HDP version: 3.x
1、hive执行sql慢
- 执行sql
hive通过Tez引擎执行如下的sql语句:
insert overwrite select ....
整个执行过程消耗十分钟左右,平时任务2-3分钟可以完成,可以明显看到,任务调度出现问题了。
- 分析
上述的sql语句对应两个mapreduce,分别是查询数据的和插入数据的mapreduce,执行插入数据是使用的distcp的方式。
通过对日志的分析:
查询数据(select) 消耗4分钟左右。
插入数据(distcp) 消耗6分钟,平时这个阶段一分钟左右就能完成,但是这次居然多消耗了五分钟。
distcp其实在一分钟之内,map已经运行到100%,但是执行的容器或者任务居然一直卡了五分钟之久,如果是一个任务可能还是偶发性的,但是大量任务都出现这个问题,那说明集群应该是异常了。
- 查看distcp任务对应的mapreduce日志信息:
满屏的异步调度waitting。
接着往下看应用程序日志
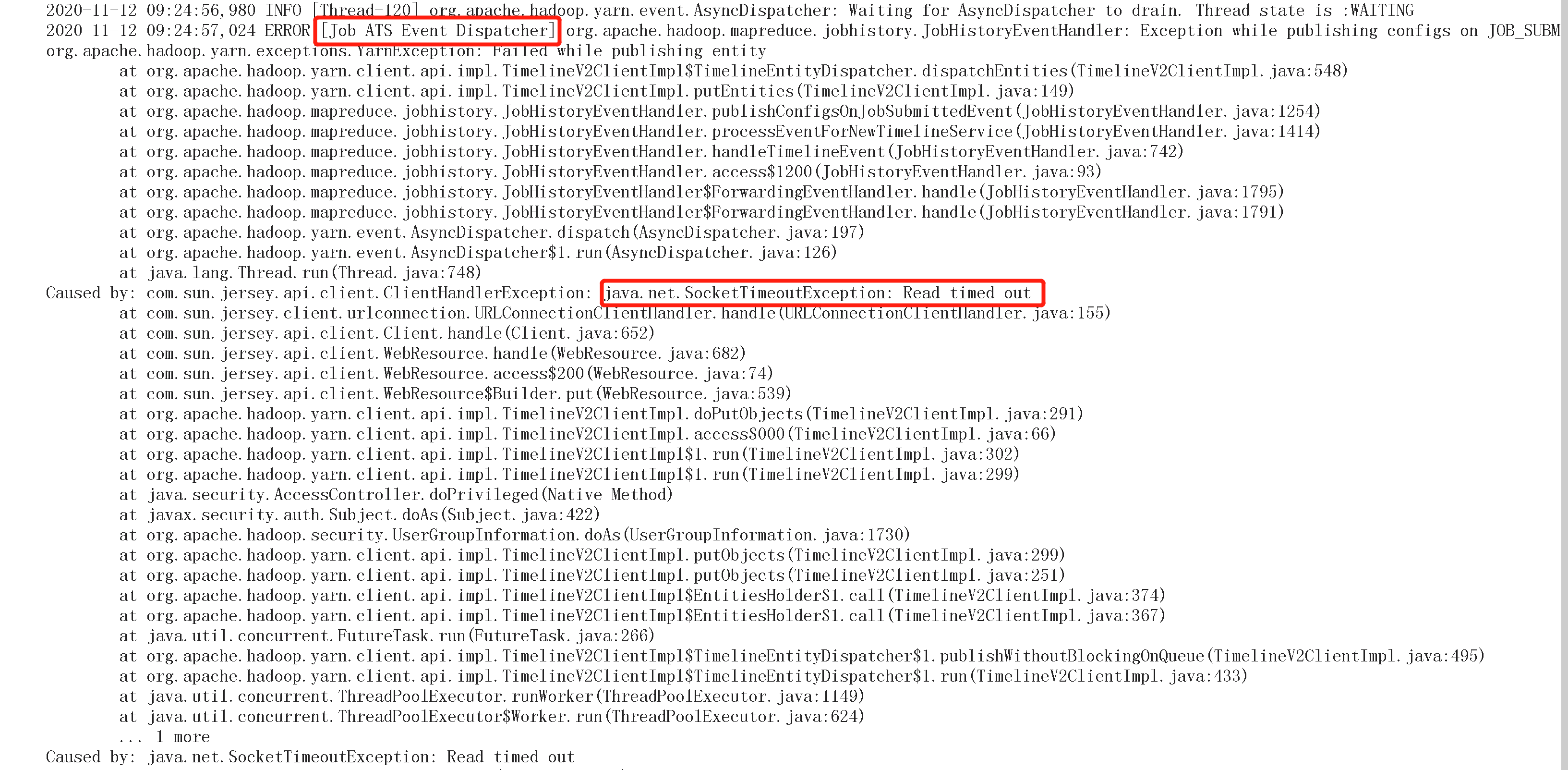
可以看到sockettimeout 异常,fa发生这个异常的线程是ATS事件。
- 解决
发生这种情况是因为来自ATSv2的嵌入式HBASE崩溃。
解决这个问题的方法需要重置ATsv2内嵌HBASE数据库(当然也可能是外部的hbase集群)
解决方式1:
我这边的问题是单节点的hbase,regionserver由于内存分配太低,导致内存崩溃,进程退出
修改hbase-env.sh 增加对应的内存大小,重启服务
解决方式2:
停止yarn
Ambari -> Yarn-Actions -> Stop
删除Zookeeper上的ATSv2 Znode
rmr /atsv2-hbase-unsecure或rmr /atsv2-hbase-secure(如果是kerberized集群)
删除hbase的数据存储目录
hdfs dfs -mv /atsv2/hbase/tmp/
启动yarn
Ambari - > Yarn-Actions- > Start