一、Cookie
1、Cookie的由来
大家都知道HTTP协议是无状态的。
无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响,也不会直接影响后
面的请求响应情况。
一句有意思的话来描述就是人生只如初见,对服务器来说,每次的请求都是全新的。
状态可以理解为客户端和服务器在某次会话中产生的数据,那无状态的就以为这些数据不会被保留。会话中产生的数据又是我们需要保存的,也就是说要“保持状
态”。因此Cookie就是在这样一个场景下诞生。
2、什么是Cookie
Cookie具体指的是一段小信息,它是服务器发送出来存储在浏览器上的一组组键值对,下次访问服务器时浏览器会自动携带这些键值对,以便服务器提取有用信息。
3、Cookie的原理
Cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上Cookie,这样服务器就能通过Cookie的内容来判断这个是“谁”了。
4、查看Cookie
我们使用Chrome浏览器,打开开发者工具。

5、Django中操作Cookie
5.1、获取Cookie
request.COOKIES['key']
request.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None)
参数:
- default: 默认值
- salt: 加密盐
- max_age: 后台控制过期时间
5.2、设置Cookie
rep = HttpResponse(...)
rep = render(request, ...)
rep.set_cookie(key,value,...)
rep.set_signed_cookie(key,value,salt='加密盐',...)
参数:
- key, 键
- value='', 值
- max_age=None, 超时时间
- expires=None, 超时时间(IE requires expires, so set it if hasn't been already.)
- path='/', Cookie生效的路径,/ 表示根路径,特殊的:根路径的cookie可以被任何url的页面访问
- domain=None, Cookie生效的域名
- secure=False, https传输
- httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
5.3、删除Cookie
def logout(request):
rep = redirect("/login/")
rep.delete_cookie("user") # 删除用户浏览器上之前设置的user cookie值
return rep
Cookie版登陆校验:
from django.shortcuts import render, redirect
# Create your views here.
from functools import wraps
def check_login(func):
@wraps(func) # 装饰器修复技术
def inner(request, *args, **kwargs):
ret = request.get_signed_cookie("is_login", default="0", salt="s10nb")
if ret == "1":
# 已经登陆过的 继续执行
return func(request, *args, **kwargs)
# 没有登录过的 跳转到登录页面
else:
# 获取当前访问的URL
next_url = request.path_info
print(next_url)
return redirect("/login/?next={}".format(next_url))
return inner
def login(request):
print(request.get_full_path()) # 获取当前请求的路径和参数
print(request.path_info) # 取当前请求的路径
print("-" * 120)
if request.method == "POST":
user = request.POST.get("user")
pwd = request.POST.get("pwd")
# 从URL里面取到 next 参数
next_url = request.GET.get("next")
if user == "alex" and pwd == "dsb":
# 登陆成功
# 告诉浏览器保存一个键值对
if next_url:
rep = redirect(next_url) # 得到一个响应对象
else:
rep = redirect("/home/") # 得到一个响应对象
# rep.set_cookie("is_login", "1")
# 设置加盐的cookie
rep.set_signed_cookie("is_login", "1", salt="s10nb", max_age=10) # 单位是秒
return rep
return render(request, "login.html")
def home(request):
# 从请求的cookie中找 有没有 xiaohei
# ret = request.COOKIES.get("is_login", 0)
# 取加盐过的
ret = request.get_signed_cookie("is_login", default="0", salt="s10nb")
print(ret, type(ret))
if ret == "1":
# 表示已经登陆过
return render(request, "home.html")
else:
return redirect("/login/")
@check_login
def index(request):
return render(request, "index.html")
# 注销函数
def logout(request):
# 如何删除Cookie
rep = redirect("/login/")
rep.delete_cookie("is_login")
return rep
二、Session
1、Session的由来
Cookie虽然在一定程度上解决了“保持状态”的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是Session。
问题来了,基于HTTP协议的无状态特征,服务器根本就不知道访问者是“谁”。那么上述的Cookie就起到桥接的作用。
我们可以给每个客户端的Cookie分配一个唯一的id,这样用户在访问时,通过Cookie,服务器就知道来的人是“谁”。然后我们再根据不同的Cookie的id,在服务器上保存一段时间的私密资料,如“账号密码”等等。
总结而言:Cookie弥补了HTTP无状态的不足,让服务器知道来的人是“谁”;但是Cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过Cookie识别不同的用户,对应的在Session里保存私密的信息以及超过4096字节的文本。
