接上篇继续,本篇演示对excel的基本增删改查操作。
一、读取excel
1.1 常规读取
假设有以下excel文件: 002.xlsx

用pandas可以这样读取:
import pandas as pd
df = pd.read_excel("data/002.xlsx")
print(df.shape)
print(df.columns)
print(df)
显示如下:
(6, 2) Index(['id', 'name'], dtype='object') id name 0 1 A 1 2 B 2 3 C 3 4 D 4 5 E 5 6 F
解释:
第1行输出(6,2),表示这是6行2列
第2行输出的是列信息,表示有id, name这2列,都是object类型
第3行输出的就是表格数据,注意最左没有列名的这列,从0到5,如果做过数据库开发的同学,应该都知道:数据表内部通常会有一个唯一键,也称为主键索引。pandas读取的excel,如果没有指定索引,默认会按数字顺序,生成1个默认的索引,即上面的0-5。
如果在读取时,微调一下,指定索引列:
df = pd.read_excel("data/002.xlsx", index_col="id")
输出就变成了下面这样:
(6, 1) Index(['name'], dtype='object') name id 1 A 2 B 3 C 4 D 5 E 6 F
可以看到id变成了现在的索引列,但是要注意一点:pandas里的索引列,跟数据库表中的主键索引,还是有不同的,它允许重复! 感兴趣的同学,可以把这个excel文件的id列,找2行,改成相同的值,比如下面这样:

