基础知识储备:
导入常用python package
导入文章content,导入停用词表
使用jieba对content内容分词
创建函数去除content中的停用词(注意格式的不同 dataframe, series, list)
统计词频:使用词云画图
创建词云展示
使用IF-IDF提取关键字
构建LDA主题模型
import pandas as pd
import jieba
import numpy
df_news = pd.read_table('val.txt',names = ['category','theme','URL','content'],encoding='utf-8')
#过滤缺失数据
df_news = df_news.dropna()
df_news.head()
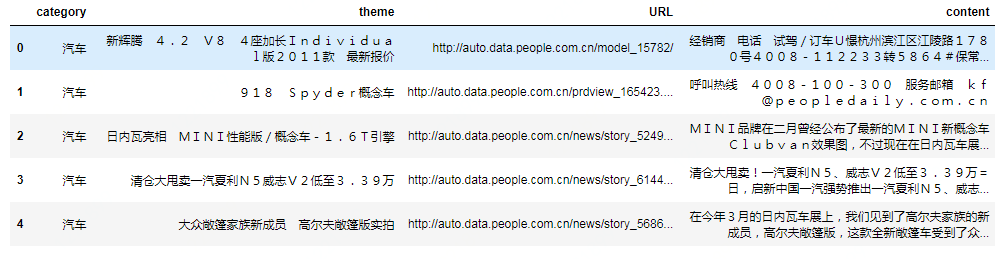
df_news.shape
content = df_news.content.values.tolist()
print(content[1001])
#查看第1001条新闻信息

#对内容分词处理
content_S = []
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != '
': #换行符
content_S.append(current_segment)
content_S[1000]#分词
#分词后的内容,存在停用词,需要做处理
df_content = pd.DataFrame({'content_S':content_S})
df_content.head()

#停用词处理
stopwords = pd.read_csv("stopwords.txt",index_col = False,sep=" ",quoting=3,names=['stopword'], encoding='utf-8')
stopwords.head(20)
#对文本数据的停用词做清洗
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))#清洗后所有词
contents_clean.append(line_clean)#清洗后的文本
return contents_clean,all_words
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head()

#统计所有词
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()
#统计每个词的词频,并按从高到低排列
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({"count":numpy.size})
words_count=words_count.reset_index().sort_values(by=["count"],ascending=False)
words_count.head()

#制作云图可视化词频统计,这里自定义了一个模型
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
wordcloud = WordCloud("simhei.ttf",)
from wordcloud import WordCloud
fontpath='simhei.ttf'
import numpy as np
from PIL import Image
aimask=np.array(Image.open("AI.png"))
wc = WordCloud(font_path=fontpath, # 设置字体
background_color="white", # 背景颜色
max_words=1000, # 词云显示的最大词数
max_font_size=100, # 字体最大值
min_font_size=10, #字体最小值
random_state=42, #随机数
collocations=False, #避免重复单词
mask=aimask, #造型遮盖
width=1200,height=800,margin=2, #图像宽高,字间距,需要配合下面的plt.figure(dpi=xx)放缩才有效
)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values}
word_cloud=wc.fit_words(word_frequence)
plt.figure(dpi=100) #通过这里可以放大或缩小
plt.axis("off") #隐藏坐标
plt.imshow(word_cloud)

#提取关键字 这里只提取了五个 topk=5 ,随便拿了一篇
import jieba.analyse
index = 2400
print (df_news['content'][index])
content_S_str = "".join(content_S[index])
print (" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))

#关键字

#LDA :主题模型
from gensim import corpora, models, similarities
import gensim
#http://radimrehurek.com/gensim/
#做映射,相当于词袋
dictionary = corpora.Dictionary(contents_clean)
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10) #类似Kmeans自己指定K值
#一号分类结果
print (lda.print_topic(1, topn=5))
0.006*"中" + 0.005*"比赛" + 0.003*"说" + 0.002*"该剧" + 0.002*"考生"
#分10堆主题
for topic in lda.print_topics(num_topics=10, num_words=5):
print (topic[1])
0.007*"电影" + 0.007*"中" + 0.006*"中国" + 0.005*"观众" + 0.004*"导演" 0.006*"中" + 0.005*"比赛" + 0.003*"说" + 0.002*"该剧" + 0.002*"考生" 0.005*"中" + 0.003*"皮肤" + 0.003*"肌肤" + 0.003*"V" + 0.003*"食物" 0.006*"中国" + 0.004*"中" + 0.002*"市场" + 0.002*"发展" + 0.002*"文化" 0.006*"中" + 0.005*"说" + 0.003*"男人" + 0.003*"女人" + 0.002*"学校" 0.016*"a" + 0.015*"e" + 0.011*"n" + 0.011*"o" + 0.011*"i" 0.004*"中" + 0.003*"B" + 0.002*"天籁" + 0.002*"球队" + 0.002*"C" 0.004*"中" + 0.004*"节目" + 0.003*"男人" + 0.003*"万" + 0.003*"公司" 0.009*"男人" + 0.005*"中" + 0.005*"女人" + 0.004*"P" + 0.003*"S" 0.005*"说" + 0.005*"中" + 0.004*"孩子" + 0.003*"中国" + 0.002*"做"
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
df_train.tail()
#这里显示最后的5条

#已有新闻类别
df_train.label.unique()
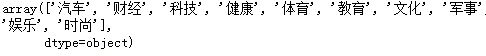
#将类别做数值转换
label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
df_train['label'] = df_train['label'].map(label_mapping)
df_train.head()

#重点!!! 建立模型一样分训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values, random_state=1)
#x_train[0][1]
words = []
for line_index in range(len(x_train)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
words.append(' '.join(x_train[line_index]))
except:
print (line_index,word_index)
words[1000]

from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
vec.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(words), y_train)
test_words = []
for line_index in range(len(x_test)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
test_words.append(' '.join(x_test[line_index]))
except:
print (line_index,word_index)
test_words[40]
classifier.score(vec.transform(test_words), y_test)
#不做TF-IDF的准确率稍低
‘’‘
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序’
‘’‘’
0.804
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False)
vectorizer.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vectorizer.transform(words), y_train)
#这里发现使用贝叶斯逆概 TF-IDF 精确度达到了81.52%
classifier.score(vectorizer.transform(test_words), y_test)
0.8152