摘要:在本文中,我们提出了一种新的基于交叉一致性的语义分割半监督方法。 一致性训练已被证明是一种强大的半监督学习框架,用于在集群假设下利用未标记的数据,其中决策边界应位于低密度区域。 在这项工作中,我们首先观察到,对于语义分割,隐藏表示中的低密度区域比输入中的低密度区域更明显。 因此,我们提出了交叉一致性训练,其中在应用于编码器输出的不同扰动上强制执行预测的不变性。 具体来说,共享编码器和主解码器使用可用的标记示例以监督方式进行训练。 为了利用未标记的示例,我们强制主解码器预测与辅助解码器预测之间的一致性,将编码器输出的不同扰动版本作为输入,从而改进编码器的表示。
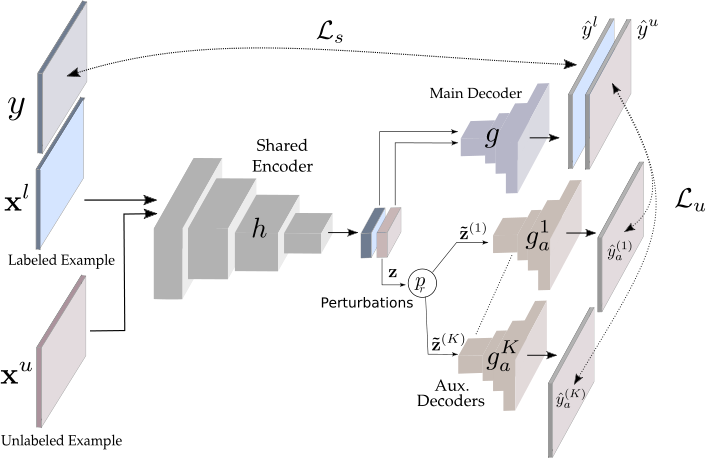
对于标记示例,编码器和主解码器以监督方式进行训练。 对于未标记的示例,在应用于辅助解码器输入的不同类型的扰动上,主解码器的预测与辅助解码器的预测之间的一致性被强制执行。