另外,上述所说的Cookie和Session其实是共通性的东西,不限于语言和框架。
2、Django中Session相关方法
# 获取、设置、删除Session中数据
request.session['k1']
request.session.get('k1',None)
request.session['k1'] = 123
request.session.setdefault('k1',123) # 存在则不设置
del request.session['k1']
# 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
request.session.iterkeys()
request.session.itervalues()
request.session.iteritems()
# 会话session的key
request.session.session_key
# 将所有Session失效日期小于当前日期的数据删除
request.session.clear_expired()
# 检查会话session的key在数据库中是否存在
request.session.exists("session_key")
# 删除当前会话的所有Session数据
request.session.delete()
# 删除当前的会话数据并删除会话的Cookie。
request.session.flush()
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
3、Session流程解析
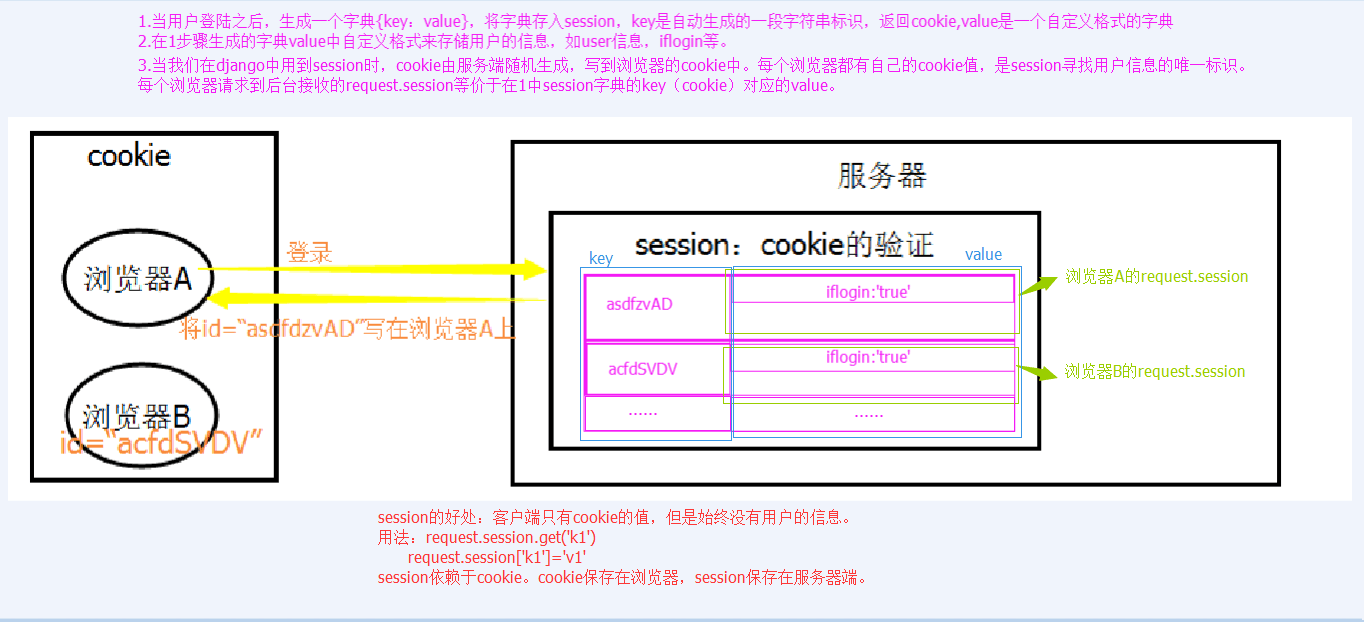
4、Session版登陆验证
from functools import wraps
def check_login(func):
@wraps(func)
def inner(request, *args, **kwargs):
next_url = request.get_full_path()
if request.session.get("user"):
return func(request, *args, **kwargs)
else:
return redirect("/login/?next={}".format(next_url))
return inner
def login(request):
if request.method == "POST":
user = request.POST.get("user")
pwd = request.POST.get("pwd")
if user == "alex" and pwd == "alex1234":
# 设置session
request.session["user"] = user
# 获取跳到登陆页面之前的URL
next_url = request.GET.get("next")
# 如果有,就跳转回登陆之前的URL
if next_url:
return redirect(next_url)
# 否则默认跳转到index页面
else:
return redirect("/index/")
return render(request, "login.html")
@check_login
def logout(request):
# 删除所有当前请求相关的session
request.session.delete()
return redirect("/login/")
@check_login
def index(request):
current_user = request.session.get("user", None)
return render(request, "index.html", {"user": current_user})
5、Django中的Session配置
Django中默认支持Session,其内部提供了5种类型的Session供开发者使用。
1. 数据库Session
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认)
2. 缓存Session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎
SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置
3. 文件Session
SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎
SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir()
4. 缓存+数据库
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎
5. 加密Cookie Session
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # 引擎
其他公用设置项:
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认)
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认)
SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认)
6、CBV中加装饰器相关
CBV实现的登录视图
class LoginView(View):
def get(self, request):
"""
处理GET请求
"""
return render(request, 'login.html')
def post(self, request):
"""
处理POST请求
"""
user = request.POST.get('user')
pwd = request.POST.get('pwd')
if user == 'alex' and pwd == "alex1234":
next_url = request.GET.get("next")
# 生成随机字符串
# 写浏览器cookie -> session_id: 随机字符串
# 写到服务端session:
# {
# "随机字符串": {'user':'alex'}
# }
request.session['user'] = user
if next_url:
return redirect(next_url)
else:
return redirect('/index/')
return render(request, 'login.html')
要在CBV视图中使用我们上面的check_login装饰器,有以下三种方式:
from django.utils.decorators import method_decorator
1. 加在CBV视图的get或post方法上
from django.utils.decorators import method_decorator
