在Yarn框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用可以在同一时间有条不紊的工作。最原始的调度规则就是FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待。也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。所以FIFO虽然很简单,但是并不能满足我们的需求。
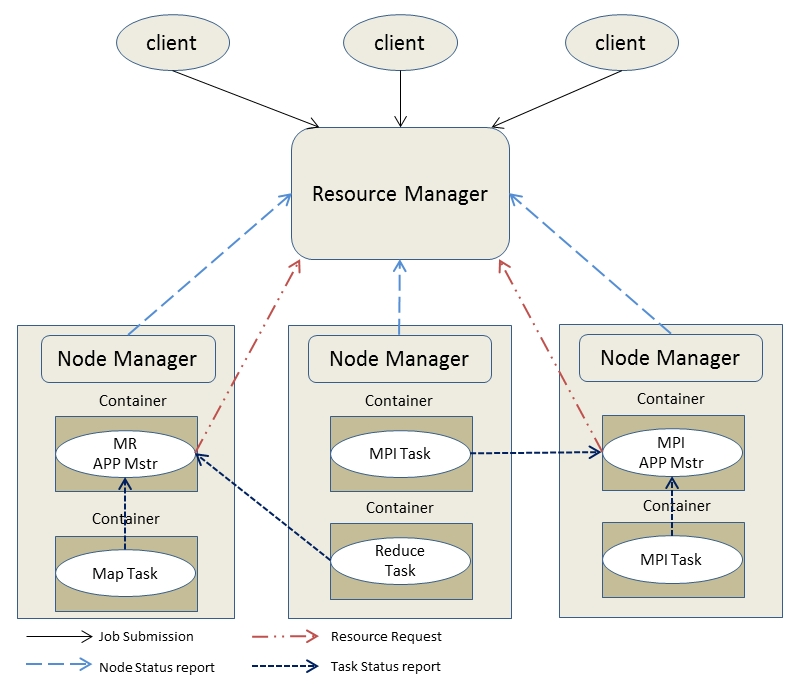
yarn默认还提供了两种调度规则,capacity和fair share。本篇就主要介绍下capacity调度器:
1.什么是capacity调度器?
Capacity调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。比如我大体上把整个集群分成了AB两个队列,A队列给A项目组的人来使用。B队列给B项目组来使用。但是A项目组下面又有两个方向,那么还可以继续分,比如专门做BI的和做实时分析的。那么队列的分配就可以参考下面的树形结构:
root
------a[60%]
|---a.bi[40%]
|---a.realtime[60%]
------b[40%]
a队列占用整个资源的60%,b队列占用整个资源的40%。a队列里面又分了两个子队列,一样也是2:3分配。
虽然有了这样的资源分配,但是并不是说a提交了任务,它就只能使用60%的资源,那40%就空闲着。只要资源实在空闲状态,那么a就可以使用100%的资源。但是一旦b提交了任务,a就需要在释放资源后,把资源还给b队列,直到ab平衡在3:2的比例。
粗粒度上资源是按照上面的方式进行,在每个队列的内部,还是按照FIFO的原则来分配资源的。
2.特性
capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
- 安全,每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
- 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
3.关于调度器的配置
(1)配置调度器
在ResourceManager中配置它要使用的调度器,配置方式是修改conf/yarn-site.xml,设置属性:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
(2)配置队列
调度器的核心就是队列的分配和使用了,修改conf/capacity-scheduler.xml可以配置队列。
Capacity调度器默认有一个预定义的队列——root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用.来进行分割,比如yarn.scheduler.capacity.<queue-path>.queues.
