接上篇继续 ,这回看下一些常用的操作:
一、join 联表查询
有数据库开发经验的同学,一定对sql中的join ... on 联表查询不陌生,pandas也有类似操作
假设test.xlsx的sheet1, sheet2中分别有下面的数据(相当于2张表)
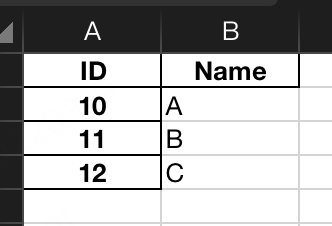
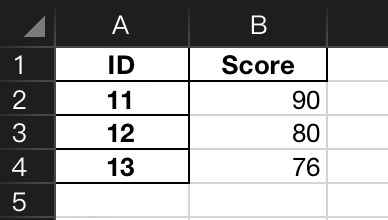
现在要以ID做为作为Key,将二张表join起来,可以这样写:
import pandas as pd
pd1 = pd.read_excel("./data/test.xlsx", sheet_name="sheet1", index_col="ID")
pd2 = pd.read_excel("./data/test.xlsx", sheet_name="sheet2", index_col="ID")
print("-----pd1--------")
print(pd1)
print("\n-----pd2--------")
print(pd2)
print("\n------default-------")
pd3 = pd1.join(pd2)
print(pd3)
print("\n------left-------")
pd3 = pd1.join(pd2, how="left")
print(pd3)
print("\n------right-------")
pd3 = pd1.join(pd2, how="right")
print(pd3)
print("\n------inner-------")
pd3 = pd1.join(pd2, how="inner")
print(pd3)
print("\n------outer-------")
pd3 = pd1.join(pd2, how="outer")
print(pd3)
输出:
-----pd1--------
Name
ID
10 A
11 B
12 C
-----pd2--------
Score
ID
11 90
12 80
13 76
------default-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0
------left-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0
------right-------
Name Score
ID
11 B 90
12 C 80
13 NaN 76
------inner-------
Name Score
ID
11 B 90
12 C 80
------outer-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0
13 NaN 76.0
是不是跟sql几乎一模一样?如果2个表格中的Key,名称不一样,比如第2个表格长这样,第1列不叫ID,而是stutent_id
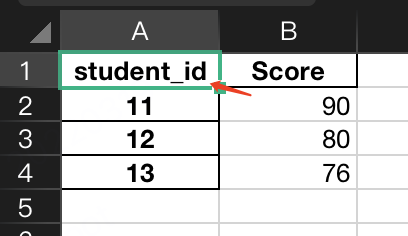
也不影响,只要在读取时设置了索引即可,默认join时就是用index列做为key关联
二、groupby分组统计
假设有一张表:
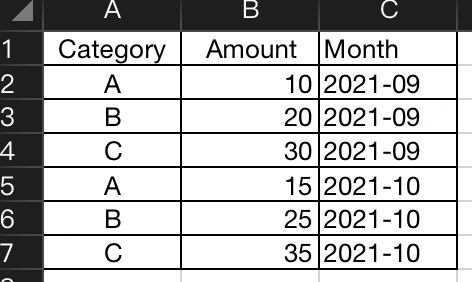
想按月汇总下Amount的总和,直接使用groupby("Month")
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
df_month = df.groupby("Month").sum()
print(df_month)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Month
2021-09 60
2021-10 75
来个更复杂的,希望按Category看看,在本月当中该Category的Amount占"当月Amount总和"的占比,比如2021-09月,Amount总和为60,而9月之中,C类的Amount=30,即9月C类的Amount占9月总Amount的50%
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
df_month = df.groupby("Month").sum()
print(df_month)
print("------------")
# 插入2列
df.insert(2, 'MonthTotal', 0)
df.insert(3, 'MonthPercent', 0.0)
# 计算每个月,各Category的Amount占比
for idx2, data2 in df_month.iterrows():
for idx, data in df.iterrows():
if idx2 == data["Month"]:
data["MonthTotal"] = data2["Amount"]
data["MonthPercent"] = data["Amount"] / data2["Amount"]
df.iloc[idx] = pd.Series(data)
df["MonthPercent"] = df["MonthPercent"].apply(lambda x: format(x, '.2%'))
print(df)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Month
2021-09 60
2021-10 75
------------
Category Amount MonthTotal MonthPercent Month
0 A 10 60 16.67% 2021-09
1 B 20 60 33.33% 2021-09
2 C 30 60 50.00% 2021-09