还是刚才的代码,输出如下:
(6, 1) Index(['name'], dtype='object') name id 1 A 2 B 3 C 4 D 5 E 5 F
1.2 无标题行的excel读取
有时候,可能拿到的excel,没有title,只有数据,比如这样:
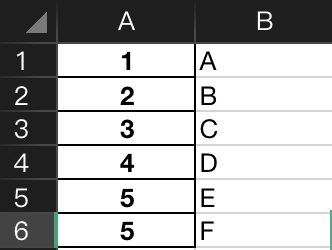
import pandas as pd
df = pd.read_excel("data/002.xlsx")
print(df)
这时候,读出来是这样:
1 A 0 2 B 1 3 C 2 4 D 3 5 E 4 5 F
第1行数据会误认为是title,可以加上header=None
import pandas as pd
df = pd.read_excel("data/002.xlsx", header=None)
print(df)
这样就正常了:
0 1 0 1 A 1 2 B 2 3 C 3 4 D 4 5 E 5 5 F
1.3 左侧与上边有空行的读取
再来看一种特殊情况:数据左边和上边都有空行
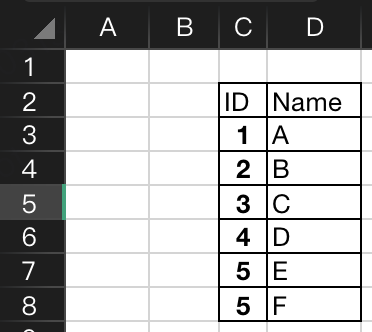
同样可以加一些参数 skiprows=1 , usecols="C:D"表示跳过1行,列从C至D
import pandas as pd
df = pd.read_excel("data/002.xlsx", skiprows=1, usecols="C:D", index_col="ID")
print(df)
1.4 多Sheet的读取
假设excel文件,有下面2个Sheet
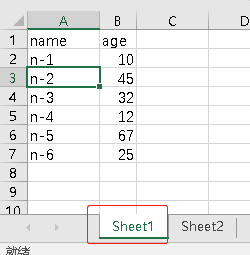
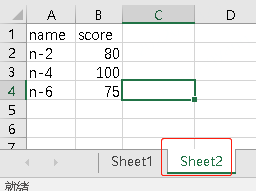
可以通过sheet_name=xxx来指定读取
import pandas as pd
df1 = pd.read_excel("./data/test.xlsx", sheet_name="Sheet1")
df2 = pd.read_excel("./data/test.xlsx", sheet_name="Sheet2")
print(df1)
print("----------------------")
print(df2)
输出:
name age 0 n-1 10 1 n-2 45 2 n-3 32 3 n-4 12 4 n-5 67 5 n-6 25 ---------------------- name score 0 n-2 80 1 n-4 100 2 n-6 75
二、添加/删除一行(或一列)
还是这个excel文件:
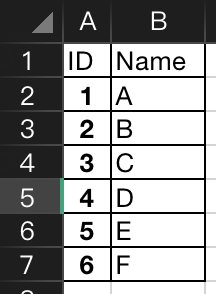
2.1 添加一行
import pandas as pd
df = pd.read_excel("data/002.xlsx", index_col="ID")
print(df)
print("----------")
# 添加一行
df.loc[df.size + 1] = {"ID": 7, "Name": "H"}
print(df)
输出如下:
Name ID 1 A 2 B 3 C 4 D 5 E 6 F ---------- Name ID 1 A 2 B 3 C 4 D 5 E 6 F 7 H
2.2 添加一列
import pandas as pd
df = pd.read_excel("data/002.xlsx", index_col="ID")
print(df)
print("----------")
# 添加一列
df['Age'] = range(21, 27)
print(df)
输出:
Name ID 1 A 2 B 3 C 4 D 5 E 6 F ---------- Name Age ID 1 A 21 2 B 22 3 C 23 4 D 24 5 E 25 6 F 26
2.3 删除一行(或一列)
import pandas as pd
df = pd.read_excel("data/002.xlsx", index_col="ID")
print(df)
print("----------")
# 先添加一列
df['Age'] = range(21, 27)
print(df)
# 再删除一列
df.drop("Name", axis=1, inplace=True)
print("----------")
print(df)
# 按index值,再删除3行
df.drop([3, 4, 5], axis=0, inplace=True)
print("----------")
print(df)
输出:
Name
ID
1 A
2 B
3 C
4 D
5 E
6 F
----------
Name Age
ID
1 A 21
2 B 22
3 C 23
4 D 24
5 E 25
6 F 26
----------
Age
ID
1 21
2 22
3 23
4 24
5 25
6 26
----------
Age
ID
1 21
2 22
6 26
三、修改指定单元格
import pandas as pd
df = pd.read_excel("data/002.xlsx", index_col="ID")
print(df)
print("----------")
# 修改ID=1这行的Name值
df.loc[1]["Name"] = "test"
print(df)
输出:
Name
ID
1 A
2 B
3 C
4 D
5 E
6 F
----------
Name
ID
1 test
2 B
3 C
4 D
5 E
6 F
四、遍历所有单元格
import pandas as pd
df = pd.read_excel("data/002.xlsx", index_col="ID")
print(df)
print("----------")
# 遍历所有单元格
for idx, data in df.iterrows():
print("id:{}\tname:{}".format(idx, data["Name"]))
输出:
Name ID 1 A 2 B 3 C 4 D 5 E 6 F ---------- id:1 name:A id:2 name:B id:3 name:C id:4 name:D id:5 name:E id:6 name:F
五、过滤数据
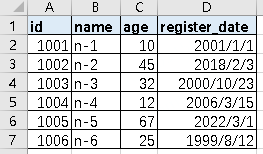
import pandas as pd
df = pd.read_excel("./data/test.xlsx", index_col="id")
print(df)
print("---------------")
# 过滤age>30的
df2 = df[df["age"] > 30]
print(df2)
print("---------------")
# 选[1,3)行,第[1,2)列,即:第2,3行,第2列
df2 = df.iloc[1:3, 1:2]
print(df2)
print("---------------")
# 选择id在(1002,1005)之间的数据
df2 = df.query('1002<id<1005')
print(df2)
输出:
name age register_date
id
1001 n-1 10 2001-01-01
1002 n-2 45 2018-02-03
1003 n-3 32 2000-10-23
1004 n-4 12 2006-03-15
1005 n-5 67 2022-03-01
1006 n-6 25 1999-08-12
---------------
name age register_date
id
1002 n-2 45 2018-02-03
1003 n-3 32 2000-10-23
1005 n-5 67 2022-03-01
---------------
age
id
1002 45
1003 32
---------------
name age register_date
id
1003 n-3 32 2000-10-23
1004 n-4 12 2006-03-15
六、保存excel
6.1 单sheet的excel写入
假如要将test.xlsx中id在1002到1005之间(不包含二端)的记录过滤出来,保存到另1个excel中,可以这样写:
import pandas as pd
pd \
.read_excel("./data/test.xlsx", index_col="id") \
.query('1002<id<1005') \
.to_excel("./data/output.xlsx")
6.2 多sheet的excel写入
import pandas as pd
df1 = pd.DataFrame({"ID": [10, 11, 12], "Name": ["A", "B", "C"]})
df1.set_index("ID", inplace=True)
df2 = pd.DataFrame({"ID": [11, 12, 13], "Score": [90, 80, 76]})
df2.set_index("ID", inplace=True)
writer = pd.ExcelWriter(r"./data/test.xlsx")
df1.to_excel(writer, sheet_name="sheet1")
df2.to_excel(writer, sheet_name="sheet2")
writer.save()
print("done")
效果:
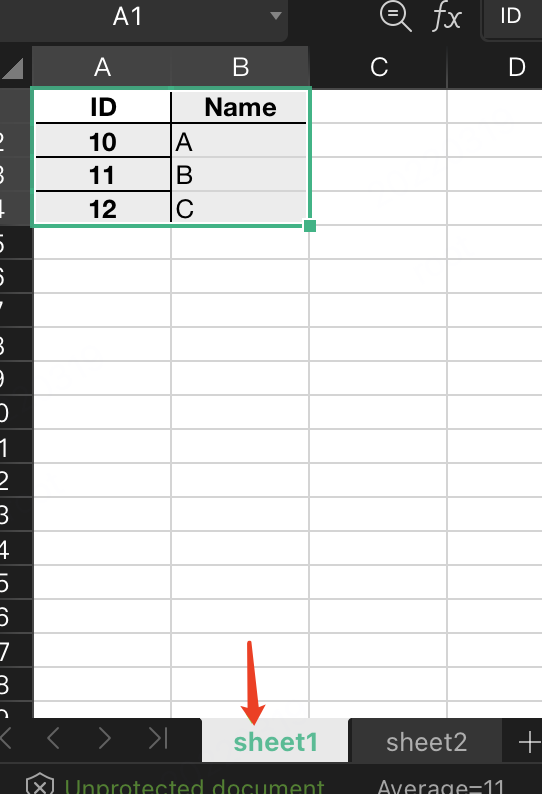

参考链接:
https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials/index.html