字面意思理解,self attention就是计算句子中每个单词的重要程度。
1. Structure
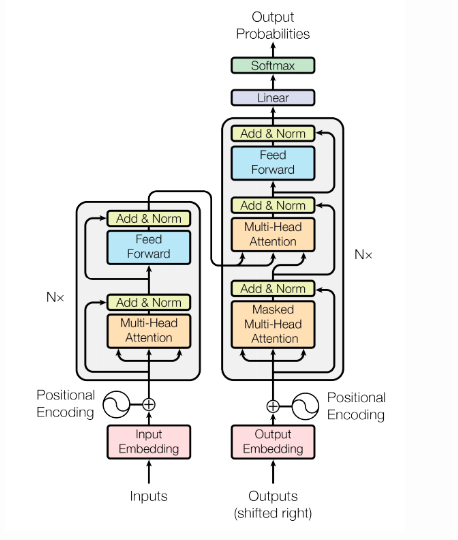
通过流程图,我们可以看出,首先要对输入数据做Embedding
1. 在编码层,输入的word-embedding就是key,value和query,然后做self-attention得到编码层的输出。这一步就模拟了图1中的编码层,输出就可以看成图1中的h。
2. 然后模拟图1中的解码层,解码层的关键是如何得到s,即用来和编码层做attention的query,我们发现,s与上个位置的真实label y,上个位置的s,和当前位置的attention输出c有关,换句话说,位置i的s利用了所有它之前的真实label y信息,和所有它之前位置的attention的输出c信息。label y信息我们全都是已知的,而之前位置的c信息虽然也可以利用,但是我们不能用,因为那样就又不能并行了(因为当前位置的c信息必须等它之前的c信息都计算出来)。于是我们只能用真实label y来模拟解码层的rnn。前面说过,当前位置s使用了它之前的所有真实label y信息。于是我们可以做一个masked attention,即对真实label y像编码层的x一样做self-attention,但每个位置的y只与它之前的y有关(mask),这样,self-attention之后每个位置的输出综合了当前位置和它之前位置的所有y信息,即可做为s(query)。
3. 得到编码层的key和value以及解码层的query后,下面就是模仿vanilla attention,利用key和value以及query再做最后一个attention。得到每个位置的输出。
总结起来就是,x做self-attention得到key和value,y做masked self-attention得到query,然后key,value,query做vanilla-attention得到最终输出。
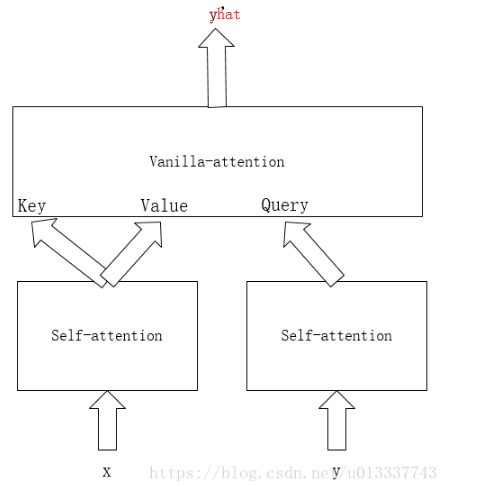
attention中计算Query和Key的相似度,相似度计算方法主要有4中:

2. position embedding
self-attention各个位置可以说是相互独立的,输出只是各个位置的信息加权输出,并没有考虑各个位置的位置信息。因此,Google提出一种pe算法:
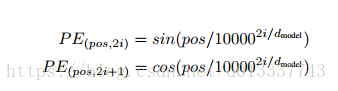
即在偶数位置,此word的pe是sin函数,在奇数位置,word的pe是cos函数。
论文说明了此pe和传统的训练得到的pe效果接近。并且因为 sin(α+β)=sinα cosβ+cosα sinβ 以及 cos(α+β)=cosα cosβ−sinα sinβ,位置 p+k 的向量可以用位置 p 的向量的线性变换表示,这也说明此pe不仅可以表示绝对位置,也能表示相对位置。
最后的embedding为word_embedding+position_embedding。
3. multi-head attention
首先embedding做h次linear projection,每个linear projection的参数不一样,然后做h次attention,最后把h次attention的结果拼接做为最后的输出。
多个attention便于模型学习不同子空间位置的特征表示,然后最终组合起来这些特征,而单头attention直接把这些特征平均,就减少了一些特征的表示可能。
4. Scaled Dot-Product
论文计算query和key相似度使用了dot-product attention,即query和key进行点乘(内积)来计算相似度。
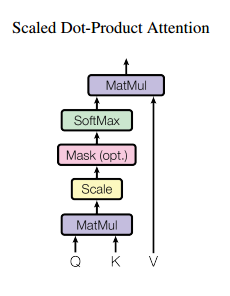
之所以用内积除以维度的开方,论文给出的解释是:假设Q和K都是独立的随机变量,满足均值为0,方差为1,则点乘后结果均值为0,方差为dk。也即方差会随维度dk的增大而增大,而大的方差导致极小的梯度(我认为大方差导致有的输出单元a(a是softmax的一个输出)很小,softmax反向传播梯度就很小(梯度和a有关))。为了避免这种大方差带来的训练问题,论文中用内积除以维度的开方,使之变为均值为0,方差为1。
5. Prediction
训练的时候我们知道全部真实label,但是预测时是不知道的。可以首先设置一个开始符s,然后把其他label的位置设为pad,然后对这个序列y做masked attention,因为其他位置设为了pad,所以attention只会用到第一个开始符s,然后用masked attention的第一个输出做为query和编码层的输出做普通attention,得到第一个预测的label y,然后把预测出的label加入到初始序列y中的相应位置,然后再做masked attention,这时第二个位置就不再是pad,那么attention层就会用到第二个位置的信息,依此循环,最后得到所有的预测label y。其实这样做也是为了模拟传统attention的解码层(当前位置只能用到前面位置的信息)。
Summary
self-attention层的好处是能够一步到位捕捉到全局的联系,解决了长距离依赖,因为它直接把序列两两比较(代价是计算量变为 O(n2),当然由于是纯矩阵运算,这个计算量相当也不是很严重),而且最重要的是可以进行并行计算。
相比之下,RNN 需要一步步递推才能捕捉到,并且对于长距离依赖很难捕捉。而 CNN 则需要通过层叠来扩大感受野,这是 Attention 层的明显优势。
self-attention其实和cnn,rnn一样,也是为了对输入进行编码,为了获得更多的信息。所以应把self-attention也看成网络中的一个层加进去。
Refrence
2. attention model–Neural machine translation by jointly learning to align and translate论文解读