面人等待时间的长短分为等不到就直接坐下来(其余线程直接阻塞),站着等一段时间,里面人出来了就直接进去,时间到了,里面人还没出来就直接阻塞(其余线程使用旋转锁),还有一种就是冲进来直接推门,能推开就进去,推不开就找另一个厕所(进程)(其余线程异步处理)
- 互斥量,事件和信号量:这三种都是内核对象,使用时很安全,并且作用范围广,可以跨进程进行通信,并且通过waitforsingleobject()等待信号的时间长短,都能实现关键段中三个方法,唯一的缺点就是相对于关键段来说执行效率慢,关键段是用户态下的方法,不需要状态转换
根据这几种方法,针对线程函数又加了一些锁
1 CMyThreadPool *pThis = (CMyThreadPool *)lpvoid; 2 CItask *pItask = NULL; 3 while(pThis->m_bFlagExit) 4 { 5 //等待信号量 6 if(WaitForSingleObject(pThis->m_hSemphore,100) == WAIT_TIMEOUT) //为了能让卡死进程能够退出 7 continue; 8 9 InterlockedIncrement(&pThis->m_lRunThreadNum); 10 while(!pThis->m_qItask.empty()) //由if->while 代码优化 11 { 12 if(WaitForSingleObject(pThis->m_lMutex,100) == WAIT_TIMEOUT) //上锁 13 continue; 14 if(pThis->m_qItask.empty()) 15 { 16 ReleaseMutex(pThis->m_lMutex); //解锁 17 break; 18 } 19 pItask = pThis->m_qItask.front(); 20 pThis->m_qItask.pop(); 21 //pThis->m_bIsPop = true; 22 ReleaseMutex(pThis->m_lMutex); //解锁 23 24 pItask->RunTask(); 25 delete pItask; 26 pItask = NULL; 27 } 28 InterlockedDecrement(&pThis->m_lRunThreadNum); 29 30 } 31 32 return 0;
4》在销毁时,能清空的都要清空,防止内存泄漏
1 m_bFlagExit = false; 2 list<HANDLE>::iterator ite = m_lHandle.begin(); 3 //auto ite = m_lHandle.begin(); 4 while(ite != m_lHandle.end()) 5 { 6 if(WaitForSingleObject(*ite,100) == WAIT_TIMEOUT) 7 TerminateThread(*ite,-1); 8 CloseHandle(*ite); 9 *ite = 0; 10 ite++; 11 } 12 m_lHandle.clear(); 13 m_lCreateThreadNum = 0; 14 CloseHandle(m_hSemphore); 15 m_hSemphore = 0; 16 17 while(!m_qItask.empty()) //防止内存泄漏,将任务清空 18 { 19 CItask *pItask = NULL; 20 pItask = m_qItask.front(); 21 m_qItask.pop(); 22 delete pItask; 23 pItask = NULL; 24 } 25 26 if(m_lMutex) //关闭互斥量 27 { 28 CloseHandle(m_lMutex); 29 m_lMutex = 0; 30 }
接下来在测试时就没有问题了,但是有点卡,并且CPU的运算率达到了100%,后来查阅博客https://blog.csdn.net/liuyancainiao/article/details/84400637资料,设置的线程数最多为CPU核数的两倍,假设计算机有一个物理CPU,是双核的,支持超线程。那么这台计算机就是双核四线程的。 所以两路(两路指的是有两个物理CPU)四核超线程就有2*4*2=16个逻辑CPU。有人也把它称之为16核,实际上在linux的/proc/cpuinfo中查看只有8核。既然计算机多核与超线程模拟相关,所以实际上计算机的核数翻倍并不意味着性能的翻倍,也不意味着核数越多计算机性能会越来越好,因为超线程只是充分利用了CPU的空闲资源,实际上在应用中基于很多原因,CPU的执行单元都没有被充分使用。 具体的代码 ,我放在文件共享,有需要的朋友可以直接拿走,不客气^_^