下面是配置的样例,比如root下面有三个子队列:
<configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hadoop,orc</value> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>0</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.capacity</name> <value>65</value> </property> <property> <name>yarn.scheduler.capacity.root.orc.capacity</name> <value>35</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.user-limit-factor</name> <value>1</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <property> <name>yarn.scheduler.capacity.root.orc.user-limit-factor</name> <value>1</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <property> <name>yarn.scheduler.capacity.root.orc.maximum-capacity</name> <value>100</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.maximum-capacity</name> <value>100</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>default</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.acl_submit_applications</name> <value>hadoop</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.acl_administer_queue</name> <value>hadoop</value> </property> </configuration>
(3)队列属性
- yarn.scheduler.capacity..capacity
它是队列的资源容量占比(百分比)。系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是100%。
- yarn.scheduler.capacity..maximum-capacity
队列资源的使用上限。由于系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是-1,即禁用。
- yarn.scheduler.capacity..minimum-user-limit-percent
每个任务占用的最少资源。比如,你设置成了25%。那么如果有两个用户提交任务,那么每个任务资源不超过50%。如果3个用户提交任务,那么每个任务资源不超过33%。如果4个用户提交任务,那么每个任务资源不超过25%。如果5个用户提交任务,那么第五个用户需要等待才能提交。默认是100,即不去做限制。说白了就是应用程序在运行的时候最小分配资源。
- yarn.scheduler.capacity..user-limit-factor (配置弹性队列)
每个用户最多使用的队列资源占比,默认值是1,当设置为1的时候,表示该应用程序最多获取的资源就是当前队列分配的资源,哪怕集群中还有其他的队列资源空闲,也不会占用。如果需要使当前队列中的应用程序沾用其他队列的资源,那么该值需要设置为大于1,例如:当前队列占用集群资源的比例为40%,如果设置这个参数的值为2,我个人的理解是这个时候,该队列可以使用其他队列%40的资源,也就是当前队列 * 这个限制因子,达到集群的80%。然而有的资料说的是这个值是多少,就占用集群的多少资源,比如设置50,那么久占用集群资源的50%(个人感觉不对),在实际的运用中,比如我有一个test队列,这个队列分配为集群资源的40,那么,当我设置这个值为3的时候,表明可以使用集群的120%(虽然达不到120%)的资源,通过yarn的web UI界面发现确实是可以达到集群资源的100%,说明这是一个因子数,如果按其他资料说的是配置大于1的数,那么上述的配置只能占用集群资源的3%了,连自己本身队列的资源都占不满。
-
yarn.scheduler.capacity.root.hadoop.maximum-capacity
队列可以使用的集群最大资源占比,这个值是依赖于上诉的用户限制因子的。比如:hadoop这个队列配置为40(占用集群资源的40%),user-limit-factor(配置为3),按理来说这个时候这个hadoop队列可以使用整个集群的资源,但是如果maximun-capacity这个参数的值为80,那么改队列也不能沾满整个集群资源,相当于牺牲弹性队列为代价了。所以在配置集群资源的时候,需要找到一个合适的配置。
(4)运行和提交应用限制
- yarn.scheduler.capacity.maximum-applications / yarn.scheduler.capacity..maximum-applications
设置系统中可以同时运行和等待的应用数量。默认是10000.
- yarn.scheduler.capacity.maximum-am-resource-percent / yarn.scheduler.capacity..maximum-am-resource-percent
设置有多少资源可以用来运行app master,即控制当前激活状态的应用。默认是10%。
(5)队列管理
- yarn.scheduler.capacity..state
队列的状态,可以使RUNNING或者STOPPED.如果队列是STOPPED状态,那么新应用不会提交到该队列或者子队列。同样,如果root被设置成STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭。
- yarn.scheduler.capacity.root..acl_submit_applications
访问控制列表ACL控制谁可以向该队列提交任务。如果一个用户可以向该队列提交,那么也可以提交任务到它的子队列。
- yarn.scheduler.capacity.root..acl_administer_queue
设置队列的管理员的ACL控制,管理员可以控制队列的所有应用程序。同样,它也具有继承性。
注意:ACL的设置是user1,user2 group1,group2这种格式。如果是*则代表任何人。空格表示任何人都不允许。默认是*.
(6)其他属性
- yarn.scheduler.capacity.resource-calculator
资源计算方法,默认是org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和CPU。
- yarn.scheduler.capacity.node-locality-delay (延迟调度)
调度器尝试进行调度的次数。一般都是跟集群的节点数量有关。默认40(一个机架上的节点数)。白话将就是在启动启动的时候,如果这个容器启动在某个节点,可以直接从这个容器节点读取数据,那么这种就是数据本地化,但是在一个繁忙的集群上,可能当前这个nodemanager已经没有资源来启动容器了(默认情况,nodemanager会一秒钟像rm发送心跳信息,信息中包含了当前nodemanager当前运行的任务以及资源剩余情况),但是可以在其他的nodemanager启动这个容器。这个时候就可以配置延迟调度。所谓的延迟调度就是延迟多久以后被调度到其他的nodemanager上,如果还没超过这个配置的值,当前的节点以及用资源启动容器了,那么rm会在当前节点启动容器,这就是延迟调度,说白了,就是为了利用数据的本地化。
一旦设置完这些队列属性,就可以在web ui上看到了。可以访问下面的连接:
xxx:8088/scheduler4.修改队列配置
如果想要修改队列或者调度器的配置,可以修改
vi $HADOOP_CONF_DIR/capacity-scheduler.xml修改完成后,需要执行下面的命令:
$HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues注意:
- 队列不能被删除,只能新增。
- 更新队列的配置需要是有效的值
- 同层级的队列容量限制想加需要等于100%。