class HomeView(View):
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
@method_decorator(check_login)
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
2. 加在dispatch方法上
from django.utils.decorators import method_decorator
class HomeView(View):
@method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
因为CBV中首先执行的就是dispatch方法,所以这么写相当于给get和post方法都加上了登录校验。
3. 直接加在视图类上,但method_decorator必须传 name 关键字参数
如果get方法和post方法都需要登录校验的话就写两个装饰器。
from django.utils.decorators import method_decorator
@method_decorator(check_login, name="get")
@method_decorator(check_login, name="post")
class HomeView(View):
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
7、csrf_protect,csrf_exempt
CSRF Token相关装饰器在CBV只能加到dispatch方法上,或者加在视图类上然后name参数指定为dispatch方法。
备注:
- csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
- csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
from django.views.decorators.csrf import csrf_exempt, csrf_protect
from django.utils.decorators import method_decorator
class HomeView(View):
@method_decorator(csrf_exempt)
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
或者
from django.views.decorators.csrf import csrf_exempt, csrf_protect
from django.utils.decorators import method_decorator
@method_decorator(csrf_exempt, name='dispatch')
class HomeView(View):
def dispatch(self, request, *args, **kwargs):
return super(HomeView, self).dispatch(request, *args, **kwargs)
def get(self, request):
return render(request, "home.html")
def post(self, request):
print("Home View POST method...")
return redirect("/index/")
三、分页
1、自定义分页
终极封装版:
# !usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Author : YangLei (1912739092@qq.com)
@file : my_paging.py
@time : 2018/07/27
@Link : http://www.cnblogs.com/TuyereIOT/
@Version :
"""
class Paging():
def __init__(self, page_num, total_count, url_prefix, per_page=10, max_page=11):
"""
根据 bootstrap4 定制的分页组件
:param page_num: 当前页码数
:param total_count: 数据总数
:param url_prefix: a标签href的前缀
:param per_page: 每页显示多少条数据
:param max_page: 页面上最多显示几个页码
"""
self.url_prefix = url_prefix
self.max_page = max_page
# 每一页显示多少条数据
# 总共需要多少页码来展示
total_page, m = divmod(total_count, per_page)
if m:
total_page += 1
self.total_page = total_page
try:
page_num = int(page_num)
# 如果输入的页码数超过了最大的页码数,默认返回最后一页
if page_num > total_page:
page_num = total_page
except Exception as e:
# 当输入的页码不是正经数字的时候 默认返回第一页的数据
page_num = 1
self.page_num = page_num
# 定义两个变量保存数据从哪儿取到哪儿
self.data_start = (page_num - 1) * 10
self.data_end = page_num * 10
# 页面上总共展示多少页码
if total_page < self.max_page:
self.max_page = total_page
half_max_page = self.max_page // 2
# 页面上展示的页码从哪儿开始
page_start = page_num - half_max_page
# 页面上展示的页码到哪儿结束
page_end = page_num + half_max_page
# 如果当前页减一半 比1还小
if page_start <= 1:
page_start = 1
page_end = self.max_page
# 如果 当前页 加 一半 比总页码数还大
if page_end >= total_page:
page_end = total_page
page_start = total_page - self.max_page + 1
self.page_start = page_start
self.page_end = page_end
@property
def start(self):
return self.data_start
@property
def end(self):
return self.data_end
def page_html(self):
# 自己拼接分页的HTML代码
html_str_list = []