3 A 15 75 20.00% 2021-10
4 B 25 75 33.33% 2021-10
5 C 35 75 46.67% 2021-10
除了分组求和,当然还能求平均值,以及分组计算count
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
category_amount_avg = df.groupby("Category").mean()
print(category_amount_avg)
print("------------")
category_count = df.groupby("Month").count()
print(category_count)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Category
A 12.5
B 22.5
C 32.5
------------
Category Amount
Month
2021-09 3 3
2021-10 3 3
三、sort排序
还是这张表,如果希望按Amount降序排列,可以这样:
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print("-----before sort------")
print(df)
print("-----after sort------")
df.sort_values("Amount", inplace=True, ascending=False)
print(df)
输出:
-----before sort------ Category Amount Month 0 A 10 2021-09 1 B 20 2021-09 2 C 30 2021-09 3 A 15 2021-10 4 B 25 2021-10 5 C 35 2021-10 -----after sort------ Category Amount Month 5 C 35 2021-10 2 C 30 2021-09 4 B 25 2021-10 1 B 20 2021-09 3 A 15 2021-10 0 A 10 2021-09
如果需要多个字段排序 ,比如:先按Month升序,再按Amount降序
print("-----after sort------")
df.sort_values(by=["Month", "Amount"], ascending=[True, False], inplace=True)
print(df)
输出:
-----after sort------ Category Amount Month 2 C 30 2021-09 1 B 20 2021-09 0 A 10 2021-09 5 C 35 2021-10 4 B 25 2021-10 3 A 15 2021-10
四、行列转换
pandas有一个内置的transpose()方法,可以直接实现:
import pandas as pd
df = pd.read_excel("./data/test.xlsx", index_col="Category")
print("------行转列(前)----------")
print(df)
print("------行转列(后)----------")
print(df.transpose())
输出:
------行转列(前)----------
Amount Month
Category
A 10 2021-09
B 20 2021-09
C 30 2021-09
A 15 2021-10
B 25 2021-10
C 35 2021-10
------行转列(后)----------
Category A B C A B C
Amount 10 20 30 15 25 35
Month 2021-09 2021-09 2021-09 2021-10 2021-10 2021-10
不过这个转换功能有点简单,如果要实现一些个性化的行列转换,比如希望达到下面的效果:
2021-09 2021-10 Category A 10 15 B 20 25 C 30 35
就得自己写代码了,参考下面:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("./data/test.xlsx")
print("-------before-------")
df.set_index("Month", inplace=True)
print(df)
print("-------after-------")
# 先对Month求distinct
months = df.index.unique()
rows = []
for month in months:
# 遍历df
for idx, data in df.iterrows():
if idx == month:
# 生成新DataFrame中的每一行
row = pd.Series({"Category": data.Category, month: data.Amount})
found = 0
for d in rows:
# 如果该分类的行存在,则填充缺的月份列
if d.Category == data.Category:
found = 1
d[month] = data.Amount
# 如果该分类的行不存在,直接放入rows数列
if found == 0:
rows.append(row)
# 构造新的DataFrame
df_output = pd.DataFrame(rows)
df_output.set_index("Category", inplace=True)
print(df_output)
参考:
1、官网 pandas.DataFrame.join 文档
2、官网 pandas.DataFrame.groupby 文档