# 加上第一页
html_str_list.append(
'<li class="page-item"><a class="page-link" href="{}?page=1">首页</a></li>'.format(self.url_prefix))
# 判断一下 如果是第一页,就没有上一页
if self.page_num <= 1:
html_str_list.append(
'<li class="disabled page-item"><a class="page-link" href="#"><span aria-hidden="true">«</span></a></li>'.format(
self.page_num - 1))
else:
# 加一个上一页的标签
html_str_list.append(
'<li class="page-item"><a class="page-link" href="{}?page={}"><span aria-hidden="true">«</span></a></li>'.format(
self.url_prefix,
self.page_num - 1))
for i in range(self.page_start, self.page_end + 1):
# 如果是当前页就加一个active样式类
if i == self.page_num:
tmp = '<li class="active page-item"><a class="page-link" href="{0}?page={1}">{1}</a></li>'.format(
self.url_prefix, i)
else:
tmp = '<li class="page-item"><a class="page-link" href="{0}?page={1}">{1}</a></li>'.format(
self.url_prefix, i)
html_str_list.append(tmp)
# 加一个下一页的按钮
# 判断,如果是最后一页,就没有下一页
if self.page_num >= self.total_page:
html_str_list.append(
'<li class="disabled page-item"><a class="page-link" href="#"><span aria-hidden="true">»</span></a></li>')
else:
html_str_list.append(
'<li class="page-item"><a class="page-link" href="{}?page={}"><span aria-hidden="true">»</span></a></li>'.format(
self.url_prefix,
self.page_num + 1))
# 加最后一页
html_str_list.append(
'<li class="page-item"><a class="page-link" href="{}?page={}">尾页</a></li>'.format(self.url_prefix,
self.total_page))
page_html = "".join(html_str_list)
return page_html
使用:
def books(request):
# 获取页码数
page_num = request.GET.get("page")
# 获取总数据量
total_count = models.Book.objects.all().count()
# 调用分页类
from utils.my_paging import Paging
page_obj = Paging(page_num, total_count, url_prefix="/books/", max_page=7)
# 将数据切片
ret = models.Book.objects.all()[page_obj.start:page_obj.end]
# 自己拼接分页HTML代码
page_html = page_obj.page_html()
return render(request, "app02_session/books.html", {"books": ret, "page_html": page_html})
2、Django内置分页
View.py
from django.shortcuts import render
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger
L = []
for i in range(999):
L.append(i)
def index(request):
current_page = request.GET.get('p')
paginator = Paginator(L, 10)
# per_page: 每页显示条目数量
# count: 数据总个数
# num_pages:总页数
# page_range:总页数的索引范围,如: (1,10),(1,200)
# page: page对象
try:
posts = paginator.page(current_page)
# has_next 是否有下一页
# next_page_number 下一页页码
# has_previous 是否有上一页
# previous_page_number 上一页页码
# object_list 分页之后的数据列表
# number 当前页
# paginator paginator对象
except PageNotAnInteger:
posts = paginator.page(1)
except EmptyPage:
posts = paginator.page(paginator.num_pages)
return render(request, 'index.html', {'posts': posts})
html部分
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
{% for item in posts %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<div class="pagination">
<span class="step-links">
{% if posts.has_previous %}
<a href="?p={{ posts.previous_page_number }}">Previous</a>
{% endif %}
<span class="current">
Page {{ posts.number }} of {{ posts.paginator.num_pages }}.
</span>
{% if posts.has_next %}
<a href="?p={{ posts.next_page_number }}">Next</a>
{% endif %}
</span>
</div>
</body>
</html>